 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Visual Context by Comparison
Jul 15, 2020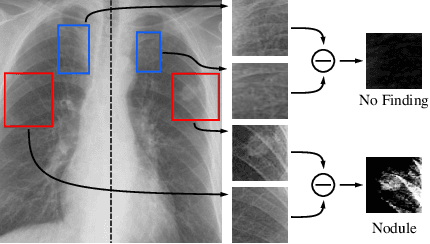

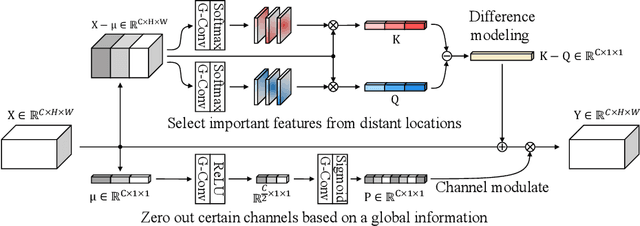
Finding diseases from an X-ray image is an important yet highly challenging task. Current methods for solving this task exploit various characteristics of the chest X-ray image, but one of the most important characteristics is still missing: the necessity of comparison between related regions in an image. In this paper, we present Attend-and-Compare Module (ACM) for capturing the difference between an object of interest and its corresponding context. We show that explicit difference modeling can be very helpful in tasks that require direct comparison between locations from afar. This module can be plugged into existing deep learning models. For evaluation, we apply our module to three chest X-ray recognition tasks and COCO object detection & segmentation tasks and observe consistent improvements across tasks. The code is available at https://github.com/mk-minchul/attend-and-compare.
Discovery of Natural Language Concepts in Individual Units of CNNs
Feb 28, 2019
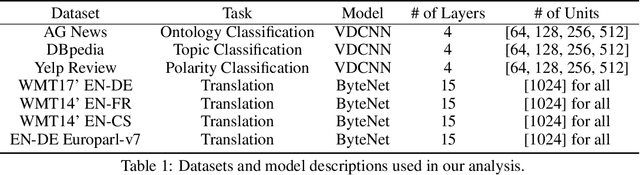

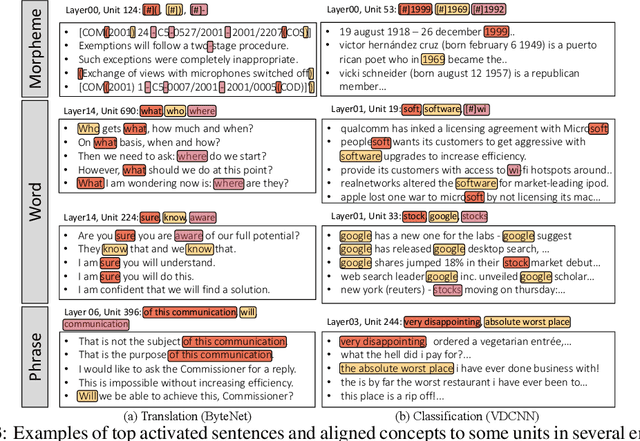
Although deep convolutional networks have achieved improved performance in many natural language tasks, they have been treated as black boxes because they are difficult to interpret. Especially, little is known about how they represent language in their intermediate layers. In an attempt to understand the representations of deep convolutional networks trained on language tasks, we show that individual units are selectively responsive to specific morphemes, words, and phrases, rather than responding to arbitrary and uninterpretable patterns. In order to quantitatively analyze such an intriguing phenomenon, we propose a concept alignment method based on how units respond to the replicated text. We conduct analyses with different architectures on multiple datasets for classification and translation tasks and provide new insights into how deep models understand natural language.
A Read-Write Memory Network for Movie Story Understanding
Mar 16, 2018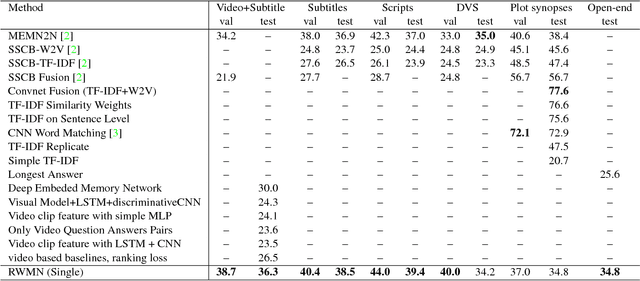

