 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuideDog: A Real-World Egocentric Multimodal Dataset for Blind and Low-Vision Accessibility-Aware Guidance
Mar 17, 2025Mobility remains a significant challenge for the 2.2 billion people worldwide affected by blindness and low vision (BLV), with 7% of visually impaired individuals experiencing falls at least once a month. While recent advances in Multimodal Large Language Models (MLLMs) offer promising opportunities for BLV assistance, their development has been hindered by limited datasets. This limitation stems from the fact that BLV-aware annotation requires specialized domain knowledge and intensive labor. To address this gap, we introduce GuideDog, a novel accessibility-aware guide dataset containing 22K image-description pairs (including 2K human-annotated pairs) that capture diverse real-world scenes from a pedestrian's viewpoint. Our approach shifts the annotation burden from generation to verification through a collaborative human-AI framework grounded in established accessibility standards, significantly improving efficiency while maintaining high-quality annotations. We also develop GuideDogQA, a subset of 818 samples featuring multiple-choice questions designed to evaluate fine-grained visual perception capabilities, specifically object recognition and relative depth perception. Our experimental results highlight the importance of accurate spatial understanding for effective BLV guidance. GuideDog and GuideDogQA will advance research in MLLM-based assistive technologies for BLV individuals while contributing to broader applications in understanding egocentric scenes for robotics and augmented reality. The code and dataset will be publicly available.
A Read-Write Memory Network for Movie Story Understanding
Mar 16, 2018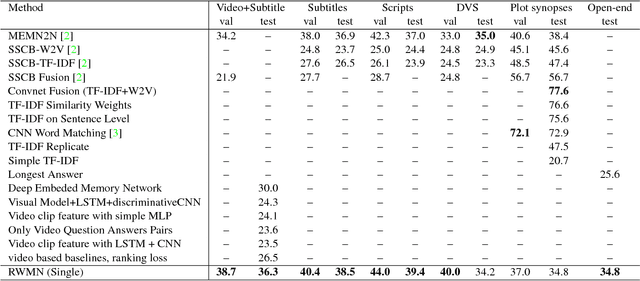

