 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeSliver : Symbolic-Linear Decomposition for Explainable Time Series Classification
Jan 29, 2026Identifying the extent to which every temporal segment influences a model's predictions is essential for explaining model decisions and increasing transparency. While post-hoc explainable methods based on gradients and feature-based attributions have been popular, they suffer from reference state sensitivity and struggle to generalize across time-series datasets, as they treat time points independently and ignore sequential dependencies. Another perspective on explainable time-series classification is through interpretable components of the model, for instance, leveraging self-attention mechanisms to estimate temporal attribution; however, recent findings indicate that these attention weights often fail to provide faithful measures of temporal importance. In this work, we advance this perspective and present a novel explainability-driven deep learning framework, TimeSliver, which jointly utilizes raw time-series data and its symbolic abstraction to construct a representation that maintains the original temporal structure. Each element in this representation linearly encodes the contribution of each temporal segment to the final prediction, allowing us to assign a meaningful importance score to every time point. For time-series classification, TimeSliver outperforms other temporal attribution methods by 11% on 7 distinct synthetic and real-world multivariate time-series datasets. TimeSliver also achieves predictive performance within 2% of state-of-the-art baselines across 26 UEA benchmark datasets, positioning it as a strong and explainable framework for general time-series classification.
STEP-LLM: Generating CAD STEP Models from Natural Language with Large Language Models
Jan 19, 2026Computer-aided design (CAD) is vital to modern manufacturing, yet model creation remains labor-intensive and expertise-heavy. To enable non-experts to translate intuitive design intent into manufacturable artifacts, recent large language models-based text-to-CAD efforts focus on command sequences or script-based formats like CadQuery. However, these formats are kernel-dependent and lack universality for manufacturing. In contrast, the Standard for the Exchange of Product Data (STEP, ISO 10303) file is a widely adopted, neutral boundary representation (B-rep) format directly compatible with manufacturing, but its graph-structured, cross-referenced nature poses unique challenges for auto-regressive LLMs. To address this, we curate a dataset of ~40K STEP-caption pairs and introduce novel preprocessing tailored for the graph-structured format of STEP, including a depth-first search-based reserialization that linearizes cross-references while preserving locality and chain-of-thought(CoT)-style structural annotations that guide global coherence. We integrate retrieval-augmented generation to ground predictions in relevant examples for supervised fine-tuning, and refine generation quality through reinforcement learning with a specific Chamfer Distance-based geometric reward. Experiments demonstrate consistent gains of our STEP-LLM in geometric fidelity over the Text2CAD baseline, with improvements arising from multiple stages of our framework: the RAG module substantially enhances completeness and renderability, the DFS-based reserialization strengthens overall accuracy, and the RL further reduces geometric discrepancy. Both metrics and visual comparisons confirm that STEP-LLM generates shapes with higher fidelity than Text2CAD. These results show the feasibility of LLM-driven STEP model generation from natural language, showing its potential to democratize CAD design for manufacturing.
Missingness-resilient Video-enhanced Multimodal Disfluency Detection
Jun 11, 2024

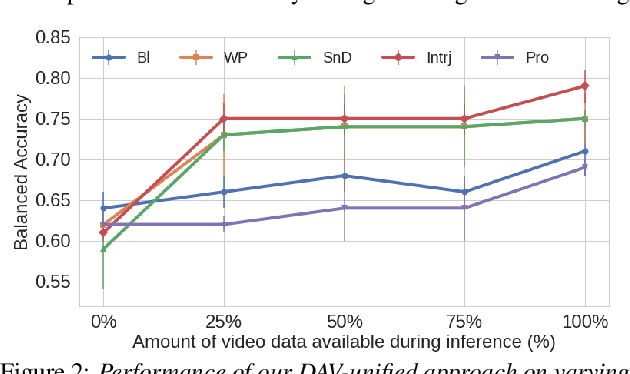
Most existing speech disfluency detection techniques only rely upon acoustic data. In this work, we present a practical multimodal disfluency detection approach that leverages available video data together with audio. We curate an audiovisual dataset and propose a novel fusion technique with unified weight-sharing modality-agnostic encoders to learn the temporal and semantic context. Our resilient design accommodates real-world scenarios where the video modality may sometimes be missing during inference. We also present alternative fusion strategies when both modalities are assured to be complete. In experiments across five disfluency-detection tasks, our unified multimodal approach significantly outperforms Audio-only unimodal methods, yielding an average absolute improvement of 10% (i.e., 10 percentage point increase) when both video and audio modalities are always available, and 7% even when video modality is missing in half of the samples.
Phase-driven Domain Generalizable Learning for Nonstationary Time Series
Feb 05, 2024



Monitoring and recognizing patterns in continuous sensing data is crucial for many practical applications. These real-world time-series data are often nonstationary, characterized by varying statistical and spectral properties over time. This poses a significant challenge in developing learning models that can effectively generalize across different distributions. In this work, based on our observation that nonstationary statistics are intrinsically linked to the phase information, we propose a time-series learning framework, PhASER. It consists of three novel elements: 1) phase augmentation that diversifies non-stationarity while preserving discriminatory semantics, 2) separate feature encoding by viewing time-varying magnitude and phase as independent modalities, and 3) feature broadcasting by incorporating phase with a novel residual connection for inherent regularization to enhance distribution invariant learning. Upon extensive evaluation on 5 datasets from human activity recognition, sleep-stage classification, and gesture recognition against 10 state-of-the-art baseline methods, we demonstrate that PhASER consistently outperforms the best baselines by an average of 5% and up to 13% in some cases. Moreover, PhASER's principles can be applied broadly to boost the generalization ability of existing time series classification models.
Effect of Attention and Self-Supervised Speech Embeddings on Non-Semantic Speech Tasks
Aug 30, 2023



Human emotion understanding is pivotal in making conversational technology mainstream. We view speech emotion understanding as a perception task which is a more realistic setting. With varying contexts (languages, demographics, etc.) different share of people perceive the same speech segment as a non-unanimous emotion. As part of the ACM Multimedia 2023 Computational Paralinguistics ChallengE (ComParE) in the EMotion Share track, we leverage their rich dataset of multilingual speakers and multi-label regression target of 'emotion share' or perception of that emotion. We demonstrate that the training scheme of different foundation models dictates their effectiveness for tasks beyond speech recognition, especially for non-semantic speech tasks like emotion understanding. This is a very complex task due to multilingual speakers, variability in the target labels, and inherent imbalance in the regression dataset. Our results show that HuBERT-Large with a self-attention-based light-weight sequence model provides 4.6% improvement over the reported baseline.