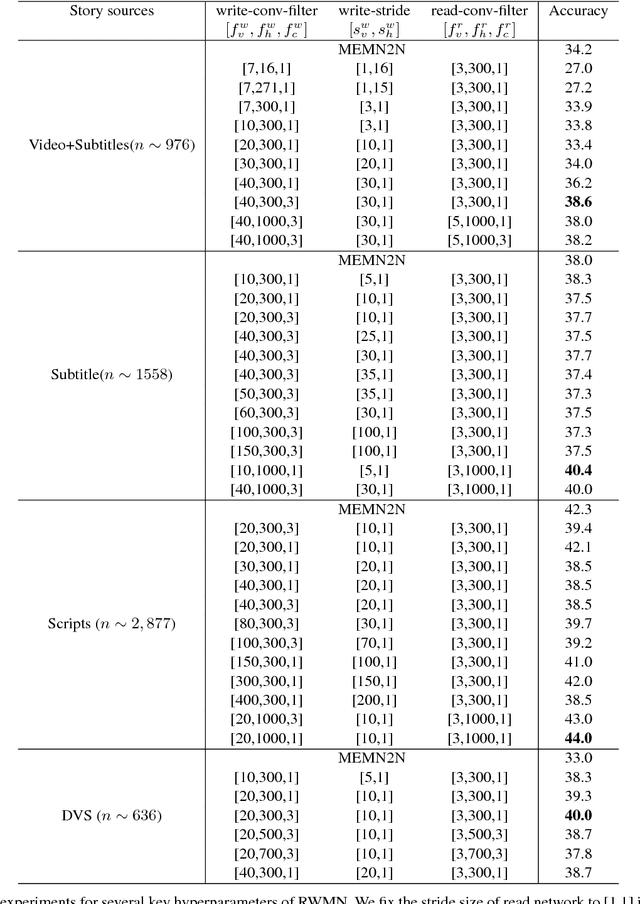

We propose a novel memory network model named Read-Write Memory Network (RWMN) to perform question and answering tasks for large-scale, multimodal movie story understanding. The key focus of our RWMN model is to design the read network and the write network that consist of multiple convolutional layers, which enable memory read and write operations to have high capacity and flexibility. While existing memory-augmented network models treat each memory slot as an independent block, our use of multi-layered CNNs allows the model to read and write sequential memory cells as chunks, which is more reasonable to represent a sequential story because adjacent memory blocks often have strong correlations. For evaluation, we apply our model to all the six tasks of the MovieQA benchmark, and achieve the best accuracies on several tasks, especially on the visual QA task. Our model shows a potential to better understand not only the content in the story, but also more abstract information, such as relationships between characters and the reasons for their actions.
