 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMissingness-resilient Video-enhanced Multimodal Disfluency Detection
Paper and Code


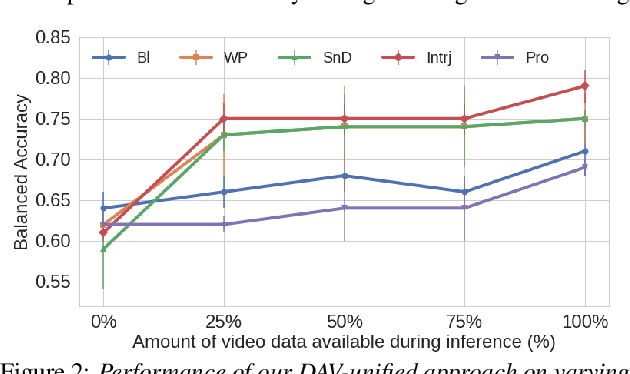
Most existing speech disfluency detection techniques only rely upon acoustic data. In this work, we present a practical multimodal disfluency detection approach that leverages available video data together with audio. We curate an audiovisual dataset and propose a novel fusion technique with unified weight-sharing modality-agnostic encoders to learn the temporal and semantic context. Our resilient design accommodates real-world scenarios where the video modality may sometimes be missing during inference. We also present alternative fusion strategies when both modalities are assured to be complete. In experiments across five disfluency-detection tasks, our unified multimodal approach significantly outperforms Audio-only unimodal methods, yielding an average absolute improvement of 10% (i.e., 10 percentage point increase) when both video and audio modalities are always available, and 7% even when video modality is missing in half of the samples.