 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Information Geometry of Softmax: Probing and Steering
Feb 17, 2026This paper concerns the question of how AI systems encode semantic structure into the geometric structure of their representation spaces. The motivating observation of this paper is that the natural geometry of these representation spaces should reflect the way models use representations to produce behavior. We focus on the important special case of representations that define softmax distributions. In this case, we argue that the natural geometry is information geometry. Our focus is on the role of information geometry on semantic encoding and the linear representation hypothesis. As an illustrative application, we develop "dual steering", a method for robustly steering representations to exhibit a particular concept using linear probes. We prove that dual steering optimally modifies the target concept while minimizing changes to off-target concepts. Empirically, we find that dual steering enhances the controllability and stability of concept manipulation.
The Geometry of Categorical and Hierarchical Concepts in Large Language Models
Jun 03, 2024Understanding how semantic meaning is encoded in the representation spaces of large language models is a fundamental problem in interpretability. In this paper, we study the two foundational questions in this area. First, how are categorical concepts, such as {'mammal', 'bird', 'reptile', 'fish'}, represented? Second, how are hierarchical relations between concepts encoded? For example, how is the fact that 'dog' is a kind of 'mammal' encoded? We show how to extend the linear representation hypothesis to answer these questions. We find a remarkably simple structure: simple categorical concepts are represented as simplices, hierarchically related concepts are orthogonal in a sense we make precise, and (in consequence) complex concepts are represented as polytopes constructed from direct sums of simplices, reflecting the hierarchical structure. We validate these theoretical results on the Gemma large language model, estimating representations for 957 hierarchically related concepts using data from WordNet.
Combining Evidence Across Filtrations
Feb 15, 2024



In anytime-valid sequential inference, it is known that any admissible inference procedure must be based on test martingales and their composite generalization, called e-processes, which are nonnegative processes whose expectation at any arbitrary stopping time is upper-bounded by one. An e-process quantifies the accumulated evidence against a composite null hypothesis over a sequence of outcomes. This paper studies methods for combining e-processes that are computed using different information sets, i.e., filtrations, for a null hypothesis. Even though e-processes constructed on the same filtration can be combined effortlessly (e.g., by averaging), e-processes constructed on different filtrations cannot be combined as easily because their validity in a coarser filtration does not translate to validity in a finer filtration. We discuss three concrete examples of such e-processes in the literature: exchangeability tests, independence tests, and tests for evaluating and comparing forecasts with lags. Our main result establishes that these e-processes can be lifted into any finer filtration using adjusters, which are functions that allow betting on the running maximum of the accumulated wealth (thereby insuring against the loss of evidence). We also develop randomized adjusters that can improve the power of the resulting sequential inference procedure.
The Linear Representation Hypothesis and the Geometry of Large Language Models
Nov 07, 2023Informally, the 'linear representation hypothesis' is the idea that high-level concepts are represented linearly as directions in some representation space. In this paper, we address two closely related questions: What does "linear representation" actually mean? And, how do we make sense of geometric notions (e.g., cosine similarity or projection) in the representation space? To answer these, we use the language of counterfactuals to give two formalizations of "linear representation", one in the output (word) representation space, and one in the input (sentence) space. We then prove these connect to linear probing and model steering, respectively. To make sense of geometric notions, we use the formalization to identify a particular (non-Euclidean) inner product that respects language structure in a sense we make precise. Using this causal inner product, we show how to unify all notions of linear representation. In particular, this allows the construction of probes and steering vectors using counterfactual pairs. Experiments with LLaMA-2 demonstrate the existence of linear representations of concepts, the connection to interpretation and control, and the fundamental role of the choice of inner product.
