 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA-SEE2.0: Active-Sensing End-Effector for Robotic Ultrasound Systems with Dense Contact Surface Perception Enabled Probe Orientation Adjustment
Mar 07, 2025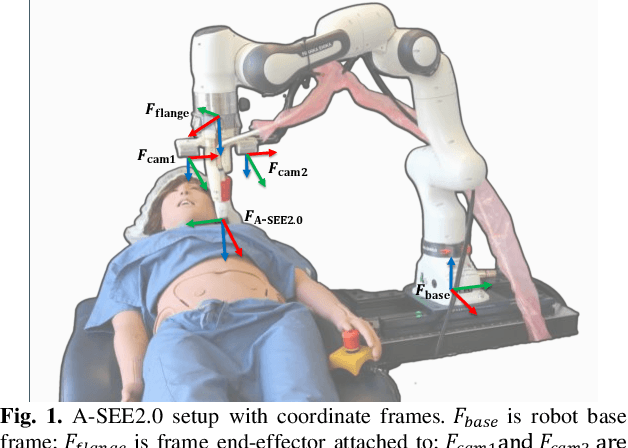
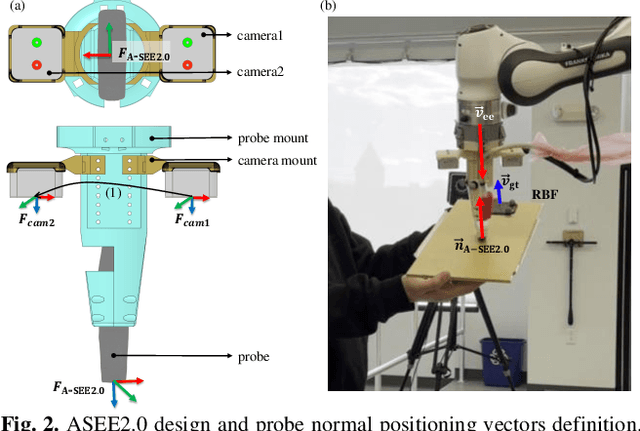
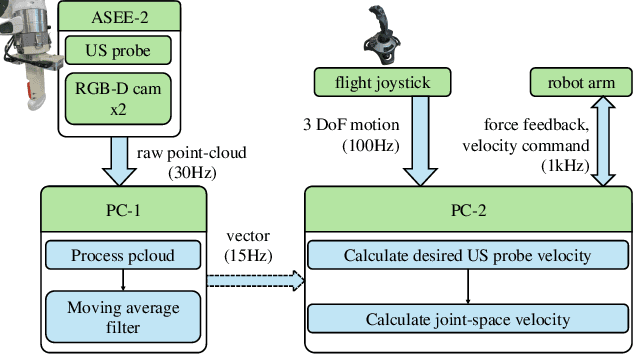
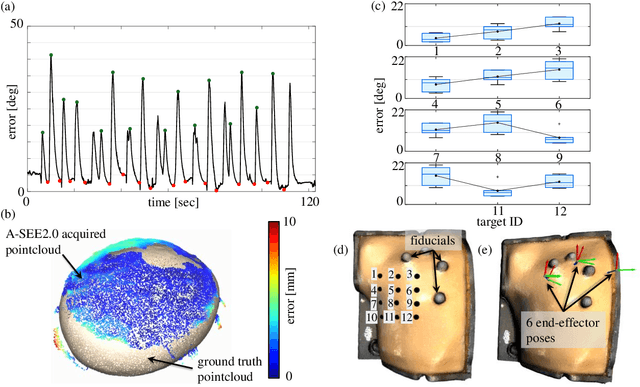
Conventional freehand ultrasound (US) imaging is highly dependent on the skill of the operator, often leading to inconsistent results and increased physical demand on sonographers. Robotic Ultrasound Systems (RUSS) aim to address these limitations by providing standardized and automated imaging solutions, especially in environments with limited access to skilled operators. This paper presents the development of a novel RUSS system that employs dual RGB-D depth cameras to maintain the US probe normal to the skin surface, a critical factor for optimal image quality. Our RUSS integrates RGB-D camera data with robotic control algorithms to maintain orthogonal probe alignment on uneven surfaces without preoperative data. Validation tests using a phantom model demonstrate that the system achieves robust normal positioning accuracy while delivering ultrasound images comparable to those obtained through manual scanning. A-SEE2.0 demonstrates 2.47 ${\pm}$ 1.25 degrees error for flat surface normal-positioning and 12.19 ${\pm}$ 5.81 degrees normal estimation error on mannequin surface. This work highlights the potential of A-SEE2.0 to be used in clinical practice by testing its performance during in-vivo forearm ultrasound examinations.
