 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayerwise Progressive Freezing Enables STE-Free Training of Deep Binary Neural Networks
Jan 30, 2026We investigate progressive freezing as an alternative to straight-through estimators (STE) for training binary networks from scratch. Under controlled training conditions, we find that while global progressive freezing works for binary-weight networks, it fails for full binary neural networks due to activation-induced gradient blockades. We introduce StoMPP (Stochastic Masked Partial Progressive Binarization), which uses layerwise stochastic masking to progressively replace differentiable clipped weights/activations with hard binary step functions, while only backpropagating through the unfrozen (clipped) subset (i.e., no straight-through estimator). Under a matched minimal training recipe, StoMPP improves accuracy over a BinaryConnect-style STE baseline, with gains that increase with depth (e.g., for ResNet-50 BNN: +18.0 on CIFAR-10, +13.5 on CIFAR-100, and +3.8 on ImageNet; for ResNet-18: +3.1, +4.7, and +1.3). For binary-weight networks, StoMPP achieves 91.2\% accuracy on CIFAR-10 and 69.5\% on CIFAR-100 with ResNet-50. We analyze training dynamics under progressive freezing, revealing non-monotonic convergence and improved depth scaling under binarization constraints.
UnIT: Scalable Unstructured Inference-Time Pruning for MAC-efficient Neural Inference on MCUs
Jul 10, 2025Existing pruning methods are typically applied during training or compile time and often rely on structured sparsity. While compatible with low-power microcontrollers (MCUs), structured pruning underutilizes the opportunity for fine-grained efficiency on devices without SIMD support or parallel compute. To address these limitations, we introduce UnIT (Unstructured Inference-Time pruning), a lightweight method that dynamically identifies and skips unnecessary multiply-accumulate (MAC) operations during inference, guided by input-specific activation patterns. Unlike structured pruning, UnIT embraces irregular sparsity and does not require retraining or hardware specialization. It transforms pruning decisions into lightweight comparisons, replacing multiplications with threshold checks and approximated divisions. UnIT further optimizes compute by reusing threshold computations across multiple connections and applying layer- and group-specific pruning sensitivity. We present three fast, hardware-friendly division approximations tailored to the capabilities of common embedded platforms. Demonstrated on the MSP430 microcontroller, UnIT achieves 11.02% to 82.03% MAC reduction, 27.30% to 84.19% faster inference, and 27.33% to 84.38% lower energy consumption compared to training-time pruned models, while maintaining accuracy with 0.48-7%. Under domain shift, UnIT matches or exceeds the accuracy of retrained models while requiring significantly fewer MACs. These results establish unstructured inference-time pruning as a viable and practical solution for efficient, retraining-free deployment of deep neural networks on MCUs.
RAVEN: Query-Guided Representation Alignment for Question Answering over Audio, Video, Embedded Sensors, and Natural Language
May 21, 2025Multimodal question answering (QA) often requires identifying which video, audio, or sensor tokens are relevant to the question. Yet modality disagreements are common: off-camera speech, background noise, or motion outside the field of view often mislead fusion models that weight all streams equally. We present RAVEN, a unified QA architecture whose core is QuART, a query-conditioned cross-modal gating module that assigns scalar relevance scores to each token across modalities, enabling the model to amplify informative signals and suppress distractors before fusion. RAVEN is trained through a three-stage pipeline comprising unimodal pretraining, query-aligned fusion, and disagreement-oriented fine-tuning -- each stage targeting a distinct challenge in multi-modal reasoning: representation quality, cross-modal relevance, and robustness to modality mismatch. To support training and evaluation, we release AVS-QA, a dataset of 300K synchronized Audio--Video-Sensor streams paired with automatically generated question-answer pairs. Experimental results on seven multi-modal QA benchmarks -- including egocentric and exocentric tasks -- show that RAVEN achieves up to 14.5\% and 8.0\% gains in accuracy compared to state-of-the-art multi-modal large language models, respectively. Incorporating sensor data provides an additional 16.4\% boost, and the model remains robust under modality corruption, outperforming SOTA baselines by 50.23\%. Our code and dataset are available at https://github.com/BASHLab/RAVEN.
QUADS: QUAntized Distillation Framework for Efficient Speech Language Understanding
May 19, 2025Spoken Language Understanding (SLU) systems must balance performance and efficiency, particularly in resource-constrained environments. Existing methods apply distillation and quantization separately, leading to suboptimal compression as distillation ignores quantization constraints. We propose QUADS, a unified framework that optimizes both through multi-stage training with a pre-tuned model, enhancing adaptability to low-bit regimes while maintaining accuracy. QUADS achieves 71.13\% accuracy on SLURP and 99.20\% on FSC, with only minor degradations of up to 5.56\% compared to state-of-the-art models. Additionally, it reduces computational complexity by 60--73$\times$ (GMACs) and model size by 83--700$\times$, demonstrating strong robustness under extreme quantization. These results establish QUADS as a highly efficient solution for real-world, resource-constrained SLU applications.
Forearm Ultrasound based Gesture Recognition on Edge
Sep 16, 2024



