 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBarkXAI: A Lightweight Post-Hoc Explainable Method for Tree Species Classification with Quantifiable Concepts
Feb 26, 2025



The precise identification of tree species is fundamental to forestry, conservation, and environmental monitoring. Though many studies have demonstrated that high accuracy can be achieved using bark-based species classification, these models often function as "black boxes", limiting interpretability, trust, and adoption in critical forestry applications. Attribution-based Explainable AI (XAI) methods have been used to address this issue in related works. However, XAI applications are often dependent on local features (such as a head shape or paw in animal applications) and cannot describe global visual features (such as ruggedness or smoothness) that are present in texture-dominant images such as tree bark. Concept-based XAI methods, on the other hand, offer explanations based on global visual features with concepts, but they tend to require large overhead in building external concept image datasets and the concepts can be vague and subjective without good means of precise quantification. To address these challenges, we propose a lightweight post-hoc method to interpret visual models for tree species classification using operators and quantifiable concepts. Our approach eliminates computational overhead, enables the quantification of complex concepts, and evaluates both concept importance and the model's reasoning process. To the best of our knowledge, our work is the first study to explain bark vision models in terms of global visual features with concepts. Using a human-annotated dataset as ground truth, our experiments demonstrate that our method significantly outperforms TCAV and Llama3.2 in concept importance ranking based on Kendall's Tau, highlighting its superior alignment with human perceptions.
Mobile Augmented Reality Framework with Fusional Localization and Pose Estimation
Jan 06, 2025