Hyperbolic Chamfer Distance for Point Cloud Completion and Beyond
Dec 23, 2024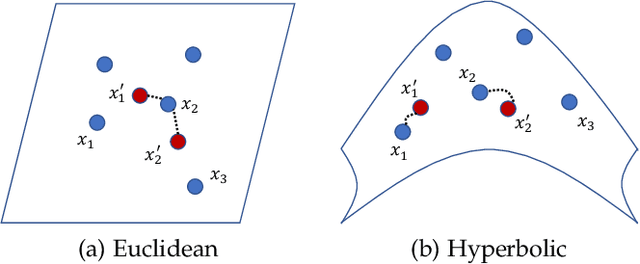
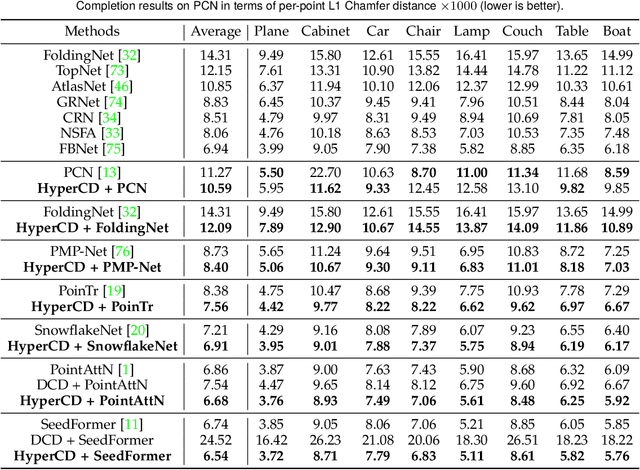
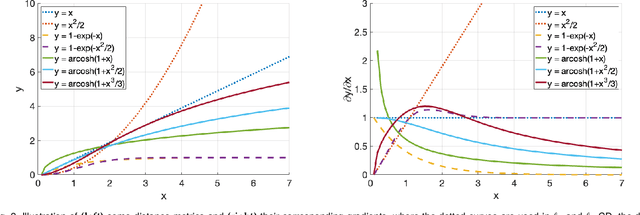
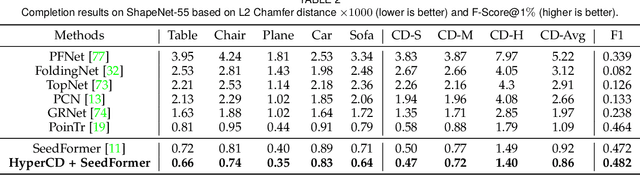
Chamfer Distance (CD) is widely used as a metric to quantify difference between two point clouds. In point cloud completion, Chamfer Distance (CD) is typically used as a loss function in deep learning frameworks. However, it is generally acknowledged within the field that Chamfer Distance (CD) is vulnerable to the presence of outliers, which can consequently lead to the convergence on suboptimal models. In divergence from the existing literature, which largely concentrates on resolving such concerns in the realm of Euclidean space, we put forth a notably uncomplicated yet potent metric specifically designed for point cloud completion tasks: {Hyperbolic Chamfer Distance (HyperCD)}. This metric conducts Chamfer Distance computations within the parameters of hyperbolic space. During the backpropagation process, HyperCD systematically allocates greater weight to matched point pairs exhibiting reduced Euclidean distances. This mechanism facilitates the preservation of accurate point pair matches while permitting the incremental adjustment of suboptimal matches, thereby contributing to enhanced point cloud completion outcomes. Moreover, measure the shape dissimilarity is not solely work for point cloud completion task, we further explore its applications in other generative related tasks, including single image reconstruction from point cloud, and upsampling. We demonstrate state-of-the-art performance on the point cloud completion benchmark datasets, PCN, ShapeNet-55, and ShapeNet-34, and show from visualization that HyperCD can significantly improve the surface smoothness, we also provide the provide experimental results beyond completion task.