Ultrasound imaging of the forearm has demonstrated significant potential for accurate hand gesture classification. Despite this progress, there has been limited focus on developing a stand-alone end- to-end gesture recognition system which makes it mobile, real-time and more user friendly. To bridge this gap, this paper explores the deployment of deep neural networks for forearm ultrasound-based hand gesture recognition on edge devices. Utilizing quantization techniques, we achieve substantial reductions in model size while maintaining high accuracy and low latency. Our best model, with Float16 quantization, achieves a test accuracy of 92% and an inference time of 0.31 seconds on a Raspberry Pi. These results demonstrate the feasibility of efficient, real-time gesture recognition on resource-limited edge devices, paving the way for wearable ultrasound-based systems.
Sound Tagging in Infant-centric Home Soundscapes
Jun 25, 2024



Certain environmental noises have been associated with negative developmental outcomes for infants and young children. Though classifying or tagging sound events in a domestic environment is an active research area, previous studies focused on data collected from a non-stationary microphone placed in the environment or from the perspective of adults. Further, many of these works ignore infants or young children in the environment or have data collected from only a single family where noise from the fixed sound source can be moderate at the infant's position or vice versa. Thus, despite the recent success of large pre-trained models for noise event detection, the performance of these models on infant-centric noise soundscapes in the home is yet to be explored. To bridge this gap, we have collected and labeled noises in home soundscapes from 22 families in an unobtrusive manner, where the data are collected through an infant-worn recording device. In this paper, we explore the performance of a large pre-trained model (Audio Spectrogram Transformer [AST]) on our noise-conditioned infant-centric environmental data as well as publicly available home environmental datasets. Utilizing different training strategies such as resampling, utilizing public datasets, mixing public and infant-centric training sets, and data augmentation using noise and masking, we evaluate the performance of a large pre-trained model on sparse and imbalanced infant-centric data. Our results show that fine-tuning the large pre-trained model by combining our collected dataset with public datasets increases the F1-score from 0.11 (public datasets) and 0.76 (collected datasets) to 0.84 (combined datasets) and Cohen's Kappa from 0.013 (public datasets) and 0.77 (collected datasets) to 0.83 (combined datasets) compared to only training with public or collected datasets, respectively.
LLaSA: Large Multimodal Agent for Human Activity Analysis Through Wearable Sensors
Jun 20, 2024



Integrating inertial measurement units (IMUs) with large language models (LLMs) advances multimodal AI by enhancing human activity understanding. We introduce SensorCaps, a dataset of 26,288 IMU-derived activity narrations, and OpenSQA, an instruction-following dataset with 257,562 question-answer pairs. Combining LIMU-BERT and Llama, we develop LLaSA, a Large Multimodal Agent capable of interpreting and responding to activity and motion analysis queries. Our evaluation demonstrates LLaSA's effectiveness in activity classification and question answering, highlighting its potential in healthcare, sports science, and human-computer interaction. These contributions advance sensor-aware language models and open new research avenues. Our code repository and datasets can be found on https://github.com/BASHLab/LLaSA.
Missingness-resilient Video-enhanced Multimodal Disfluency Detection
Jun 11, 2024

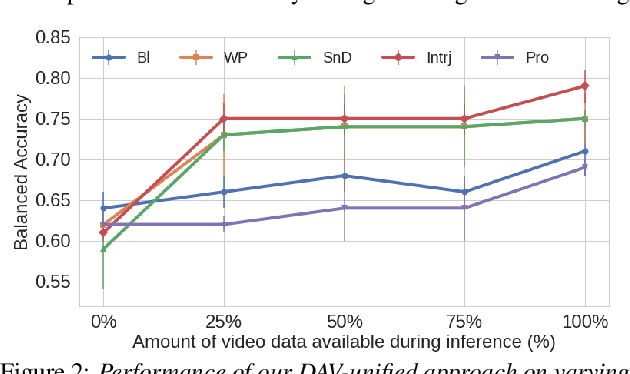
Most existing speech disfluency detection techniques only rely upon acoustic data. In this work, we present a practical multimodal disfluency detection approach that leverages available video data together with audio. We curate an audiovisual dataset and propose a novel fusion technique with unified weight-sharing modality-agnostic encoders to learn the temporal and semantic context. Our resilient design accommodates real-world scenarios where the video modality may sometimes be missing during inference. We also present alternative fusion strategies when both modalities are assured to be complete. In experiments across five disfluency-detection tasks, our unified multimodal approach significantly outperforms Audio-only unimodal methods, yielding an average absolute improvement of 10% (i.e., 10 percentage point increase) when both video and audio modalities are always available, and 7% even when video modality is missing in half of the samples.
Memory-efficient Energy-adaptive Inference of Pre-Trained Models on Batteryless Embedded Systems
May 16, 2024
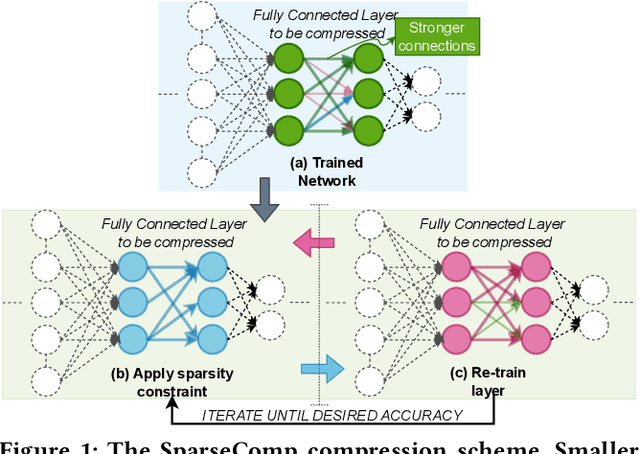
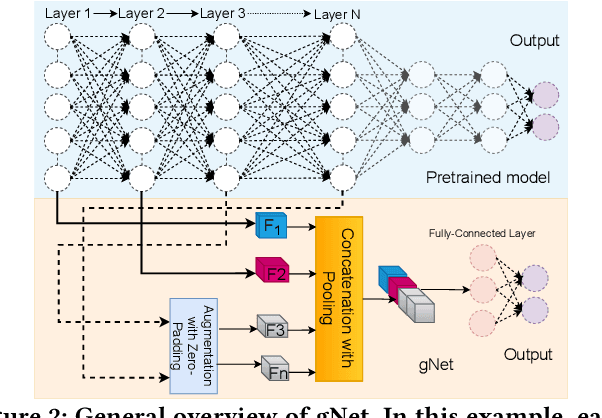

