 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSound Tagging in Infant-centric Home Soundscapes
Jun 25, 2024



Certain environmental noises have been associated with negative developmental outcomes for infants and young children. Though classifying or tagging sound events in a domestic environment is an active research area, previous studies focused on data collected from a non-stationary microphone placed in the environment or from the perspective of adults. Further, many of these works ignore infants or young children in the environment or have data collected from only a single family where noise from the fixed sound source can be moderate at the infant's position or vice versa. Thus, despite the recent success of large pre-trained models for noise event detection, the performance of these models on infant-centric noise soundscapes in the home is yet to be explored. To bridge this gap, we have collected and labeled noises in home soundscapes from 22 families in an unobtrusive manner, where the data are collected through an infant-worn recording device. In this paper, we explore the performance of a large pre-trained model (Audio Spectrogram Transformer [AST]) on our noise-conditioned infant-centric environmental data as well as publicly available home environmental datasets. Utilizing different training strategies such as resampling, utilizing public datasets, mixing public and infant-centric training sets, and data augmentation using noise and masking, we evaluate the performance of a large pre-trained model on sparse and imbalanced infant-centric data. Our results show that fine-tuning the large pre-trained model by combining our collected dataset with public datasets increases the F1-score from 0.11 (public datasets) and 0.76 (collected datasets) to 0.84 (combined datasets) and Cohen's Kappa from 0.013 (public datasets) and 0.77 (collected datasets) to 0.83 (combined datasets) compared to only training with public or collected datasets, respectively.
Analysis of Self-Supervised Speech Models on Children's Speech and Infant Vocalizations
Feb 10, 2024



To understand why self-supervised learning (SSL) models have empirically achieved strong performances on several speech-processing downstream tasks, numerous studies have focused on analyzing the encoded information of the SSL layer representations in adult speech. Limited work has investigated how pre-training and fine-tuning affect SSL models encoding children's speech and vocalizations. In this study, we aim to bridge this gap by probing SSL models on two relevant downstream tasks: (1) phoneme recognition (PR) on the speech of adults, older children (8-10 years old), and younger children (1-4 years old), and (2) vocalization classification (VC) distinguishing cry, fuss, and babble for infants under 14 months old. For younger children's PR, the superiority of fine-tuned SSL models is largely due to their ability to learn features that represent older children's speech and then adapt those features to the speech of younger children. For infant VC, SSL models pre-trained on large-scale home recordings learn to leverage phonetic representations at middle layers, and thereby enhance the performance of this task.
Classification of Infant Sleep/Wake States: Cross-Attention among Large Scale Pretrained Transformer Networks using Audio, ECG, and IMU Data
Jun 27, 2023
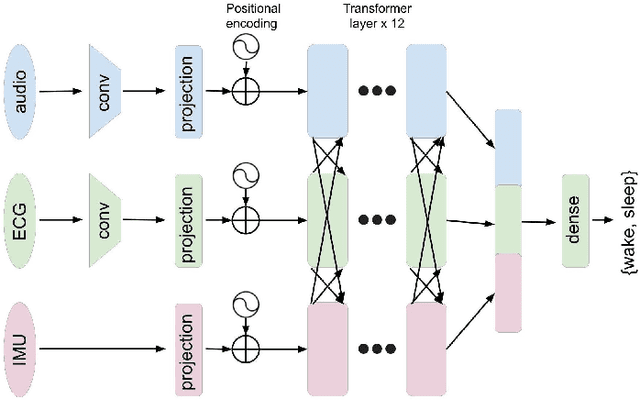


Infant sleep is critical to brain and behavioral development. Prior studies on infant sleep/wake classification have been largely limited to reliance on expensive and burdensome polysomnography (PSG) tests in the laboratory or wearable devices that collect single-modality data. To facilitate data collection and accuracy of detection, we aimed to advance this field of study by using a multi-modal wearable device, LittleBeats (LB), to collect audio, electrocardiogram (ECG), and inertial measurement unit (IMU) data among a cohort of 28 infants. We employed a 3-branch (audio/ECG/IMU) large scale transformer-based neural network (NN) to demonstrate the potential of such multi-modal data. We pretrained each branch independently with its respective modality, then finetuned the model by fusing the pretrained transformer layers with cross-attention. We show that multi-modal data significantly improves sleep/wake classification (accuracy = 0.880), compared with use of a single modality (accuracy = 0.732). Our approach to multi-modal mid-level fusion may be adaptable to a diverse range of architectures and tasks, expanding future directions of infant behavioral research.
Towards Robust Family-Infant Audio Analysis Based on Unsupervised Pretraining of Wav2vec 2.0 on Large-Scale Unlabeled Family Audio
May 21, 2023To perform automatic family audio analysis, past studies have collected recordings using phone, video, or audio-only recording devices like LENA, investigated supervised learning methods, and used or fine-tuned general-purpose embeddings learned from large pretrained models. In this study, we advance the audio component of a new infant wearable multi-modal device called LittleBeats (LB) by learning family audio representation via wav2vec 2.0 (W2V2) pertaining. We show given a limited number of labeled LB home recordings, W2V2 pretrained using 1k-hour of unlabeled home recordings outperforms oracle W2V2 pretrained on 52k-hour unlabeled audio in terms of parent/infant speaker diarization (SD) and vocalization classifications (VC) at home. Extra relevant external unlabeled and labeled data further benefit W2V2 pretraining and fine-tuning. With SpecAug and environmental speech corruptions, we obtain 12% relative gain on SD and moderate boost on VC. Code and model weights are available.
Visualizations of Complex Sequences of Family-Infant Vocalizations Using Bag-of-Audio-Words Approach Based on Wav2vec 2.0 Features
Mar 29, 2022



In the U.S., approximately 15-17% of children 2-8 years of age are estimated to have at least one diagnosed mental, behavioral or developmental disorder. However, such disorders often go undiagnosed, and the ability to evaluate and treat disorders in the first years of life is limited. To analyze infant developmental changes, previous studies have shown advanced ML models excel at classifying infant and/or parent vocalizations collected using cell phone, video, or audio-only recording device like LENA. In this study, we pilot test the audio component of a new infant wearable multi-modal device that we have developed called LittleBeats (LB). LB audio pipeline is advanced in that it provides reliable labels for both speaker diarization and vocalization classification tasks, compared with other platforms that only record audio and/or provide speaker diarization labels. We leverage wav2vec 2.0 to obtain superior and more nuanced results with the LB family audio stream. We use a bag-of-audio-words method with wav2vec 2.0 features to create high-level visualizations to understand family-infant vocalization interactions. We demonstrate that our high-quality visualizations capture major types of family vocalization interactions, in categories indicative of mental, behavioral, and developmental health, for both labeled and unlabeled LB audio.