SPADE: Spectroscopic Photoacoustic Denoising using an Analytical and Data-free Enhancement Framework
Dec 16, 2024



Spectroscopic photoacoustic (sPA) imaging uses multiple wavelengths to differentiate chromophores based on their unique optical absorption spectra. This technique has been widely applied in areas such as vascular mapping, tumor detection, and therapeutic monitoring. However, sPA imaging is highly susceptible to noise, leading to poor signal-to-noise ratio (SNR) and compromised image quality. Traditional denoising techniques like frame averaging, though effective in improving SNR, can be impractical for dynamic imaging scenarios due to reduced frame rates. Advanced methods, including learning-based approaches and analytical algorithms, have demonstrated promise but often require extensive training data and parameter tuning, limiting their adaptability for real-time clinical use. In this work, we propose a sPA denoising using a tuning-free analytical and data-free enhancement (SPADE) framework for denoising sPA images. This framework integrates a data-free learning-based method with an efficient BM3D-based analytical approach while preserves spectral linearity, providing noise reduction and ensuring that functional information is maintained. The SPADE framework was validated through simulation, phantom, ex vivo, and in vivo experiments. Results demonstrated that SPADE improved SNR and preserved spectral information, outperforming conventional methods, especially in challenging imaging conditions. SPADE presents a promising solution for enhancing sPA imaging quality in clinical applications where noise reduction and spectral preservation are critical.
Hand Gesture Classification Based on Forearm Ultrasound Video Snippets Using 3D Convolutional Neural Networks
Sep 24, 2024
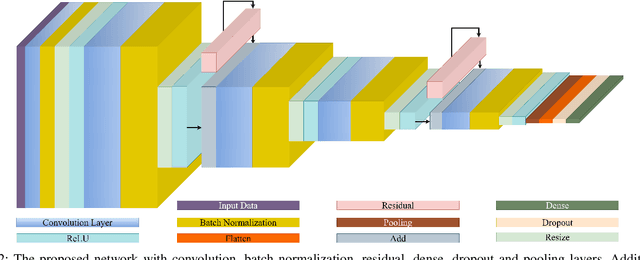
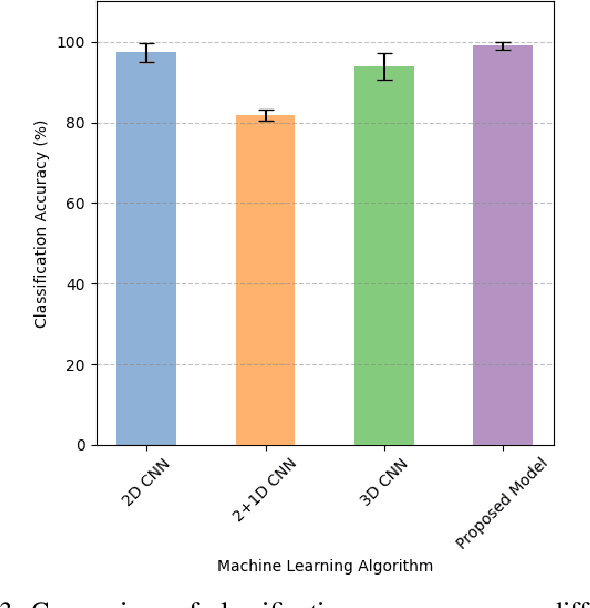
Ultrasound based hand movement estimation is a crucial area of research with applications in human-machine interaction. Forearm ultrasound offers detailed information about muscle morphology changes during hand movement which can be used to estimate hand gestures. Previous work has focused on analyzing 2-Dimensional (2D) ultrasound image frames using techniques such as convolutional neural networks (CNNs). However, such 2D techniques do not capture temporal features from segments of ultrasound data corresponding to continuous hand movements. This study uses 3D CNN based techniques to capture spatio-temporal patterns within ultrasound video segments for gesture recognition. We compared the performance of a 2D convolution-based network with (2+1)D convolution-based, 3D convolution-based, and our proposed network. Our methodology enhanced the gesture classification accuracy to 98.8 +/- 0.9%, from 96.5 +/- 2.3% compared to a network trained with 2D convolution layers. These results demonstrate the advantages of using ultrasound video snippets for improving hand gesture classification performance.