Counterfactually Comparing Abstaining Classifiers
May 17, 2023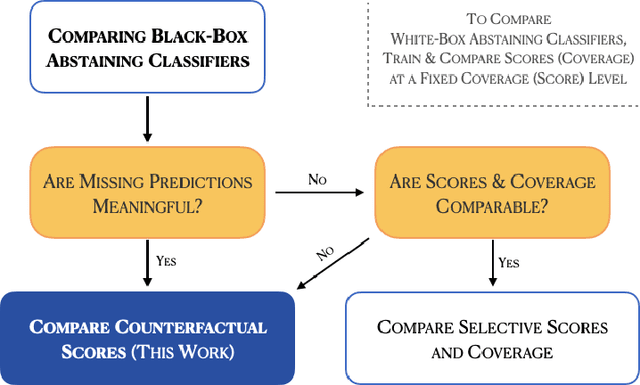



Abstaining classifiers have the option to abstain from making predictions on inputs that they are unsure about. These classifiers are becoming increasingly popular in high-stake decision-making problems, as they can withhold uncertain predictions to improve their reliability and safety. When evaluating black-box abstaining classifier(s), however, we lack a principled approach that accounts for what the classifier would have predicted on its abstentions. These missing predictions are crucial when, e.g., a radiologist is unsure of their diagnosis or when a driver is inattentive in a self-driving car. In this paper, we introduce a novel approach and perspective to the problem of evaluating and comparing abstaining classifiers by treating abstentions as missing data. Our evaluation approach is centered around defining the counterfactual score of an abstaining classifier, defined as the expected performance of the classifier had it not been allowed to abstain. We specify the conditions under which the counterfactual score is identifiable: if the abstentions are stochastic, and if the evaluation data is independent of the training data (ensuring that the predictions are missing at random), then the score is identifiable. Note that, if abstentions are deterministic, then the score is unidentifiable because the classifier can perform arbitrarily poorly on its abstentions. Leveraging tools from observational causal inference, we then develop nonparametric and doubly robust methods to efficiently estimate this quantity under identification. Our approach is examined in both simulated and real data experiments.
Comparing Sequential Forecasters
Sep 30, 2021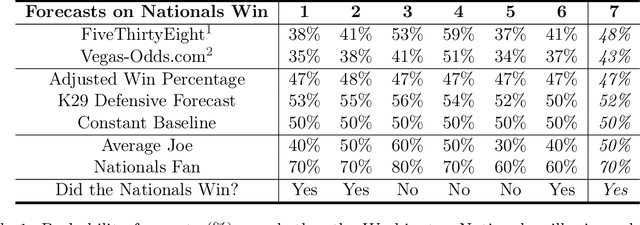

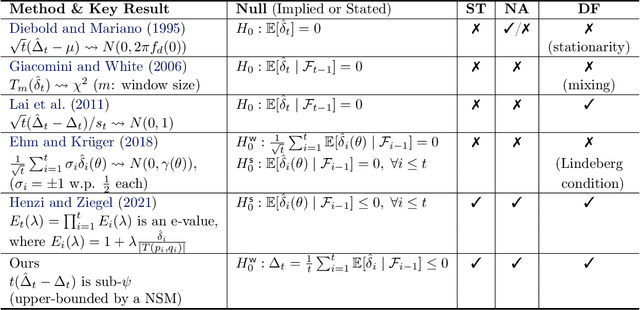
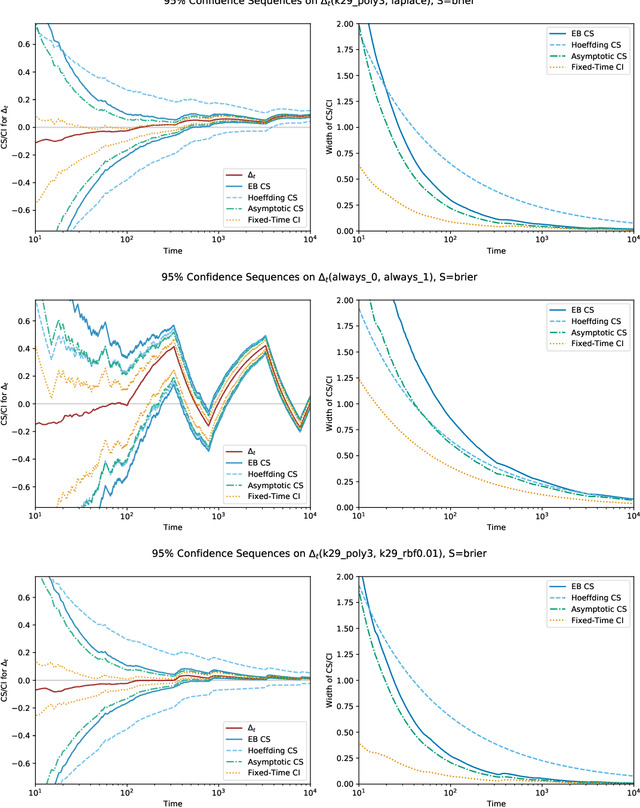
We consider two or more forecasters each making a sequence of predictions over time and tackle the problem of how to compare them -- either online or post-hoc. In fields ranging from meteorology to sports, forecasters make predictions on different events or quantities over time, and this work describes how to compare them in a statistically rigorous manner. Specifically, we design a nonasymptotic sequential inference procedure for estimating the time-varying difference in forecast quality when using a relatively large class of scoring rules (bounded scores with a linear equivalent). The resulting confidence intervals can be continuously