Encoding Video and Label Priors for Multi-label Video Classification on YouTube-8M dataset
Jul 12, 2017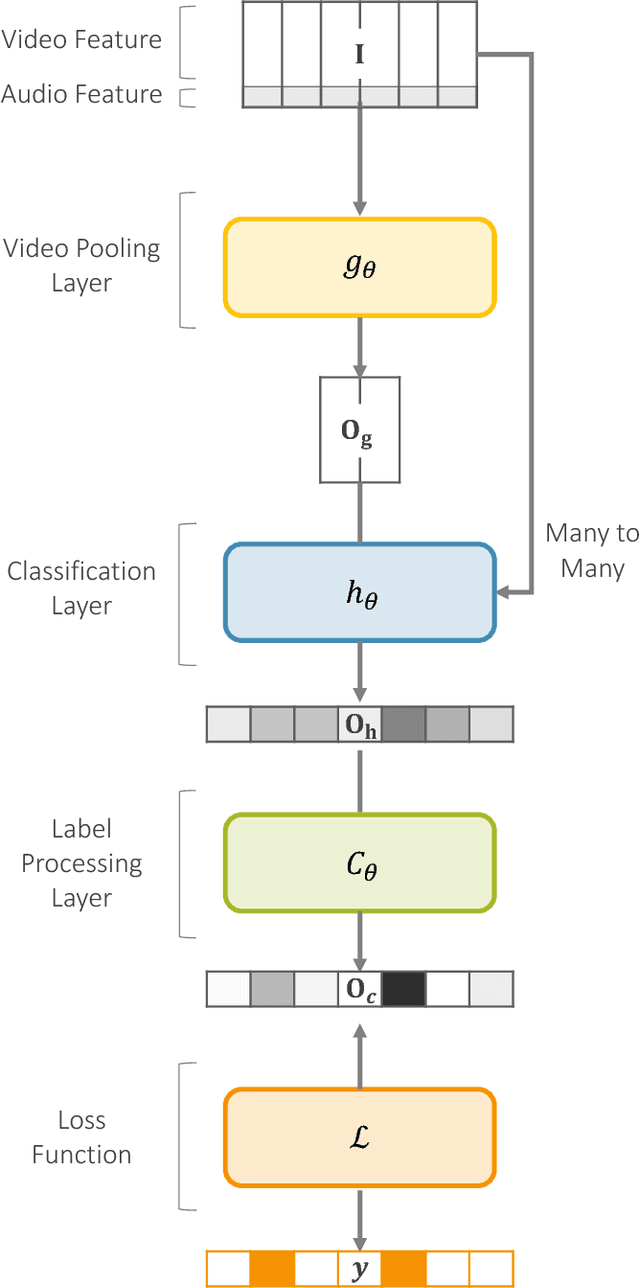
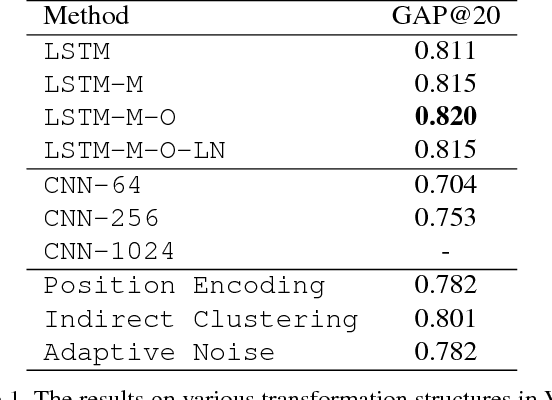
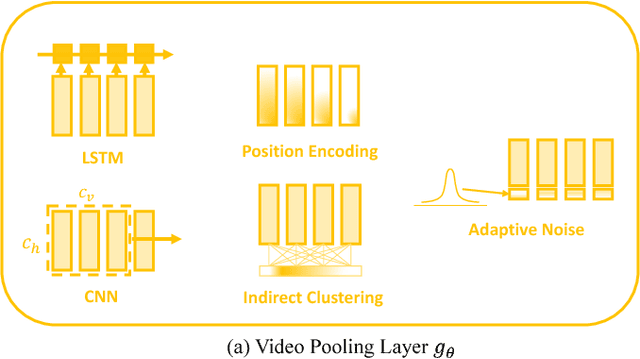

YouTube-8M is the largest video dataset for multi-label video classification. In order to tackle the multi-label classification on this challenging dataset, it is necessary to solve several issues such as temporal modeling of videos, label imbalances, and correlations between labels. We develop a deep neural network model, which consists of four components: the frame encoder, the classification layer, the label processing layer, and the loss function. We introduce our newly proposed methods and discusses how existing models operate in the YouTube-8M Classification Task, what insights they have, and why they succeed (or fail) to achieve good performance. Most of the models we proposed are very high compared to the baseline models, and the ensemble of the models we used is 8th in the Kaggle Competition.