 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPCGRL: Language-Instructed Reinforcement Learning for Procedural Level Generation
Mar 16, 2025Recent research has highlighted the significance of natural language in enhancing the controllability of generative models. While various efforts have been made to leverage natural language for content generation, research on deep reinforcement learning (DRL) agents utilizing text-based instructions for procedural content generation remains limited. In this paper, we propose IPCGRL, an instruction-based procedural content generation method via reinforcement learning, which incorporates a sentence embedding model. IPCGRL fine-tunes task-specific embedding representations to effectively compress game-level conditions. We evaluate IPCGRL in a two-dimensional level generation task and compare its performance with a general-purpose embedding method. The results indicate that IPCGRL achieves up to a 21.4% improvement in controllability and a 17.2% improvement in generalizability for unseen instructions. Furthermore, the proposed method extends the modality of conditional input, enabling a more flexible and expressive interaction framework for procedural content generation.
Discovery of Natural Language Concepts in Individual Units of CNNs
Feb 28, 2019

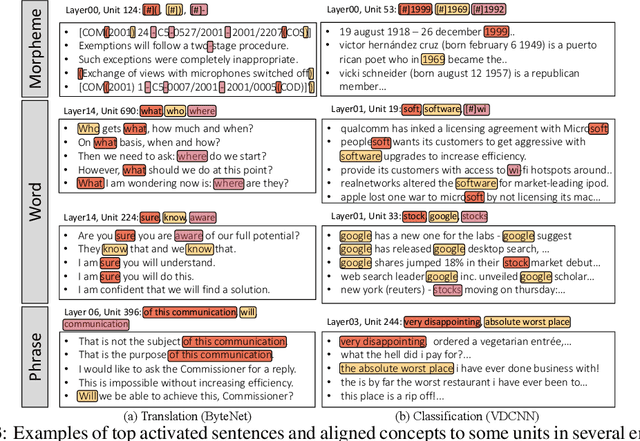
Although deep convolutional networks have achieved improved performance in many natural language tasks, they have been treated as black boxes because they are difficult to interpret. Especially, little is known about how they represent language in their intermediate layers. In an attempt to understand the representations of deep convolutional networks trained on language tasks, we show that individual units are selectively responsive to specific morphemes, words, and phrases, rather than responding to arbitrary and uninterpretable patterns. In order to quantitatively analyze such an intriguing phenomenon, we propose a concept alignment method based on how units respond to the replicated text. We conduct analyses with different architectures on multiple datasets for classification and translation tasks and provide new insights into how deep models understand natural language.
Cascading Denoising Auto-Encoder as a Deep Directed Generative Model
Jan 27, 2017Recent work (Bengio et al., 2013) has shown howDenoising Auto-Encoders(DAE) become gener-ative models as a density estimator. However,in practice, the framework suffers from a mixingproblem in the MCMC sampling process and nodirect method to estimate the test log-likelihood.We consider a directed model with an stochas-tic identity mapping (simple corruption pro-cess) as an inference model and a DAE as agenerative model. By cascading these mod-els, we propose Cascading Denoising Auto-Encoders(CDAE) which can generate samples ofdata distribution from tractable prior distributionunder the assumption that probabilistic distribu-tion of corrupted data approaches tractable priordistribution as the level of corruption increases.This work tries to answer two questions. On theone hand, can deep directed models be success-fully trained without intractable posterior infer-ence and difficult optimization of very deep neu-ral networks in inference and generative mod-els? These are unavoidable when recent suc-cessful directed model like VAE (Kingma &Welling, 2014) is trained on complex dataset likereal images. On the other hand, can DAEs getclean samples of data distribution from heavilycorrupted samples which can be considered oftractable prior distribution far from data mani-fold? so-called global denoising scheme.Our results show positive responses of thesequestions and this work can provide fairly simpleframework for generative models of very com-plex dataset.