Batteryless systems frequently face power failures, requiring extra runtime buffers to maintain inference progress and leaving only a memory space for storing ultra-tiny deep neural networks (DNNs). Besides, making these models responsive to stochastic energy harvesting dynamics during inference requires a balance between inference accuracy, latency, and energy overhead. Recent works on compression mostly focus on time and memory, but often ignore energy dynamics or significantly reduce the accuracy of pre-trained DNNs. Existing energy-adaptive inference works modify the architecture of pre-trained models and have significant memory overhead. Thus, energy-adaptive and accurate inference of pre-trained DNNs on batteryless devices with extreme memory constraints is more challenging than traditional microcontrollers. We combat these issues by proposing FreeML, a framework to optimize pre-trained DNN models for memory-efficient and energy-adaptive inference on batteryless systems. FreeML comprises (1) a novel compression technique to reduce the model footprint and runtime memory requirements simultaneously, making them executable on extremely memory-constrained batteryless platforms; and (2) the first early exit mechanism that uses a single exit branch for all exit points to terminate inference at any time, making models energy-adaptive with minimal memory overhead. Our experiments showed that FreeML reduces the model sizes by up to $95 \times$, supports adaptive inference with a $2.03-19.65 \times$ less memory overhead, and provides significant time and energy benefits with only a negligible accuracy drop compared to the state-of-the-art.
Classification of Infant Sleep/Wake States: Cross-Attention among Large Scale Pretrained Transformer Networks using Audio, ECG, and IMU Data
Jun 27, 2023
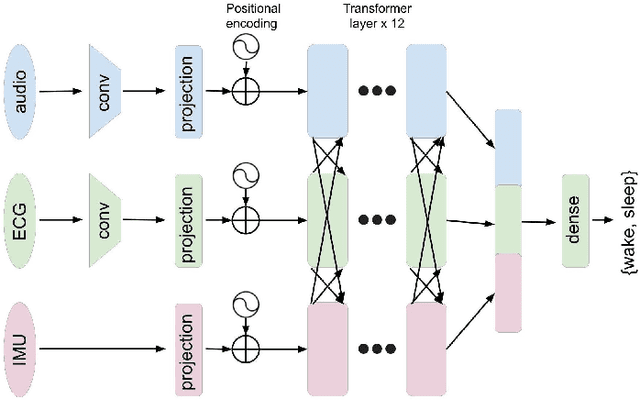


Infant sleep is critical to brain and behavioral development. Prior studies on infant sleep/wake classification have been largely limited to reliance on expensive and burdensome polysomnography (PSG) tests in the laboratory or wearable devices that collect single-modality data. To facilitate data collection and accuracy of detection, we aimed to advance this field of study by using a multi-modal wearable device, LittleBeats (LB), to collect audio, electrocardiogram (ECG), and inertial measurement unit (IMU) data among a cohort of 28 infants. We employed a 3-branch (audio/ECG/IMU) large scale transformer-based neural network (NN) to demonstrate the potential of such multi-modal data. We pretrained each branch independently with its respective modality, then finetuned the model by fusing the pretrained transformer layers with cross-attention. We show that multi-modal data significantly improves sleep/wake classification (accuracy = 0.880), compared with use of a single modality (accuracy = 0.732). Our approach to multi-modal mid-level fusion may be adaptable to a diverse range of architectures and tasks, expanding future directions of infant behavioral research.