monitored and yield statistically valid comparisons at arbitrary data-dependent stopping times ("anytime-valid"); this is enabled by adapting recent variance-adaptive confidence sequences (CS) to our setting. In the spirit of Shafer and Vovk's game-theoretic probability, the coverage guarantees for our CSs are also distribution-free, in the sense that they make no distributional assumptions whatsoever on the forecasts or outcomes. Additionally, in contrast to a recent preprint by Henzi and Ziegel, we show how to sequentially test a weak null hypothesis about whether one forecaster outperforms another on average over time, by designing different e-processes that quantify the evidence at any stopping time. We examine the validity of our methods over their fixed-time and asymptotic counterparts in synthetic experiments and demonstrate their effectiveness in real-data settings, including comparing probability forecasts on Major League Baseball (MLB) games and comparing statistical postprocessing methods for ensemble weather forecasts.
An Empirical Study of Invariant Risk Minimization
Apr 10, 2020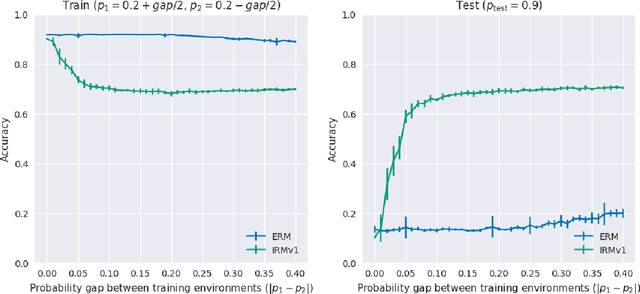
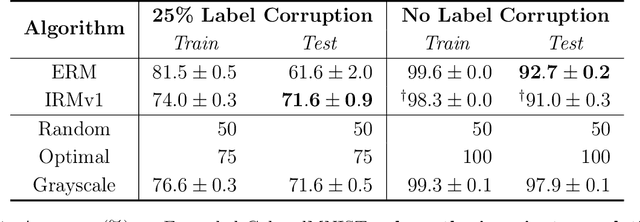
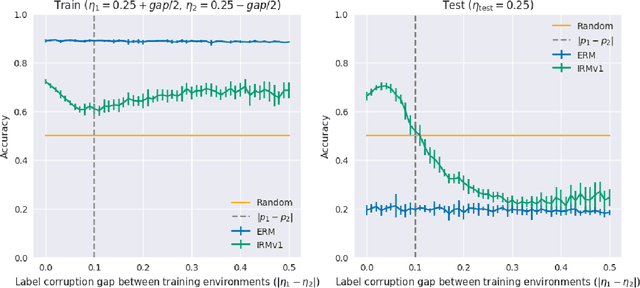

Invariant risk minimization (IRM; Arjovsky et al., 2019) is a recently proposed framework designed for learning predictors that are invariant to spurious correlations across different training environments. Because IRM does not assume that the test data is identically distributed as the training data, it can allow models to learn invariances that generalize well on unseen and out-of-distribution (OOD) samples. Yet, despite this theoretical justification, IRM has not been extensively tested across various settings. In an attempt to gain a better understanding of IRM, we empirically investigate several research questions using IRMv1, which is the first practical algorithm proposed in (Arjovsky et al., 2019) to approximately solve IRM. By extending the ColoredMNIST experiment from (Arjovsky et al., 2019) in multiple ways, we find that IRMv1 (i) performs better as the spurious correlation varies more widely between training environments, (ii) learns an approximately invariant predictor when the underlying relationship is approximately invariant, and (iii) can be extended to multiple environments, multiple outcomes, and different modalities (i.e., text). We hope that this work will shed light on the characteristics of IRM and help with applying IRM to real-world OOD generalization tasks.
