 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPADE: Spectroscopic Photoacoustic Denoising using an Analytical and Data-free Enhancement Framework
Dec 16, 2024



Spectroscopic photoacoustic (sPA) imaging uses multiple wavelengths to differentiate chromophores based on their unique optical absorption spectra. This technique has been widely applied in areas such as vascular mapping, tumor detection, and therapeutic monitoring. However, sPA imaging is highly susceptible to noise, leading to poor signal-to-noise ratio (SNR) and compromised image quality. Traditional denoising techniques like frame averaging, though effective in improving SNR, can be impractical for dynamic imaging scenarios due to reduced frame rates. Advanced methods, including learning-based approaches and analytical algorithms, have demonstrated promise but often require extensive training data and parameter tuning, limiting their adaptability for real-time clinical use. In this work, we propose a sPA denoising using a tuning-free analytical and data-free enhancement (SPADE) framework for denoising sPA images. This framework integrates a data-free learning-based method with an efficient BM3D-based analytical approach while preserves spectral linearity, providing noise reduction and ensuring that functional information is maintained. The SPADE framework was validated through simulation, phantom, ex vivo, and in vivo experiments. Results demonstrated that SPADE improved SNR and preserved spectral information, outperforming conventional methods, especially in challenging imaging conditions. SPADE presents a promising solution for enhancing sPA imaging quality in clinical applications where noise reduction and spectral preservation are critical.
Actuated Reflector-Based Three-dimensional Ultrasound Imaging with Adaptive-Delay Synthetic Aperture Focusing
Dec 13, 2021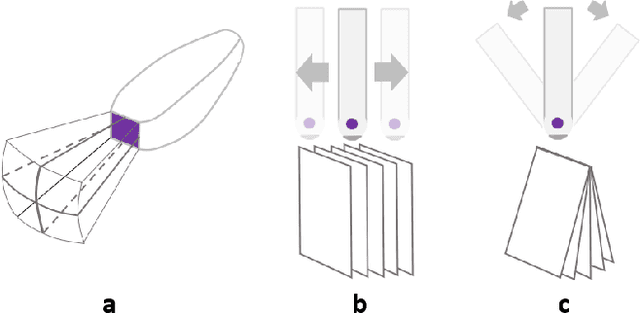

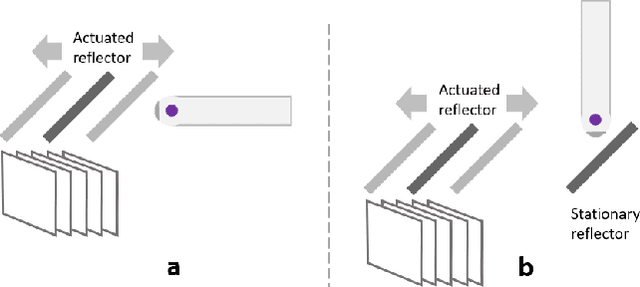
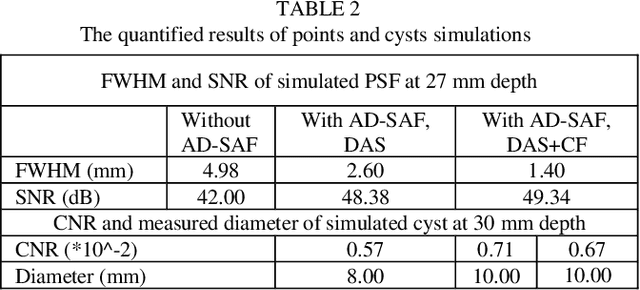
Three-dimensional (3D) ultrasound (US) imaging addresses the limitation in field-of-view (FOV) in conventional two-dimensional (2D) US imaging by providing 3D viewing of the anatomy. 3D US imaging has been extensively adapted for diagnosis and image-guided surgical intervention. However, conventional approaches to implement 3D US imaging require either expensive and sophisticated 2D array transducers, or external actuation mechanisms to move a one-dimensional array mechanically. Here, we propose a 3D US imaging mechanism using actuated acoustic reflector instead of the sensor elements for volume acquisition with significantly extended 3D FOV, which can be implemented with simple hardware and compact size. To improve image quality on the elevation plane, we introduce an adaptive-delay synthetic aperture focusing (AD-SAF) method for elevation beamforming. We first evaluated the proposed imaging mechanism and AD-SAF with simulated point targets and cysts targets. Results of point targets suggested improved image quality on the elevation plane, and results of cysts targets demonstrated a potential to improve 3D visualization of human anatomy. We built a prototype imaging system that has a 3D FOV of 38 mm (lateral) by 38 mm (elevation) by 50 mm (axial) and collected data in imaging experiments with phantoms. Experimental data showed consistency with simulation results. The AD-SAF method enhanced quantifying the cyst volume size in the breast mimicking phantom compared to without elevation beamforming. These results suggested that the proposed 3D US imaging mechanism could potentially be applied in clinical scenarios.