Improving Intersession Reproducibility for Forearm Ultrasound based Hand Gesture Classification through an Incremental Learning Approach
Sep 24, 2024Ultrasound images of the forearm can be used to classify hand gestures towards developing human machine interfaces. In our previous work, we have demonstrated gesture classification using ultrasound on a single subject without removing the probe before evaluation. This has limitations in usage as once the probe is removed and replaced, the accuracy declines since the classifier performance is sensitive to the probe location on the arm. In this paper, we propose training a model on multiple data collection sessions to create a generalized model, utilizing incremental learning through fine tuning. Ultrasound data was acquired for 5 hand gestures within a session (without removing and putting the probe back on) and across sessions. A convolutional neural network (CNN) with 5 cascaded convolution layers was used for this study. A pre-trained CNN was fine tuned with the convolution blocks acting as a feature extractor, and the parameters of the remaining layers updated in an incremental fashion. Fine tuning was done using different session splits within a session and between multiple sessions. We found that incremental fine tuning can help enhance classification accuracy with more fine tuning sessions. After 2 fine tuning sessions for each experiment, we found an approximate 10% increase in classification accuracy. This work demonstrates that incremental learning through fine tuning on ultrasound based hand gesture classification can be used improves accuracy while saving storage, processing power, and time. It can be expanded to generalize between multiple subjects and towards developing personalized wearable devices.
Forearm Ultrasound based Gesture Recognition on Edge
Sep 16, 2024



Ultrasound imaging of the forearm has demonstrated significant potential for accurate hand gesture classification. Despite this progress, there has been limited focus on developing a stand-alone end- to-end gesture recognition system which makes it mobile, real-time and more user friendly. To bridge this gap, this paper explores the deployment of deep neural networks for forearm ultrasound-based hand gesture recognition on edge devices. Utilizing quantization techniques, we achieve substantial reductions in model size while maintaining high accuracy and low latency. Our best model, with Float16 quantization, achieves a test accuracy of 92% and an inference time of 0.31 seconds on a Raspberry Pi. These results demonstrate the feasibility of efficient, real-time gesture recognition on resource-limited edge devices, paving the way for wearable ultrasound-based systems.
Loss Distillation via Gradient Matching for Point Cloud Completion with Weighted Chamfer Distance
Sep 10, 2024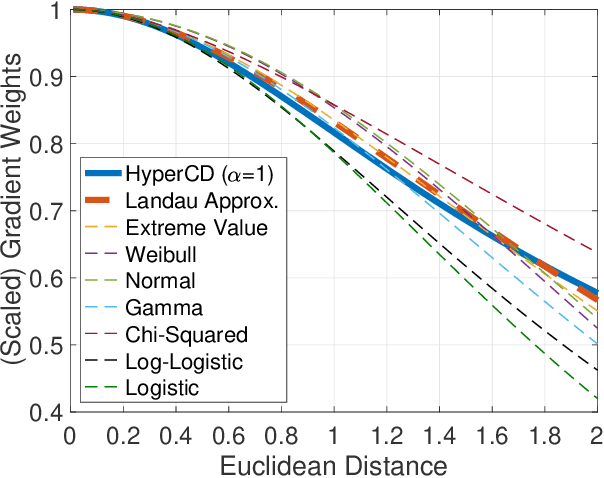
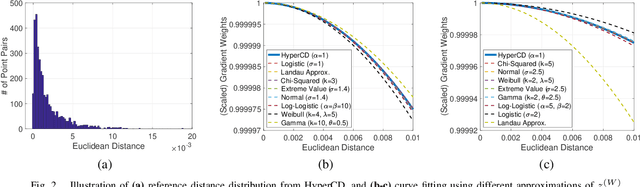


