 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA-SEE2.0: Active-Sensing End-Effector for Robotic Ultrasound Systems with Dense Contact Surface Perception Enabled Probe Orientation Adjustment
Mar 07, 2025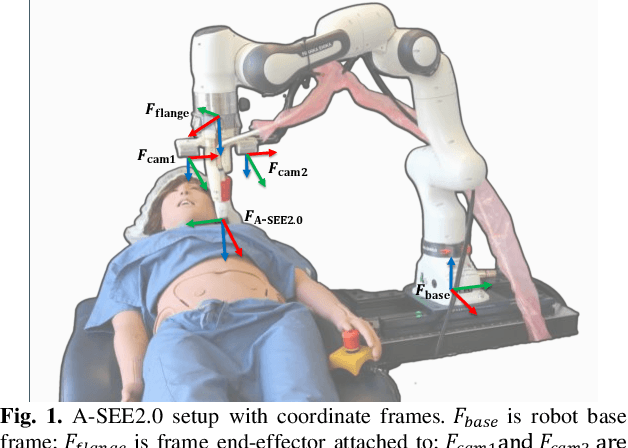
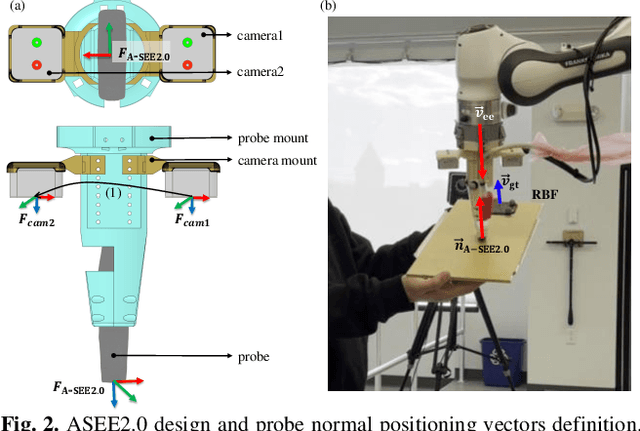
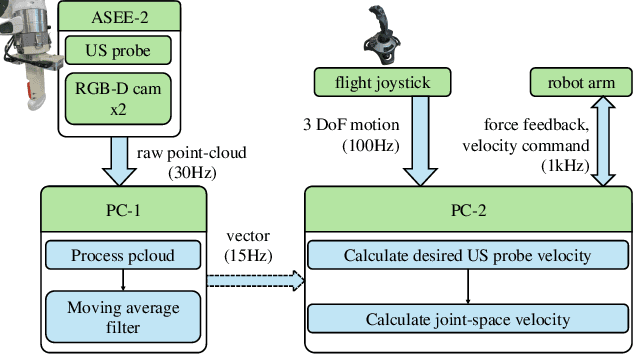
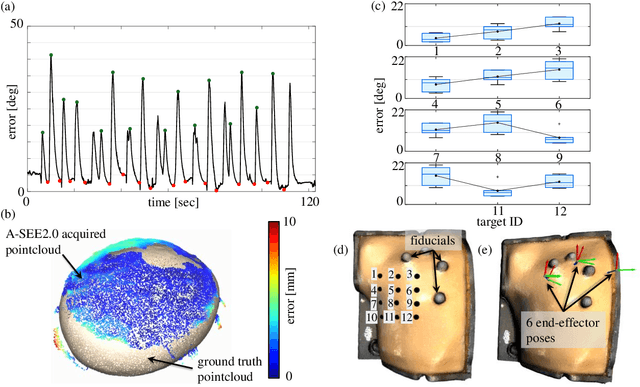
Conventional freehand ultrasound (US) imaging is highly dependent on the skill of the operator, often leading to inconsistent results and increased physical demand on sonographers. Robotic Ultrasound Systems (RUSS) aim to address these limitations by providing standardized and automated imaging solutions, especially in environments with limited access to skilled operators. This paper presents the development of a novel RUSS system that employs dual RGB-D depth cameras to maintain the US probe normal to the skin surface, a critical factor for optimal image quality. Our RUSS integrates RGB-D camera data with robotic control algorithms to maintain orthogonal probe alignment on uneven surfaces without preoperative data. Validation tests using a phantom model demonstrate that the system achieves robust normal positioning accuracy while delivering ultrasound images comparable to those obtained through manual scanning. A-SEE2.0 demonstrates 2.47 ${\pm}$ 1.25 degrees error for flat surface normal-positioning and 12.19 ${\pm}$ 5.81 degrees normal estimation error on mannequin surface. This work highlights the potential of A-SEE2.0 to be used in clinical practice by testing its performance during in-vivo forearm ultrasound examinations.
Meta Reinforcement Learning with Distribution of Exploration Parameters Learned by Evolution Strategies
Dec 29, 2018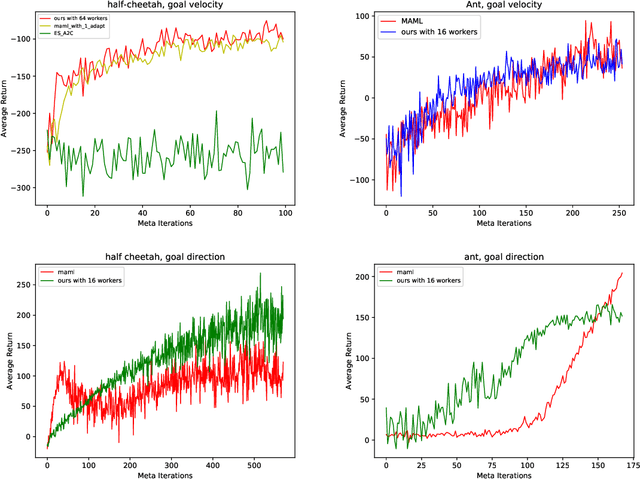

In this paper, we propose a novel meta-learning method in a reinforcement learning setting, based on evolution strategies (ES), exploration in parameter space and deterministic policy gradients. ES methods are easy to parallelize, which is desirable for modern training architectures; however, such methods typically require a huge number of samples for effective training. We use deterministic policy gradients during adaptation and other techniques to compensate for the sample-efficiency problem while maintaining the inherent scalability of ES methods. We demonstrate that our method achieves good results compared to gradient-based meta-learning in high-dimensional control tasks in the MuJoCo simulator. In addition, because of gradient-free methods in the meta-training phase, which do not need information about gradients and policies in adaptation training, we predict and confirm our algorithm performs better in tasks that need multi-step adaptation.