 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIRE: Frobenius-Isometry Reinitialization for Balancing the Stability-Plasticity Tradeoff
Feb 08, 2026Deep neural networks trained on nonstationary data must balance stability (i.e., retaining prior knowledge) and plasticity (i.e., adapting to new tasks). Standard reinitialization methods, which reinitialize weights toward their original values, are widely used but difficult to tune: conservative reinitializations fail to restore plasticity, while aggressive ones erase useful knowledge. We propose FIRE, a principled reinitialization method that explicitly balances the stability-plasticity tradeoff. FIRE quantifies stability through Squared Frobenius Error (SFE), measuring proximity to past weights, and plasticity through Deviation from Isometry (DfI), reflecting weight isotropy. The reinitialization point is obtained by solving a constrained optimization problem, minimizing SFE subject to DfI being zero, which is efficiently approximated by Newton-Schulz iteration. FIRE is evaluated on continual visual learning (CIFAR-10 with ResNet-18), language modeling (OpenWebText with GPT-0.1B), and reinforcement learning (HumanoidBench with SAC and Atari games with DQN). Across all domains, FIRE consistently outperforms both naive training without intervention and standard reinitialization methods, demonstrating effective balancing of the stability-plasticity tradeoff.
Prism: Spectral Parameter Sharing for Multi-Agent Reinforcement Learning
Feb 06, 2026Parameter sharing is a key strategy in multi-agent reinforcement learning (MARL) for improving scalability, yet conventional fully shared architectures often collapse into homogeneous behaviors. Recent methods introduce diversity through clustering, pruning, or masking, but typically compromise resource efficiency. We propose Prism, a parameter sharing framework that induces inter-agent diversity by representing shared networks in the spectral domain via singular value decomposition (SVD). All agents share the singular vector directions while learning distinct spectral masks on singular values. This mechanism encourages inter-agent diversity and preserves scalability. Extensive experiments on both homogeneous (LBF, SMACv2) and heterogeneous (MaMuJoCo) benchmarks show that Prism achieves competitive performance with superior resource efficiency.
PREFAB: PREFerence-based Affective Modeling for Low-Budget Self-Annotation
Jan 21, 2026Self-annotation is the gold standard for collecting affective state labels in affective computing. Existing methods typically rely on full annotation, requiring users to continuously label affective states across entire sessions. While this process yields fine-grained data, it is time-consuming, cognitively demanding, and prone to fatigue and errors. To address these issues, we present PREFAB, a low-budget retrospective self-annotation method that targets affective inflection regions rather than full annotation. Grounded in the peak-end rule and ordinal representations of emotion, PREFAB employs a preference-learning model to detect relative affective changes, directing annotators to label only selected segments while interpolating the remainder of the stimulus. We further introduce a preview mechanism that provides brief contextual cues to assist annotation. We evaluate PREFAB through a technical performance study and a 25-participant user study. Results show that PREFAB outperforms baselines in modeling affective inflections while mitigating workload (and conditionally mitigating temporal burden). Importantly PREFAB improves annotator confidence without degrading annotation quality.
Alternating Approach-Putt Models for Multi-Stage Speech Enhancement
Aug 14, 2025



Speech enhancement using artificial neural networks aims to remove noise from noisy speech signals while preserving the speech content. However, speech enhancement networks often introduce distortions to the speech signal, referred to as artifacts, which can degrade audio quality. In this work, we propose a post-processing neural network designed to mitigate artifacts introduced by speech enhancement models. Inspired by the analogy of making a `Putt' after an `Approach' in golf, we name our model PuttNet. We demonstrate that alternating between a speech enhancement model and the proposed Putt model leads to improved speech quality, as measured by perceptual quality scores (PESQ), objective intelligibility (STOI), and background noise intrusiveness (CBAK) scores. Furthermore, we illustrate with graphical analysis why this alternating Approach outperforms repeated application of either model alone.