3D point clouds enhanced the robot's ability to perceive the geometrical information of the environments, making it possible for many downstream tasks such as grasp pose detection and scene understanding. The performance of these tasks, though, heavily relies on the quality of data input, as incomplete can lead to poor results and failure cases. Recent training loss functions designed for deep learning-based point cloud completion, such as Chamfer distance (CD) and its variants (\eg HyperCD ), imply a good gradient weighting scheme can significantly boost performance. However, these CD-based loss functions usually require data-related parameter tuning, which can be time-consuming for data-extensive tasks. To address this issue, we aim to find a family of weighted training losses ({\em weighted CD}) that requires no parameter tuning. To this end, we propose a search scheme, {\em Loss Distillation via Gradient Matching}, to find good candidate loss functions by mimicking the learning behavior in backpropagation between HyperCD and weighted CD. Once this is done, we propose a novel bilevel optimization formula to train the backbone network based on the weighted CD loss. We observe that: (1) with proper weighted functions, the weighted CD can always achieve similar performance to HyperCD, and (2) the Landau weighted CD, namely {\em Landau CD}, can outperform HyperCD for point cloud completion and lead to new state-of-the-art results on several benchmark datasets. {\it Our demo code is available at \url{https://github.com/Zhang-VISLab/IROS2024-LossDistillationWeightedCD}.}
Guiding the Last Centimeter: Novel Anatomy-Aware Probe Servoing for Standardized Imaging Plane Navigation in Robotic Lung Ultrasound
Jun 17, 2024Navigating the ultrasound (US) probe to the standardized imaging plane (SIP) for image acquisition is a critical but operator-dependent task in conventional freehand diagnostic US. Robotic US systems (RUSS) offer the potential to enhance imaging consistency by leveraging real-time US image feedback to optimize the probe pose, thereby reducing reliance on operator expertise. However, determining the proper approach to extracting generalizable features from the US images for probe pose adjustment remain challenging. In this work, we propose a SIP navigation framework for RUSS, exemplified in the context of robotic lung ultrasound (LUS). This framework facilitates automatic probe adjustment when in proximity to the SIP. This is achieved by explicitly extracting multiple anatomical features presented in real-time LUS images and performing non-patient-specific template matching to generate probe motion towards the SIP using image-based visual servoing (IBVS). This framework is further integrated with the active-sensing end-effector (A-SEE), a customized robot end-effector that leverages patient external body geometry to maintain optimal probe alignment with the contact surface, thus preserving US signal quality throughout the navigation. The proposed approach ensures procedural interpretability and inter-patient adaptability. Validation is conducted through anatomy-mimicking phantom and in-vivo evaluations involving five human subjects. The results show the framework's high navigation precision with the probe correctly located at the SIP for all cases, exhibiting positioning error of under 2 mm in translation and under 2 degree in rotation. These results demonstrate the navigation process's capability to accomondate anatomical variations among patients.