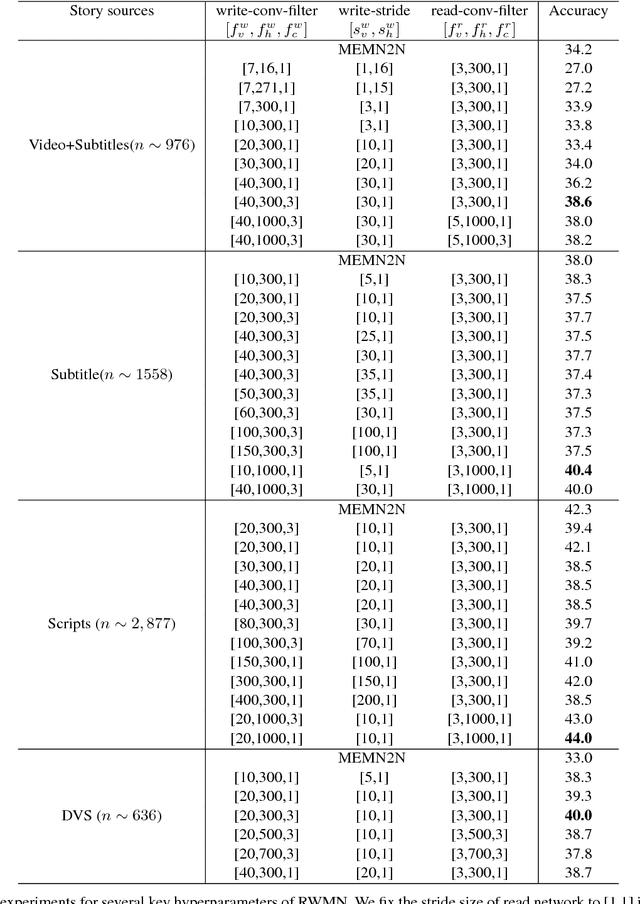

We propose a novel memory network model named Read-Write Memory Network (RWMN) to perform question and answering tasks for large-scale, multimodal movie story understanding. The key focus of our RWMN model is to design the read network and the write network that consist of multiple convolutional layers, which enable memory read and write operations to have high capacity and flexibility. While existing memory-augmented network models treat each memory slot as an independent block, our use of multi-layered CNNs allows the model to read and write sequential memory cells as chunks, which is more reasonable to represent a sequential story because adjacent memory blocks often have strong correlations. For evaluation, we apply our model to all the six tasks of the MovieQA benchmark, and achieve the best accuracies on several tasks, especially on the visual QA task. Our model shows a potential to better understand not only the content in the story, but also more abstract information, such as relationships between characters and the reasons for their actions.
Encoding Video and Label Priors for Multi-label Video Classification on YouTube-8M dataset
Jul 12, 2017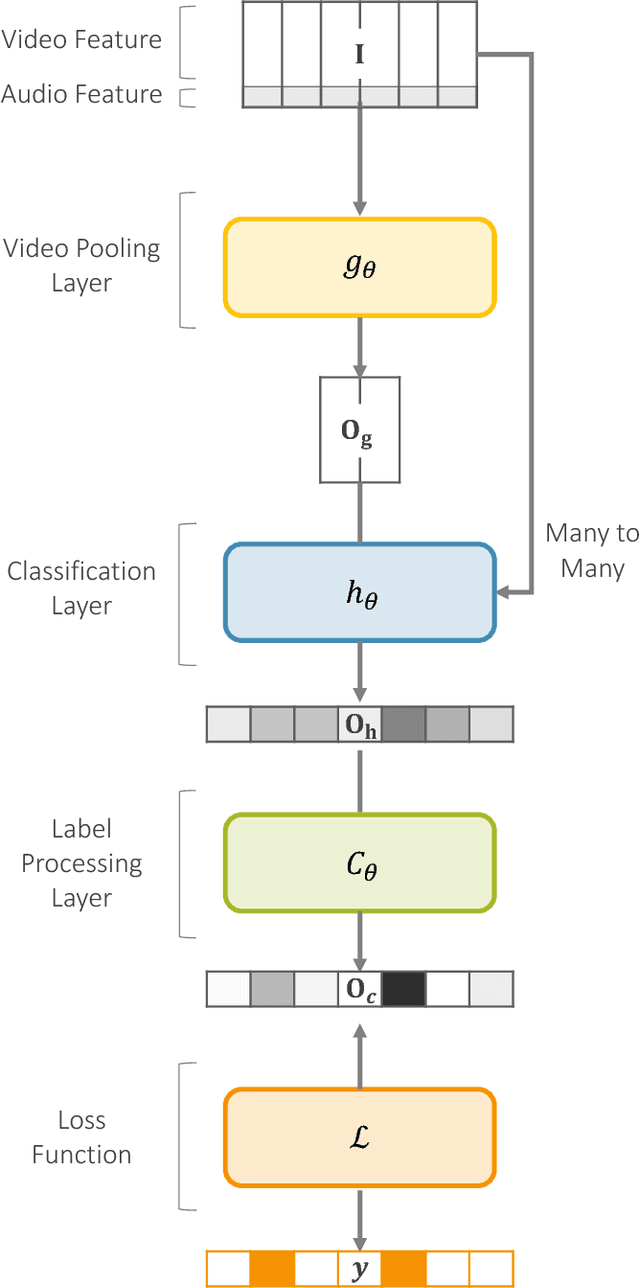
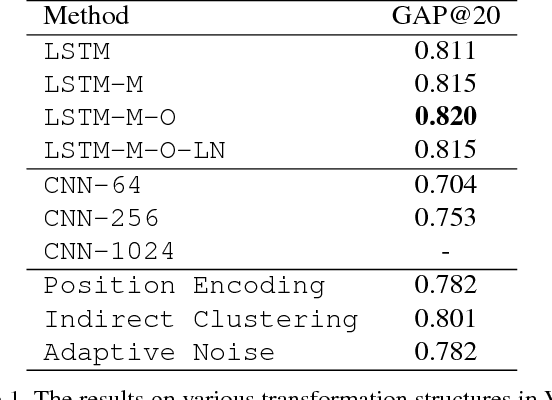
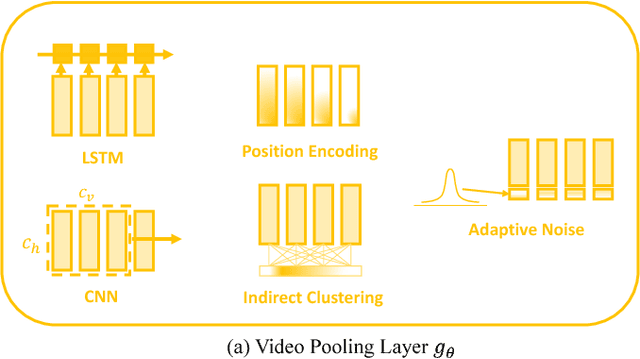

YouTube-8M is the largest video dataset for multi-label video classification. In order to tackle the multi-label classification on this challenging dataset, it is necessary to solve several issues such as temporal modeling of videos, label imbalances, and correlations between labels. We develop a deep neural network model, which consists of four components: the frame encoder, the classification layer, the label processing layer, and the loss function. We introduce our newly proposed methods and discusses how existing models operate in the YouTube-8M Classification Task, what insights they have, and why they succeed (or fail) to achieve good performance. Most of the models we proposed are very high compared to the baseline models, and the ensemble of the models we used is 8th in the Kaggle Competition.