 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in the Noise: How Reasoning Models Fail with Contextual Distractors
Jan 12, 2026Recent advances in reasoning models and agentic AI systems have led to an increased reliance on diverse external information. However, this shift introduces input contexts that are inherently noisy, a reality that current sanitized benchmarks fail to capture. We introduce NoisyBench, a comprehensive benchmark that systematically evaluates model robustness across 11 datasets in RAG, reasoning, alignment, and tool-use tasks against diverse noise types, including random documents, irrelevant chat histories, and hard negative distractors. Our evaluation reveals a catastrophic performance drop of up to 80% in state-of-the-art models when faced with contextual distractors. Crucially, we find that agentic workflows often amplify these errors by over-trusting noisy tool outputs, and distractors can trigger emergent misalignment even without adversarial intent. We find that prompting, context engineering, SFT, and outcome-reward only RL fail to ensure robustness; in contrast, our proposed Rationale-Aware Reward (RARE) significantly strengthens resilience by incentivizing the identification of helpful information within noise. Finally, we uncover an inverse scaling trend where increased test-time computation leads to worse performance in noisy settings and demonstrate via attention visualization that models disproportionately focus on distractor tokens, providing vital insights for building the next generation of robust, reasoning-capable agents.
Hybrid Deep Searcher: Integrating Parallel and Sequential Search Reasoning
Aug 26, 2025Large reasoning models (LRMs) have demonstrated strong performance in complex, multi-step reasoning tasks. Existing methods enhance LRMs by sequentially integrating external knowledge retrieval; models iteratively generate queries, retrieve external information, and progressively reason over this information. However, purely sequential querying increases inference latency and context length, diminishing coherence and potentially reducing accuracy. To address these limitations, we introduce HDS-QA (Hybrid Deep Search QA), a synthetic dataset automatically generated from Natural Questions, explicitly designed to train LRMs to distinguish parallelizable from sequential queries. HDS-QA comprises hybrid-hop questions that combine parallelizable independent subqueries (executable simultaneously) and sequentially dependent subqueries (requiring step-by-step resolution), along with synthetic reasoning-querying-retrieval paths involving parallel queries. We fine-tune an LRM using HDS-QA, naming the model HybridDeepSearcher, which outperforms state-of-the-art baselines across multiple benchmarks, notably achieving +15.9 and +11.5 F1 on FanOutQA and a subset of BrowseComp, respectively, both requiring comprehensive and exhaustive search. Experimental results highlight two key advantages: HybridDeepSearcher reaches comparable accuracy with fewer search turns, significantly reducing inference latency, and it effectively scales as more turns are permitted. These results demonstrate the efficiency, scalability, and effectiveness of explicitly training LRMs to leverage hybrid parallel and sequential querying.
Shifting from Ranking to Set Selection for Retrieval Augmented Generation
Jul 09, 2025Retrieval in Retrieval-Augmented Generation(RAG) must ensure that retrieved passages are not only individually relevant but also collectively form a comprehensive set. Existing approaches primarily rerank top-k passages based on their individual relevance, often failing to meet the information needs of complex queries in multi-hop question answering. In this work, we propose a set-wise passage selection approach and introduce SETR, which explicitly identifies the information requirements of a query through Chain-of-Thought reasoning and selects an optimal set of passages that collectively satisfy those requirements. Experiments on multi-hop RAG benchmarks show that SETR outperforms both proprietary LLM-based rerankers and open-source baselines in terms of answer correctness and retrieval quality, providing an effective and efficient alternative to traditional rerankers in RAG systems. The code is available at https://github.com/LGAI-Research/SetR