Simultaneous Estimation of Hand Configurations and Finger Joint Angles using Forearm Ultrasound
Nov 29, 2022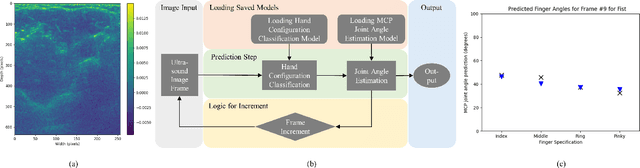
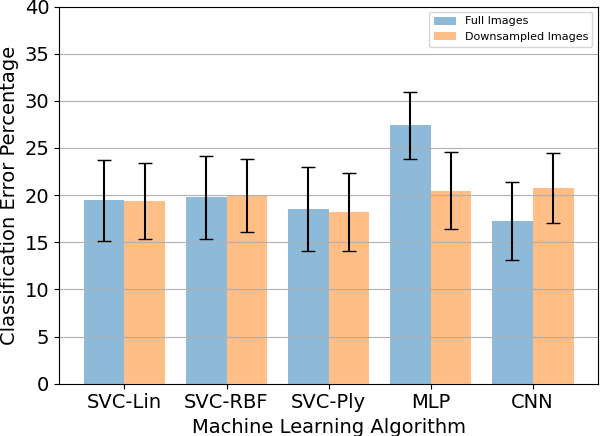
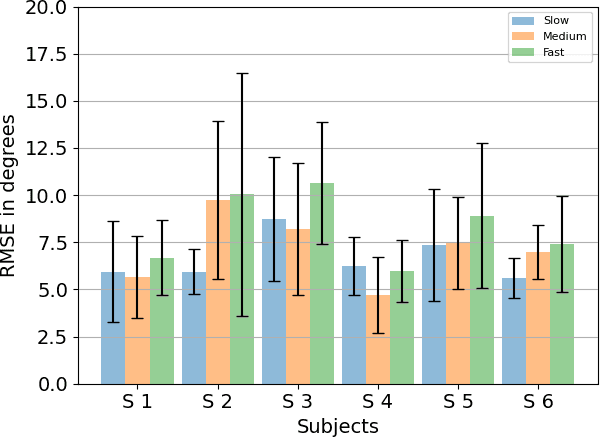
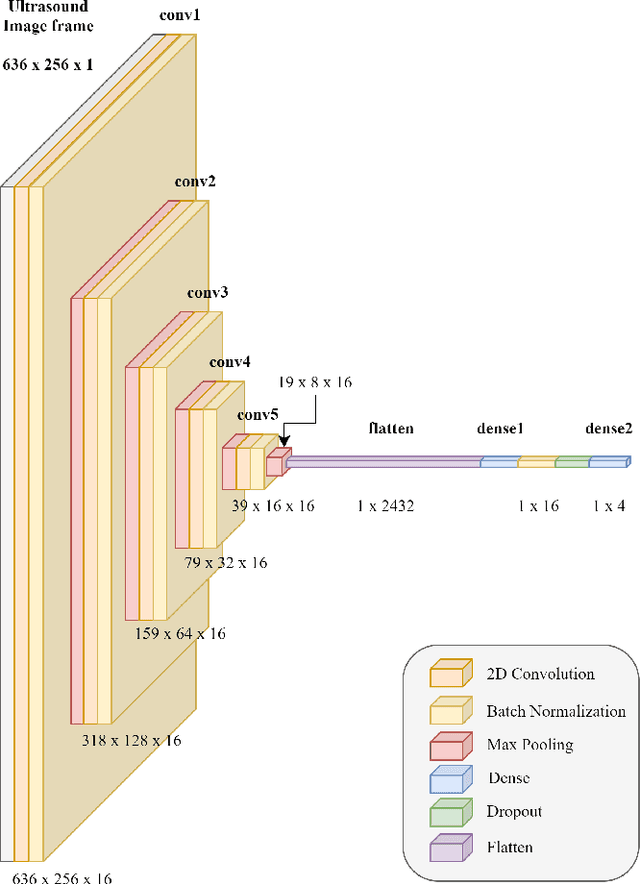
With the advancement in computing and robotics, it is necessary to develop fluent and intuitive methods for interacting with digital systems, augmented/virtual reality (AR/VR) interfaces, and physical robotic systems. Hand motion recognition is widely used to enable these interactions. Hand configuration classification and MCP joint angle detection is important for a comprehensive reconstruction of hand motion. sEMG and other technologies have been used for the detection of hand motions. Forearm ultrasound images provide a musculoskeletal visualization that can be used to understand hand motion. Recent work has shown that these ultrasound images can be classified using machine learning to estimate discrete hand configurations. Estimating both hand configuration and MCP joint angles based on forearm ultrasound has not been addressed in the literature. In this paper, we propose a CNN based deep learning pipeline for predicting the MCP joint angles. The results for the hand configuration classification were compared by using different machine learning algorithms. SVC with different kernels, MLP, and the proposed CNN have been used to classify the ultrasound images into 11 hand configurations based on activities of daily living. Forearm ultrasound images were acquired from 6 subjects instructed to move their hands according to predefined hand configurations. Motion capture data was acquired to get the finger angles corresponding to the hand movements at different speeds. Average classification accuracy of 82.7% for the proposed CNN and over 80% for SVC for different kernels was observed on a subset of the dataset. An average RMSE of 7.35 degrees was obtained between the predicted and the true MCP joint angles. A low latency (6.25 - 9.1 Hz) pipeline has been proposed for estimating both MCP joint angles and hand configuration aimed at real-time control of human-machine interfaces.