Towards Biologically Plausible Deep Learning
Aug 09, 2016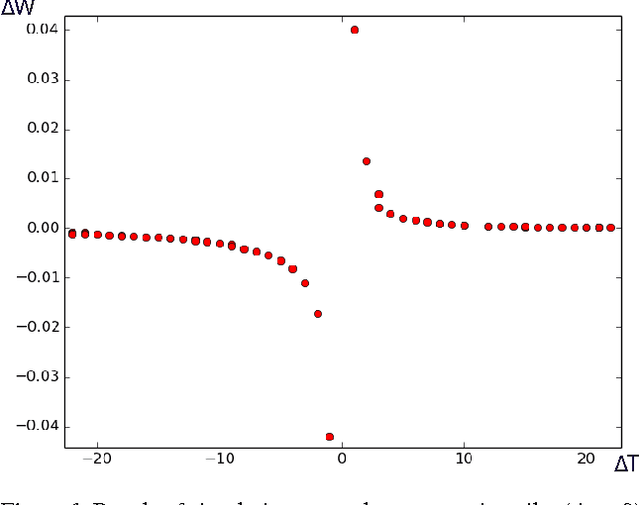

Neuroscientists have long criticised deep learning algorithms as incompatible with current knowledge of neurobiology. We explore more biologically plausible versions of deep representation learning, focusing here mostly on unsupervised learning but developing a learning mechanism that could account for supervised, unsupervised and reinforcement learning. The starting point is that the basic learning rule believed to govern synaptic weight updates (Spike-Timing-Dependent Plasticity) arises out of a simple update rule that makes a lot of sense from a machine learning point of view and can be interpreted as gradient descent on some objective function so long as the neuronal dynamics push firing rates towards better values of the objective function (be it supervised, unsupervised, or reward-driven). The second main idea is that this corresponds to a form of the variational EM algorithm, i.e., with approximate rather than exact posteriors, implemented by neural dynamics. Another contribution of this paper is that the gradients required for updating the hidden states in the above variational interpretation can be estimated using an approximation that only requires propagating activations forward and backward, with pairs of layers learning to form a denoising auto-encoder. Finally, we extend the theory about the probabilistic interpretation of auto-encoders to justify improved sampling schemes based on the generative interpretation of denoising auto-encoders, and we validate all these ideas on generative learning tasks.
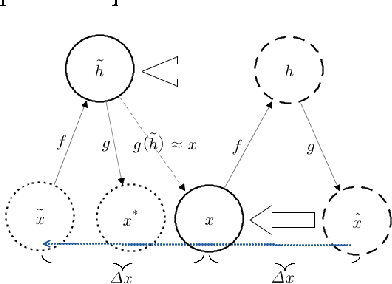
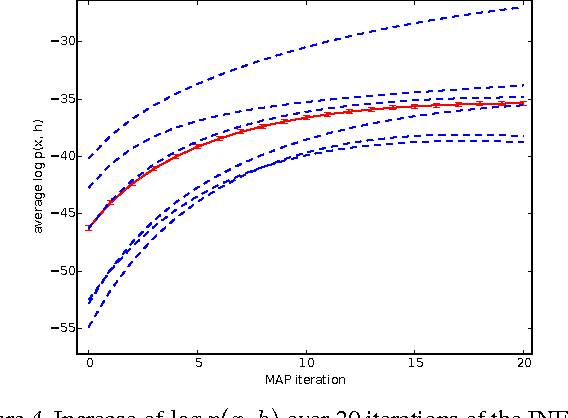
Difference Target Propagation
Nov 25, 2015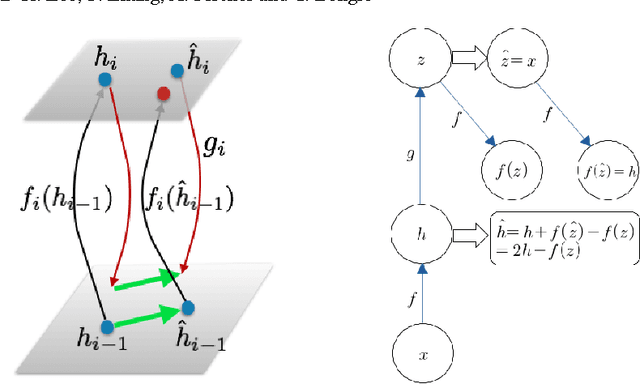

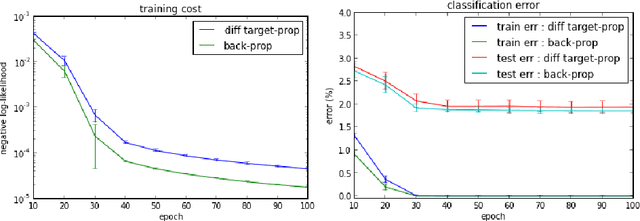
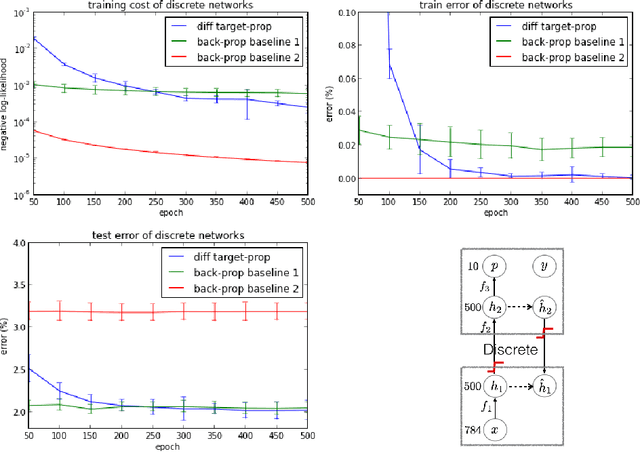