The CoT Encyclopedia: Analyzing, Predicting, and Controlling how a Reasoning Model will Think
May 15, 2025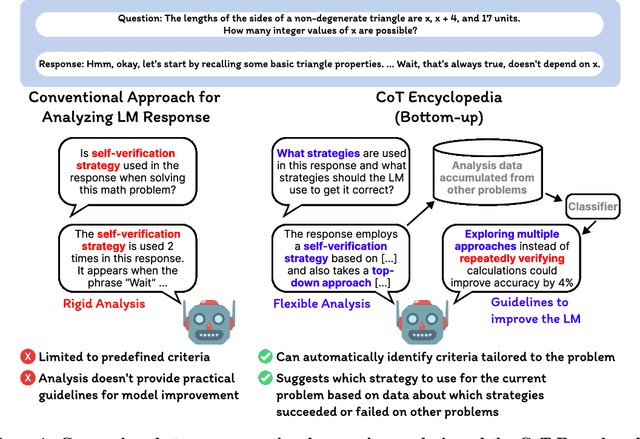
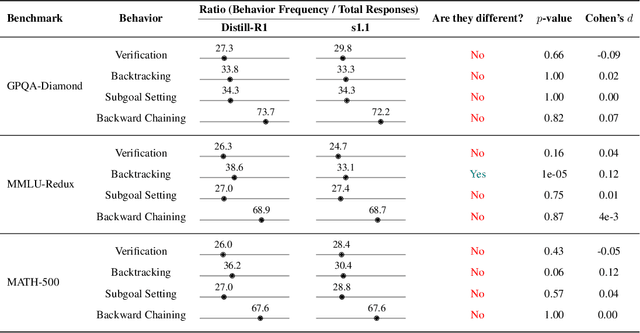
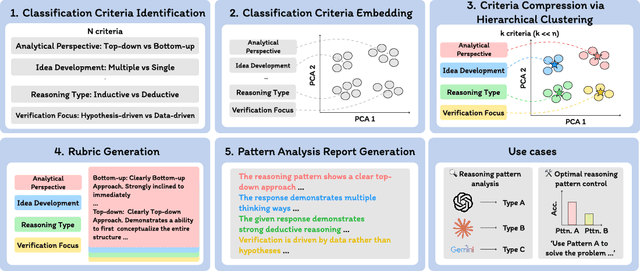
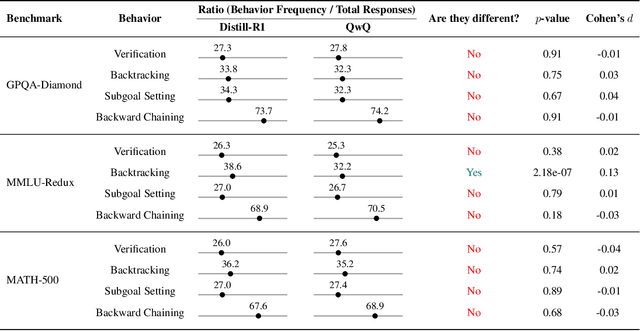
Long chain-of-thought (CoT) is an essential ingredient in effective usage of modern large language models, but our understanding of the reasoning strategies underlying these capabilities remains limited. While some prior works have attempted to categorize CoTs using predefined strategy types, such approaches are constrained by human intuition and fail to capture the full diversity of model behaviors. In this work, we introduce the CoT Encyclopedia, a bottom-up framework for analyzing and steering model reasoning. Our method automatically extracts diverse reasoning criteria from model-generated CoTs, embeds them into a semantic space, clusters them into representative categories, and derives contrastive rubrics to interpret reasoning behavior. Human evaluations show that this framework produces more interpretable and comprehensive analyses than existing methods. Moreover, we demonstrate that this understanding enables performance gains: we can predict which strategy a model is likely to use and guide it toward more effective alternatives. Finally, we provide practical insights, such as that training data format (e.g., free-form vs. multiple-choice) has a far greater impact on reasoning behavior than data domain, underscoring the importance of format-aware model design.
Teaching Metric Distance to Autoregressive Multimodal Foundational Models
Mar 04, 2025As large language models expand beyond natural language to domains such as mathematics, multimodal understanding, and embodied agents, tokens increasingly reflect metric relationships rather than purely linguistic meaning. We introduce DIST2Loss, a distance-aware framework designed to train autoregressive discrete models by leveraging predefined distance relationships among output tokens. At its core, DIST2Loss transforms continuous exponential family distributions derived from inherent distance metrics into discrete, categorical optimization targets compatible with the models' architectures. This approach enables the models to learn and preserve meaningful distance relationships during token generation while maintaining compatibility with existing architectures. Empirical evaluations show consistent performance gains in diverse multimodal applications, including visual grounding, robotic manipulation, generative reward modeling, and image generation using vector-quantized features. These improvements are pronounced in cases of limited training data, highlighting DIST2Loss's effectiveness in resource-constrained settings.
LG AI Research & KAIST at EHRSQL 2024: Self-Training Large Language Models with Pseudo-Labeled Unanswerable Questions for a Reliable Text-to-SQL System on EHRs
May 18, 2024



Text-to-SQL models are pivotal for making Electronic Health Records (EHRs) accessible to healthcare professionals without SQL knowledge. With the advancements in large language models, these systems have become more adept at translating complex questions into SQL queries. Nonetheless, the critical need for reliability in healthcare necessitates these models to accurately identify unanswerable questions or uncertain predictions, preventing misinformation. To address this problem, we present a self-training strategy using pseudo-labeled unanswerable questions to enhance the reliability of text-to-SQL models for EHRs. This approach includes a two-stage training process followed by a filtering method based on the token entropy and query execution. Our methodology's effectiveness is validated by our top performance in the EHRSQL 2024 shared task, showcasing the potential to improve healthcare decision-making through more reliable text-to-SQL systems.