Actuated Reflector-Based Three-dimensional Ultrasound Imaging with Adaptive-Delay Synthetic Aperture Focusing
Dec 13, 2021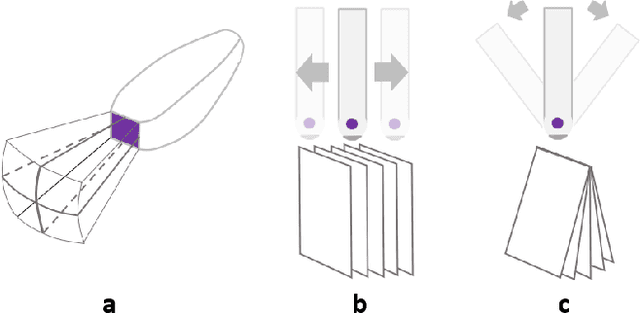

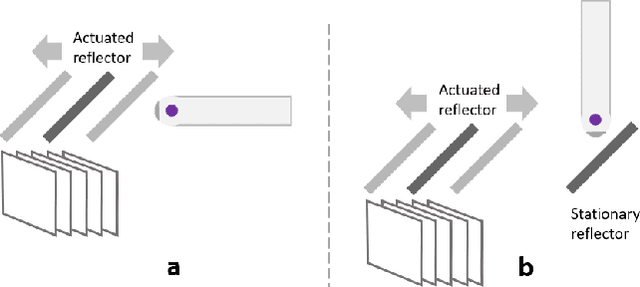
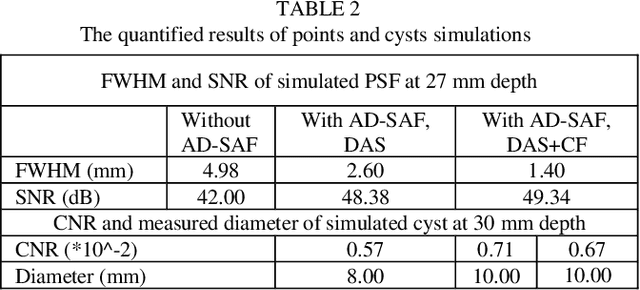
Three-dimensional (3D) ultrasound (US) imaging addresses the limitation in field-of-view (FOV) in conventional two-dimensional (2D) US imaging by providing 3D viewing of the anatomy. 3D US imaging has been extensively adapted for diagnosis and image-guided surgical intervention. However, conventional approaches to implement 3D US imaging require either expensive and sophisticated 2D array transducers, or external actuation mechanisms to move a one-dimensional array mechanically. Here, we propose a 3D US imaging mechanism using actuated acoustic reflector instead of the sensor elements for volume acquisition with significantly extended 3D FOV, which can be implemented with simple hardware and compact size. To improve image quality on the elevation plane, we introduce an adaptive-delay synthetic aperture focusing (AD-SAF) method for elevation beamforming. We first evaluated the proposed imaging mechanism and AD-SAF with simulated point targets and cysts targets. Results of point targets suggested improved image quality on the elevation plane, and results of cysts targets demonstrated a potential to improve 3D visualization of human anatomy. We built a prototype imaging system that has a 3D FOV of 38 mm (lateral) by 38 mm (elevation) by 50 mm (axial) and collected data in imaging experiments with phantoms. Experimental data showed consistency with simulation results. The AD-SAF method enhanced quantifying the cyst volume size in the breast mimicking phantom compared to without elevation beamforming. These results suggested that the proposed 3D US imaging mechanism could potentially be applied in clinical scenarios.