As a novel way of presenting information, augmented reality (AR) enables people to interact with the physical world in a direct and intuitive way. While there are some mobile AR products implemented with specific hardware at a high cost, the software approaches of AR implementation on mobile platforms(such as smartphones, tablet PC, etc.) are still far from practical use. GPS-based mobile AR systems usually perform poorly due to the inaccurate positioning in the indoor environment. Previous vision-based pose estimation methods need to continuously track predefined markers within a short distance, which greatly degrade user experience. This paper first conducts a comprehensive study of the state-of-the-art AR and localization systems on mobile platforms. Then, we propose an effective indoor mobile AR framework. In the framework, a fusional localization method and a new pose estimation implementation are developed to increase the overall matching rate and thus improving AR display accuracy. Experiments show that our framework has higher performance than approaches purely based on images or Wi-Fi signals. We achieve low average error distances (0.61-0.81m) and accurate matching rates (77%-82%) when the average sampling grid length is set to 0.5m.
Hyperbolic Chamfer Distance for Point Cloud Completion and Beyond
Dec 23, 2024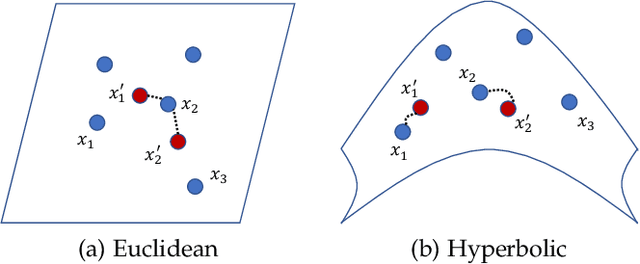
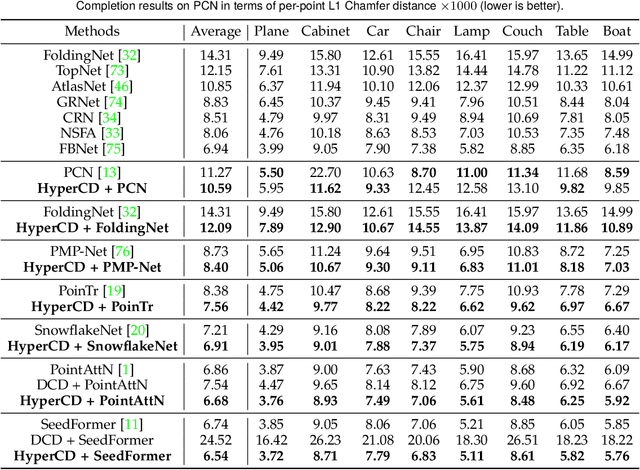
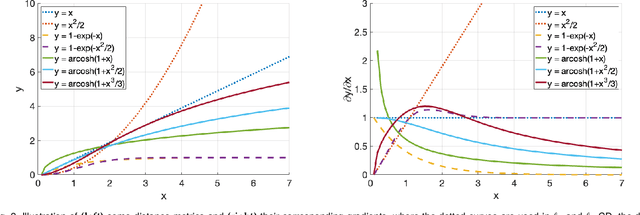
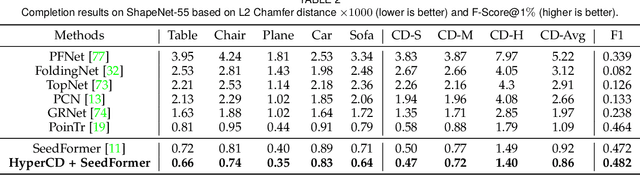
Chamfer Distance (CD) is widely used as a metric to quantify difference between two point clouds. In point cloud completion, Chamfer Distance (CD) is typically used as a loss function in deep learning frameworks. However, it is generally acknowledged within the field that Chamfer Distance (CD) is vulnerable to the presence of outliers, which can consequently lead to the convergence on suboptimal models. In divergence from the existing literature, which largely concentrates on resolving such concerns in the realm of Euclidean space, we put forth a notably uncomplicated yet potent metric specifically designed for point cloud completion tasks: {Hyperbolic Chamfer Distance (HyperCD)}. This metric conducts Chamfer Distance computations within the parameters of hyperbolic space. During the backpropagation process, HyperCD systematically allocates greater weight to matched point pairs exhibiting reduced Euclidean distances. This mechanism facilitates the preservation of accurate point pair matches while permitting the incremental adjustment of suboptimal matches, thereby contributing to enhanced point cloud completion outcomes. Moreover, measure the shape dissimilarity is not solely work for point cloud completion task, we further explore its applications in other generative related tasks, including single image reconstruction from point cloud, and upsampling. We demonstrate state-of-the-art performance on the point cloud completion benchmark datasets, PCN, ShapeNet-55, and ShapeNet-34, and show from visualization that HyperCD can significantly improve the surface smoothness, we also provide the provide experimental results beyond completion task.
Loss Distillation via Gradient Matching for Point Cloud Completion with Weighted Chamfer Distance
Sep 10, 2024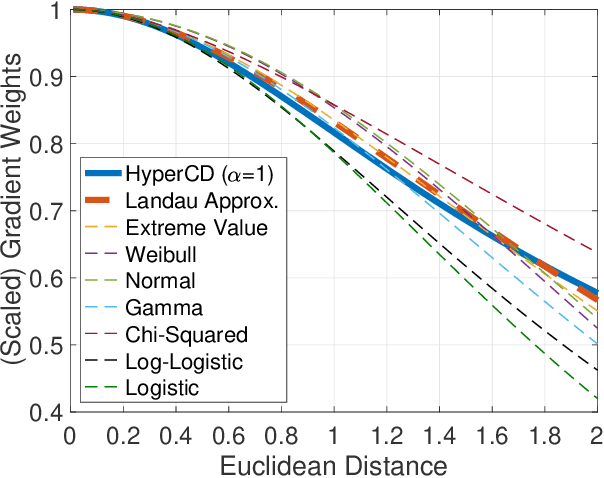
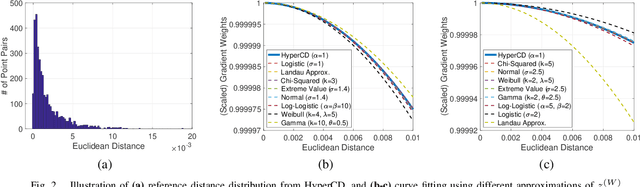


3D point clouds enhanced the robot's ability to perceive the geometrical information of the environments, making it possible for many downstream tasks such as grasp pose detection and scene understanding. The performance of these tasks, though, heavily relies on the quality of data input, as incomplete can lead to poor results and failure cases. Recent training loss functions designed for deep learning-based point cloud completion, such as Chamfer distance (CD) and its variants (\eg HyperCD ), imply a good gradient weighting scheme can significantly boost performance. However, these CD-based loss functions usually require data-related parameter tuning, which can be time-consuming for data-extensive tasks. To address this issue, we aim to find a family of weighted training losses ({\em weighted CD}) that requires no parameter tuning. To this end, we propose a search scheme, {\em Loss Distillation via Gradient Matching}, to find good candidate loss functions by mimicking the learning behavior in backpropagation between HyperCD and weighted CD. Once this is done, we propose a novel bilevel optimization formula to train the backbone network based on the weighted CD loss. We observe that: (1) with proper weighted functions, the weighted CD can always achieve similar performance to HyperCD, and (2) the Landau weighted CD, namely {\em Landau CD}, can outperform HyperCD for point cloud completion and lead to new state-of-the-art results on several benchmark datasets. {\it Our demo code is available at \url{https://github.com/Zhang-VISLab/IROS2024-LossDistillationWeightedCD}.}