Volcano: Mitigating Multimodal Hallucination through Self-Feedback Guided Revision
Nov 14, 2023Large multimodal models (LMMs) suffer from multimodal hallucination, where they provide incorrect responses misaligned with the given visual information. Recent works have conjectured that one of the reasons behind multimodal hallucination might be due to the vision encoder failing to ground on the image properly. To mitigate this issue, we propose a novel approach that leverages self-feedback as visual cues. Building on this approach, we introduce Volcano, a multimodal self-feedback guided revision model. Volcano generates natural language feedback to its initial response based on the provided visual information and utilizes this feedback to self-revise its initial response. Volcano effectively reduces multimodal hallucination and achieves state-of-the-art on MMHal-Bench, POPE, and GAVIE. It also improves on general multimodal abilities and outperforms previous models on MM-Vet and MMBench. Through a qualitative analysis, we show that Volcano's feedback is properly grounded on the image than the initial response. This indicates that Volcano can provide itself with richer visual information, helping alleviate multimodal hallucination. We publicly release Volcano models of 7B and 13B sizes along with the data and code at https://github.com/kaistAI/Volcano.
FLASK: Fine-grained Language Model Evaluation based on Alignment Skill Sets
Jul 20, 2023
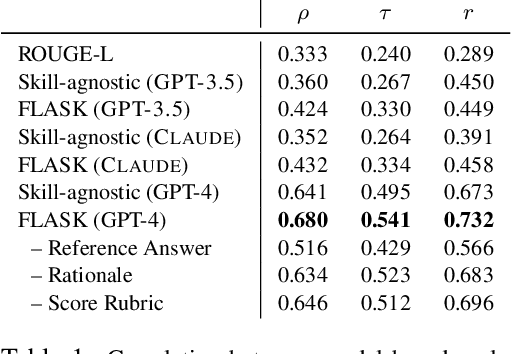

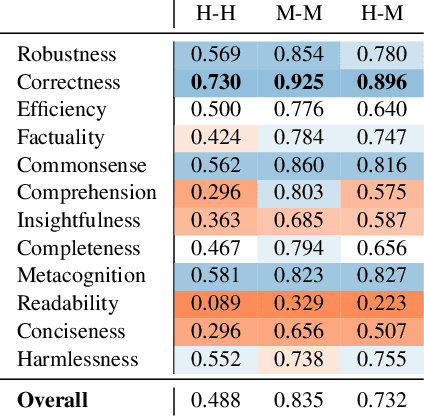
Evaluation of Large Language Models (LLMs) is challenging because aligning to human values requires the composition of multiple skills and the required set of skills varies depending on the instruction. Recent studies have evaluated the performance of LLMs in two ways, (1) automatic evaluation on several independent benchmarks and (2) human or machined-based evaluation giving an overall score to the response. However, both settings are coarse-grained evaluations, not considering the nature of user instructions that require instance-wise skill composition, which limits the interpretation of the true capabilities of LLMs. In this paper, we introduce FLASK (Fine-grained Language Model Evaluation based on Alignment SKill Sets), a fine-grained evaluation protocol that can be used for both model-based and human-based evaluation which decomposes coarse-level scoring to an instance-wise skill set-level. Specifically, we define 12 fine-grained skills needed for LLMs to follow open-ended user instructions and construct an evaluation set by allocating a set of skills for each instance. Additionally, by annotating the target domains and difficulty level for each instance, FLASK provides a holistic view with a comprehensive analysis of a model's performance depending on skill, domain, and difficulty. Through using FLASK, we compare multiple open-sourced and proprietary LLMs and observe highly-correlated findings between model-based and human-based evaluations. FLASK enables developers to more accurately measure the model performance and how it can be improved by analyzing factors that make LLMs proficient in particular skills. For practitioners, FLASK can be used to recommend suitable models for particular situations through comprehensive comparison among various LLMs. We release the evaluation data and code implementation at https://github.com/kaistAI/FLASK.