Learning Generative Models with Visual Attention
Feb 21, 2015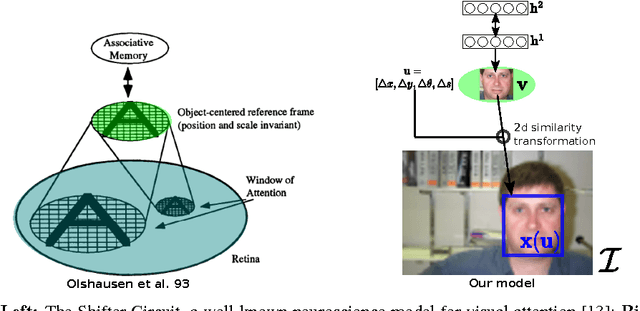

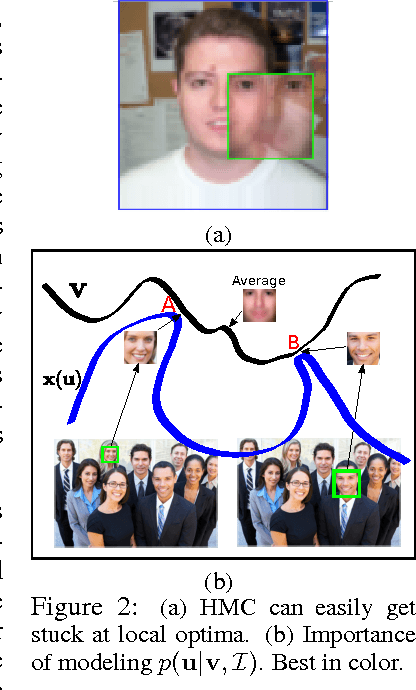
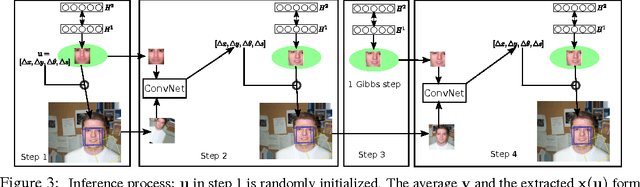
Attention has long been proposed by psychologists as important for effectively dealing with the enormous sensory stimulus available in the neocortex. Inspired by the visual attention models in computational neuroscience and the need of object-centric data for generative models, we describe for generative learning framework using attentional mechanisms. Attentional mechanisms can propagate signals from region of interest in a scene to an aligned canonical representation, where generative modeling takes place. By ignoring background clutter, generative models can concentrate their resources on the object of interest. Our model is a proper graphical model where the 2D Similarity transformation is a part of the top-down process. A ConvNet is employed to provide good initializations during posterior inference which is based on Hamiltonian Monte Carlo. Upon learning images of faces, our model can robustly attend to face regions of novel test subjects. More importantly, our model can learn generative models of new faces from a novel dataset of large images where the face locations are not known.