KorNLI and KorSTS: New Benchmark Datasets for Korean Natural Language Understanding
Apr 08, 2020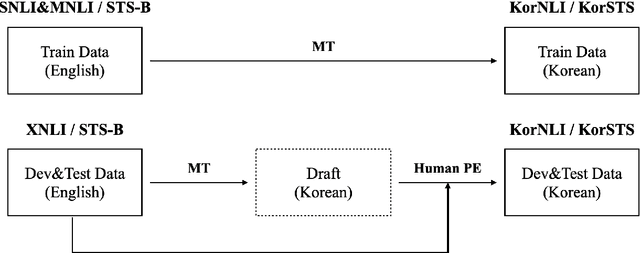
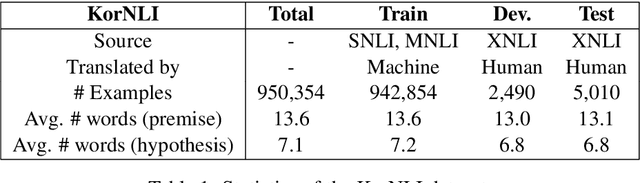
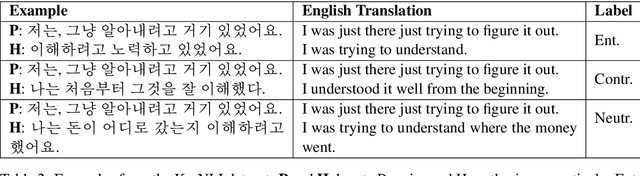
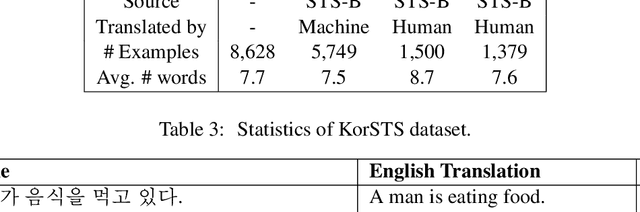
Natural language inference (NLI) and semantic textual similarity (STS) are key tasks in natural language understanding (NLU). Although several benchmark datasets for those tasks have been released in English and a few other languages, there are no publicly available NLI or STS datasets in the Korean language. Motivated by this, we construct and release new datasets for Korean NLI and STS, dubbed KorNLI and KorSTS, respectively. Following previous approaches, we machine-translate existing English training sets and manually translate development and test sets into Korean. To accelerate research on Korean NLU, we also establish baselines on KorNLI and KorSTS. Our datasets are made publicly available via our GitHub repository.