Zero-Shot Dense Video Captioning by Jointly Optimizing Text and Moment
Jul 11, 2023Dense video captioning, a task of localizing meaningful moments and generating relevant captions for videos, often requires a large, expensive corpus of annotated video segments paired with text. In an effort to minimize the annotation cost, we propose ZeroTA, a novel method for dense video captioning in a zero-shot manner. Our method does not require any videos or annotations for training; instead, it localizes and describes events within each input video at test time by optimizing solely on the input. This is accomplished by introducing a soft moment mask that represents a temporal segment in the video and jointly optimizing it with the prefix parameters of a language model. This joint optimization aligns a frozen language generation model (i.e., GPT-2) with a frozen vision-language contrastive model (i.e., CLIP) by maximizing the matching score between the generated text and a moment within the video. We also introduce a pairwise temporal IoU loss to let a set of soft moment masks capture multiple distinct events within the video. Our method effectively discovers diverse significant events within the video, with the resulting captions appropriately describing these events. The empirical results demonstrate that ZeroTA surpasses zero-shot baselines and even outperforms the state-of-the-art few-shot method on the widely-used benchmark ActivityNet Captions. Moreover, our method shows greater robustness compared to supervised methods when evaluated in out-of-domain scenarios. This research provides insight into the potential of aligning widely-used models, such as language generation models and vision-language models, to unlock a new capability: understanding temporal aspects of videos.
Retrieval of Soft Prompt Enhances Zero-Shot Task Generalization
Oct 11, 2022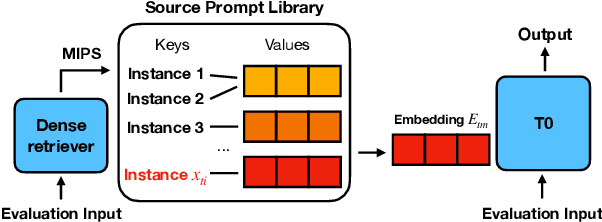
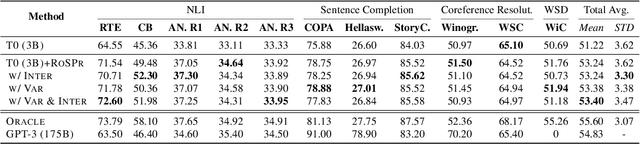
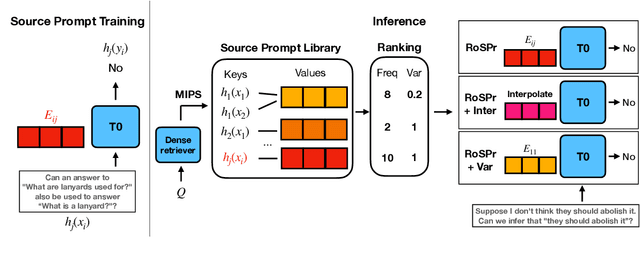
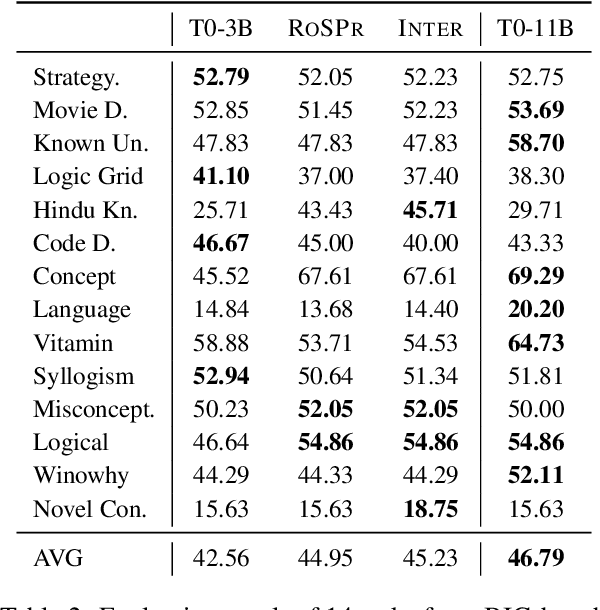
During zero-shot inference with language models (LMs), using hard prompts alone may not be able to fully describe the target task. In this paper, we explore how the retrieval of soft prompts obtained through prompt tuning can assist hard prompts in zero-shot task generalization. Specifically, we train soft prompt embeddings for each prompt through prompt tuning, store the samples of the training instances (hard prompt + input instances) mapped with the prompt embeddings, and retrieve the corresponding prompt embedding of the training instance closest to the query instance during inference. Results show this simple approach enhances the performance of T0 on unseen tasks by outperforming it on 10 out of 11 datasets as well as improving the mean accuracy of T0 on BIG-bench benchmark by 2.39% points while adding only 0.007% additional parameters. Also, using interpolation of multiple embeddings and variance-based ranking further improve accuracy and robustness to different evaluation prompts, widening the performance gap. Finally, we find that retrieving source embeddings trained on similar answer choice formats is more important than those on similar task types. Model checkpoints and code implementation are available at https://github.com/seonghyeonye/RoSPr.