Deep Learning using Linear Support Vector Machines
Feb 21, 2015
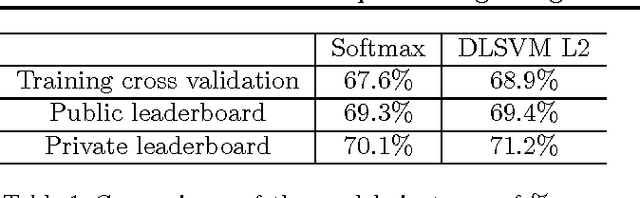
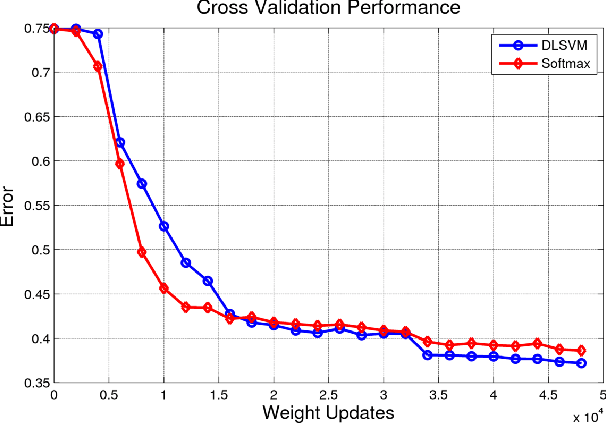
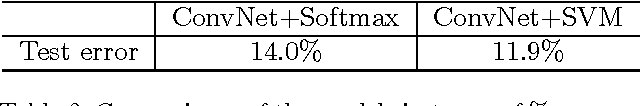
Recently, fully-connected and convolutional neural networks have been trained to achieve state-of-the-art performance on a wide variety of tasks such as speech recognition, image classification, natural language processing, and bioinformatics. For classification tasks, most of these "deep learning" models employ the softmax activation function for prediction and minimize cross-entropy loss. In this paper, we demonstrate a small but consistent advantage of replacing the softmax layer with a linear support vector machine. Learning minimizes a margin-based loss instead of the cross-entropy loss. While there have been various combinations of neural nets and SVMs in prior art, our results using L2-SVMs show that by simply replacing softmax with linear SVMs gives significant gains on popular deep learning datasets MNIST, CIFAR-10, and the ICML 2013 Representation Learning Workshop's face expression recognition challenge.
Challenges in Representation Learning: A report on three machine learning contests
Jul 01, 2013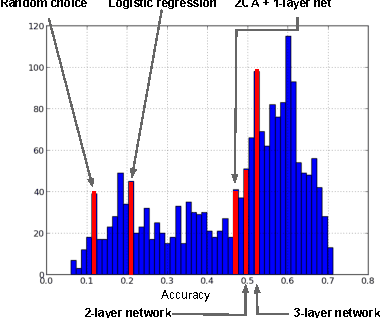

The ICML 2013 Workshop on Challenges in Representation Learning focused on three challenges: the black box learning challenge, the facial expression recognition challenge, and the multimodal learning challenge. We describe the datasets created for these challenges and summarize the results of the competitions. We provide suggestions for organizers of future challenges and some comments on what kind of knowledge can be gained from machine learning competitions.