IPCGRL: Language-Instructed Reinforcement Learning for Procedural Level Generation
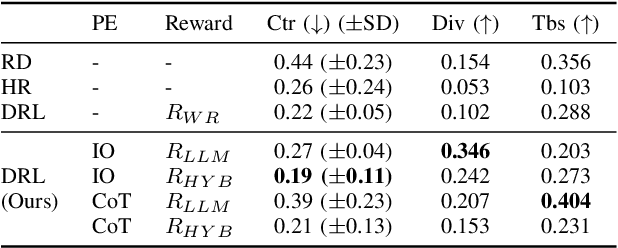
Mar 16, 2025Recent research has highlighted the significance of natural language in enhancing the controllability of generative models. While various efforts have been made to leverage natural language for content generation, research on deep reinforcement learning (DRL) agents utilizing text-based instructions for procedural content generation remains limited. In this paper, we propose IPCGRL, an instruction-based procedural content generation method via reinforcement learning, which incorporates a sentence embedding model. IPCGRL fine-tunes task-specific embedding representations to effectively compress game-level conditions. We evaluate IPCGRL in a two-dimensional level generation task and compare its performance with a general-purpose embedding method. The results indicate that IPCGRL achieves up to a 21.4% improvement in controllability and a 17.2% improvement in generalizability for unseen instructions. Furthermore, the proposed method extends the modality of conditional input, enabling a more flexible and expressive interaction framework for procedural content generation.
Automatic Curriculum Design for Zero-Shot Human-AI Coordination
Mar 10, 2025Zero-shot human-AI coordination is the training of an ego-agent to coordinate with humans without using human data. Most studies on zero-shot human-AI coordination have focused on enhancing the ego-agent's coordination ability in a given environment without considering the issue of generalization to unseen environments. Real-world applications of zero-shot human-AI coordination should consider unpredictable environmental changes and the varying coordination ability of co-players depending on the environment. Previously, the multi-agent UED (Unsupervised Environment Design) approach has investigated these challenges by jointly considering environmental changes and co-player policy in competitive two-player AI-AI scenarios. In this paper, our study extends the multi-agent UED approach to a zero-shot human-AI coordination. We propose a utility function and co-player sampling for a zero-shot human-AI coordination setting that helps train the ego-agent to coordinate with humans more effectively than the previous multi-agent UED approach. The zero-shot human-AI coordination performance was evaluated in the Overcooked-AI environment, using human proxy agents and real humans. Our method outperforms other baseline models and achieves a high human-AI coordination performance in unseen environments.
Activation by Interval-wise Dropout: A Simple Way to Prevent Neural Networks from Plasticity Loss
Feb 03, 2025Plasticity loss, a critical challenge in neural network training, limits a model's ability to adapt to new tasks or shifts in data distribution. This paper introduces AID (Activation by Interval-wise Dropout), a novel method inspired by Dropout, designed to address plasticity loss. Unlike Dropout, AID generates subnetworks by applying Dropout with different probabilities on each preactivation interval. Theoretical analysis reveals that AID regularizes the network, promoting behavior analogous to that of deep linear networks, which do not suffer from plasticity loss. We validate the effectiveness of AID in maintaining plasticity across various benchmarks, including continual learning tasks on standard image classification datasets such as CIFAR10, CIFAR100, and TinyImageNet. Furthermore, we show that AID enhances reinforcement learning performance in the Arcade Learning Environment benchmark.
ChatPCG: Large Language Model-Driven Reward Design for Procedural Content Generation
Jun 07, 2024
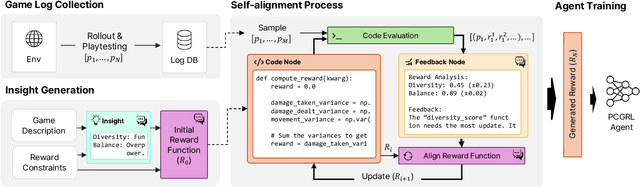
Driven by the rapid growth of machine learning, recent advances in game artificial intelligence (AI) have significantly impacted productivity across various gaming genres. Reward design plays a pivotal role in training game AI models, wherein researchers implement concepts of specific reward functions. However, despite the presence of AI, the reward design process predominantly remains in the domain of human experts, as it is heavily reliant on their creativity and engineering skills. Therefore, this paper proposes ChatPCG, a large language model (LLM)-driven reward design framework.It leverages human-level insights, coupled with game expertise, to generate rewards tailored to specific game features automatically. Moreover, ChatPCG is integrated with deep reinforcement learning, demonstrating its potential for multiplayer game content generation tasks. The results suggest that the proposed LLM exhibits the capability to comprehend game mechanics and content generation tasks, enabling tailored content generation for a specified game. This study not only highlights the potential for improving accessibility in content generation but also aims to streamline the game AI development process.
