 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Prompt Compression with Reinforcement Learning
Paper and Code
Aug 17, 2023
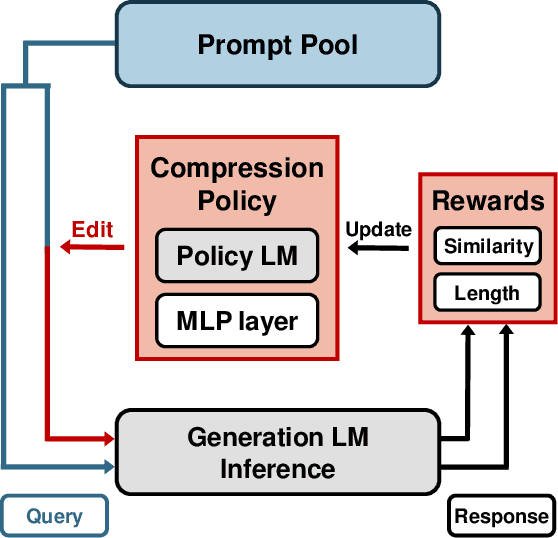
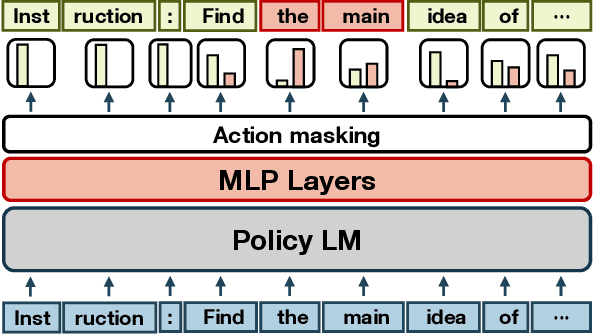
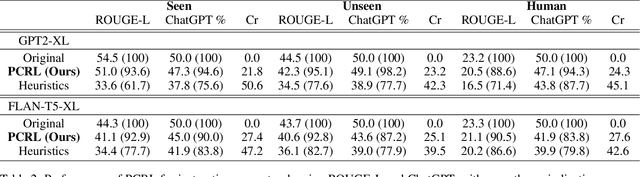
Instruction-tuned Language Models (LMs) are widely used by users to address various problems with task-specific prompts. Constraints associated with the context window length and computational costs encourage the development of compressed prompts. Existing methods rely heavily on training embeddings, which are designed to accommodate multiple token meanings. This presents challenges in terms of interpretability, a fixed number of embedding tokens, reusability across different LMs, and inapplicability when interacting with black-box APIs. This study proposes prompt compression with reinforcement learning (PCRL), a novel discrete prompt compression method that addresses these issues. PCRL employs a computationally efficient policy network that directly edits prompts. The PCRL training approach can be flexibly applied to various types of LMs, as well as decoder-only and encoder-decoder architecture, and can be trained without gradient access to LMs or labeled data. PCRL achieves an average reduction of 24.6% in token count across various instruction prompts while preserving performance. Further, we demonstrate that the learned policy can be transferred to larger LMs, and through various analyses, we aid the understanding of token importance within prompts.