Deep Lambertian Networks
Jun 27, 2012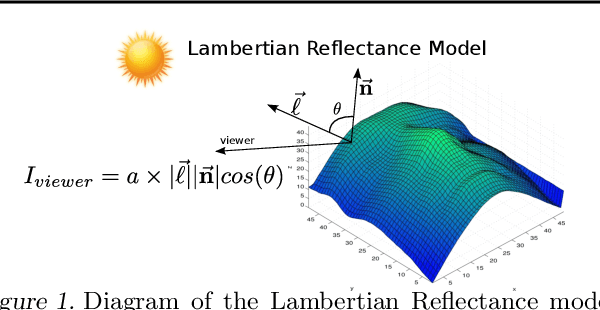
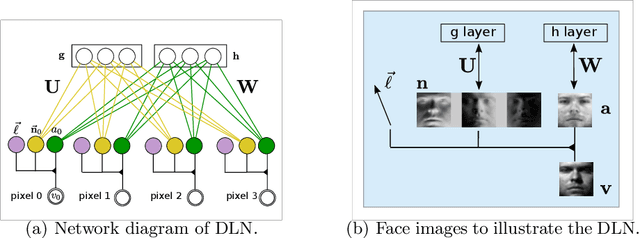


Visual perception is a challenging problem in part due to illumination variations. A possible solution is to first estimate an illumination invariant representation before using it for recognition. The object albedo and surface normals are examples of such representations. In this paper, we introduce a multilayer generative model where the latent variables include the albedo, surface normals, and the light source. Combining Deep Belief Nets with the Lambertian reflectance assumption, our model can learn good priors over the albedo from 2D images. Illumination variations can be explained by changing only the lighting latent variable in our model. By transferring learned knowledge from similar objects, albedo and surface normals estimation from a single image is possible in our model. Experiments demonstrate that our model is able to generalize as well as improve over standard baselines in one-shot face recognition.
Deep Mixtures of Factor Analysers
Jun 18, 2012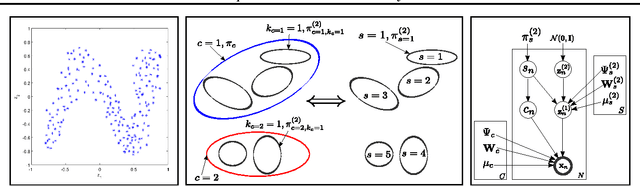
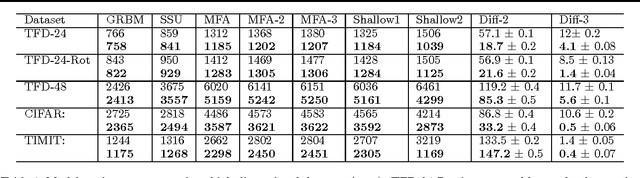
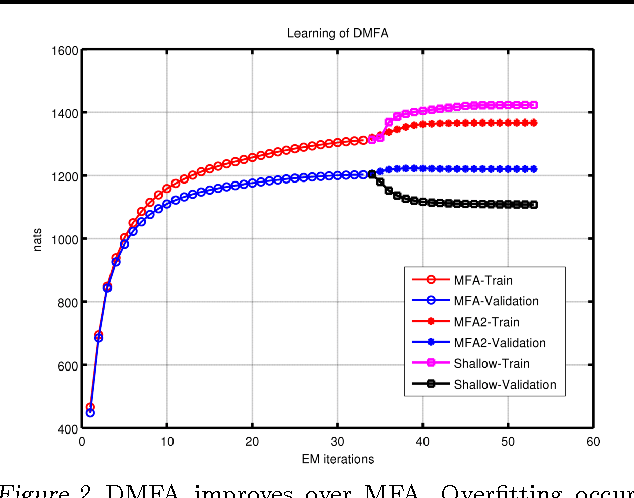

An efficient way to learn deep density models that have many layers of latent variables is to learn one layer at a time using a model that has only one layer of latent variables. After learning each layer, samples from the posterior distributions for that layer are used as training data for learning the next layer. This approach is commonly used with Restricted Boltzmann Machines, which are undirected graphical models with a single hidden layer, but it can also be used with Mixtures of Factor Analysers (MFAs) which are directed graphical models. In this paper, we present a greedy layer-wise learning algorithm for Deep Mixtures of Factor Analysers (DMFAs). Even though a DMFA can be converted to an equivalent shallow MFA by multiplying together the factor loading matrices at different levels, learning and inference are much more efficient in a DMFA and the sharing of each lower-level factor loading matrix by many different higher level MFAs prevents overfitting. We demonstrate empirically that DMFAs learn better density models than both MFAs and two types of Restricted Boltzmann Machine on a wide variety of datasets.