Discrete Prompt Compression with Reinforcement Learning
Aug 17, 2023
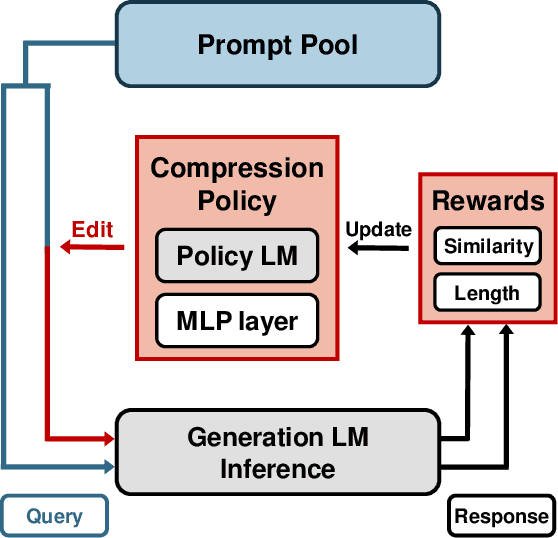
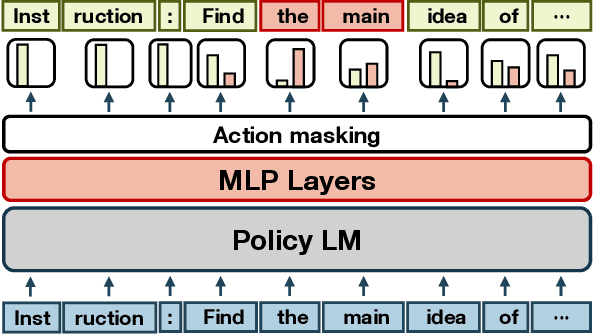
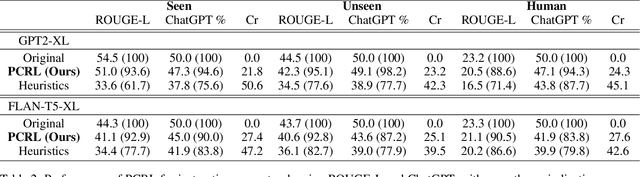
Instruction-tuned Language Models (LMs) are widely used by users to address various problems with task-specific prompts. Constraints associated with the context window length and computational costs encourage the development of compressed prompts. Existing methods rely heavily on training embeddings, which are designed to accommodate multiple token meanings. This presents challenges in terms of interpretability, a fixed number of embedding tokens, reusability across different LMs, and inapplicability when interacting with black-box APIs. This study proposes prompt compression with reinforcement learning (PCRL), a novel discrete prompt compression method that addresses these issues. PCRL employs a computationally efficient policy network that directly edits prompts. The PCRL training approach can be flexibly applied to various types of LMs, as well as decoder-only and encoder-decoder architecture, and can be trained without gradient access to LMs or labeled data. PCRL achieves an average reduction of 24.6% in token count across various instruction prompts while preserving performance. Further, we demonstrate that the learned policy can be transferred to larger LMs, and through various analyses, we aid the understanding of token importance within prompts.
RaidEnv: Exploring New Challenges in Automated Content Balancing for Boss Raid Games
Jul 04, 2023The balance of game content significantly impacts the gaming experience. Unbalanced game content diminishes engagement or increases frustration because of repetitive failure. Although game designers intend to adjust the difficulty of game content, this is a repetitive, labor-intensive, and challenging process, especially for commercial-level games with extensive content. To address this issue, the game research community has explored automated game balancing using artificial intelligence (AI) techniques. However, previous studies have focused on limited game content and did not consider the importance of the generalization ability of playtesting agents when encountering content changes. In this study, we propose RaidEnv, a new game simulator that includes diverse and customizable content for the boss raid scenario in MMORPG games. Additionally, we design two benchmarks for the boss raid scenario that can aid in the practical application of game AI. These benchmarks address two open problems in automatic content balancing, and we introduce two evaluation metrics to provide guidance for AI in automatic content balancing. This novel game research platform expands the frontiers of automatic game balancing problems and offers a framework within a realistic game production pipeline.