Back-propagation has been the workhorse of recent successes of deep learning but it relies on infinitesimal effects (partial derivatives) in order to perform credit assignment. This could become a serious issue as one considers deeper and more non-linear functions, e.g., consider the extreme case of nonlinearity where the relation between parameters and cost is actually discrete. Inspired by the biological implausibility of back-propagation, a few approaches have been proposed in the past that could play a similar credit assignment role. In this spirit, we explore a novel approach to credit assignment in deep networks that we call target propagation. The main idea is to compute targets rather than gradients, at each layer. Like gradients, they are propagated backwards. In a way that is related but different from previously proposed proxies for back-propagation which rely on a backwards network with symmetric weights, target propagation relies on auto-encoders at each layer. Unlike back-propagation, it can be applied even when units exchange stochastic bits rather than real numbers. We show that a linear correction for the imperfectness of the auto-encoders, called difference target propagation, is very effective to make target propagation actually work, leading to results comparable to back-propagation for deep networks with discrete and continuous units and denoising auto-encoders and achieving state of the art for stochastic networks.
Challenges in Representation Learning: A report on three machine learning contests
Jul 01, 2013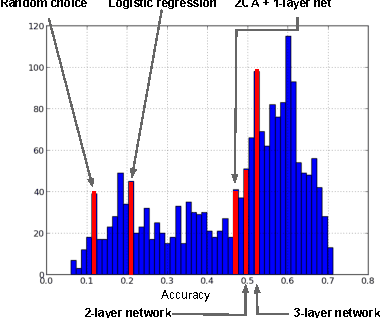

The ICML 2013 Workshop on Challenges in Representation Learning focused on three challenges: the black box learning challenge, the facial expression recognition challenge, and the multimodal learning challenge. We describe the datasets created for these challenges and summarize the results of the competitions. We provide suggestions for organizers of future challenges and some comments on what kind of knowledge can be gained from machine learning competitions.