Jejueo Datasets for Machine Translation and Speech Synthesis
Nov 27, 2019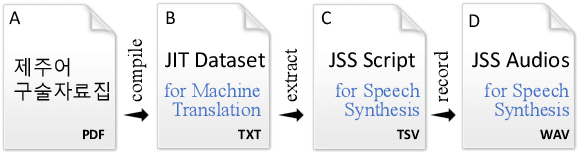
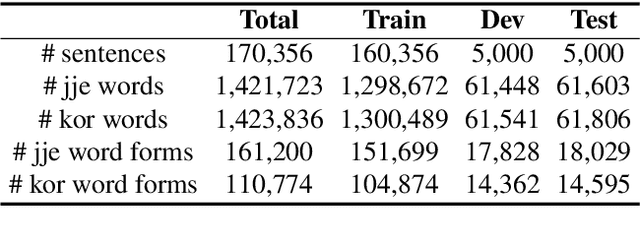
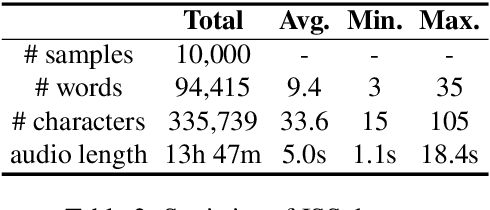
Jejueo was classified as critically endangered by UNESCO in 2010. Although diverse efforts to revitalize it have been made, there have been few computational approaches. Motivated by this, we construct two new Jejueo datasets: Jejueo Interview Transcripts (JIT) and Jejueo Single Speaker Speech (JSS). The JIT dataset is a parallel corpus containing 170k+ Jejueo-Korean sentences, and the JSS dataset consists of 10k high-quality audio files recorded by a native Jejueo speaker and a transcript file. Subsequently, we build neural systems of machine translation and speech synthesis using them. All resources are publicly available via our GitHub repository. We hope that these datasets will attract interest of both language and machine learning communities.
word2word: A Collection of Bilingual Lexicons for 3,564 Language Pairs
Nov 27, 2019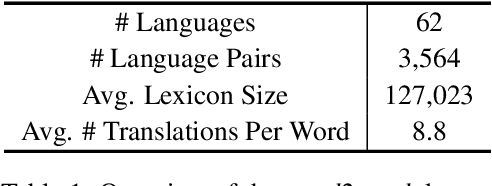
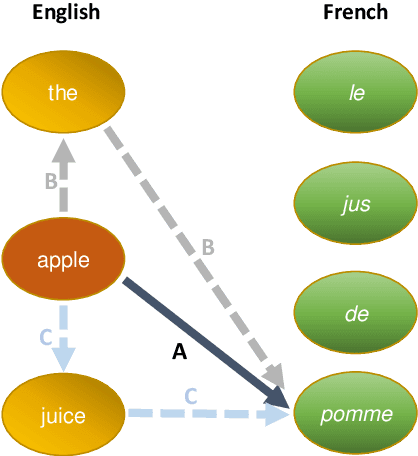
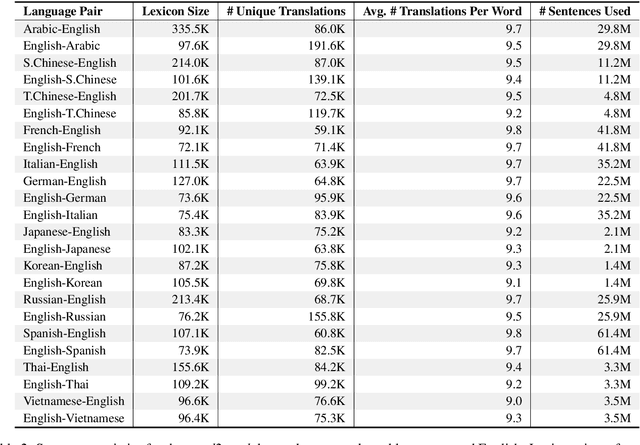

We present word2word, a publicly available dataset and an open-source Python package for cross-lingual word translations extracted from sentence-level parallel corpora. Our dataset provides top-k word translations in 3,564 (directed) language pairs across 62 languages in OpenSubtitles2018 (Lison et al., 2018). To obtain this dataset, we use a count-based bilingual lexicon extraction model based on the observation that not only source and target words but also source words themselves can be highly correlated. We illustrate that the resulting bilingual lexicons have high coverage and attain competitive translation quality for several language pairs. We wrap our dataset and model in an easy-to-use Python library, which supports downloading and retrieving top-k word translations in any of the supported language pairs as well as computing top-k word translations for custom parallel corpora.