 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSLM: Tree-Structured Language Modeling for Divergent Thinking
Jan 30, 2026Language models generate reasoning sequentially, preventing them from decoupling irrelevant exploration paths during search. We introduce Tree-Structured Language Modeling (TSLM), which uses special tokens to encode branching structure, enabling models to generate and selectively expand multiple search paths within a single generation process. By training on complete search trees including both successful and failed attempts, TSLM learns to internalize systematic exploration without redundant recomputation of shared prefixes. TSLM achieves robust performance and superior inference efficiency by avoiding the multiple independent forward passes required by external search methods. These results suggest a new paradigm of inference-time scaling for robust reasoning, demonstrating that supervised learning on complete tree-structured traces provides an efficient alternative for developing systematic exploration capabilities in language models.
RIM Hand : A Robotic Hand with an Accurate Carpometacarpal Joint and Nitinol-Supported Skeletal Structure
Jan 20, 2026This paper presents the flexible RIM Hand, a biomimetic robotic hand that precisely replicates the carpometacarpal (CMC) joints and employs superelastic Nitinol wires throughout its skeletal framework. By modeling the full carpal-to-metacarpal anatomy, the design enables realistic palm deformation through tendon-driven fingers while enhancing joint restoration and supports skeletal structure with Nitinol-based dorsal extensors. A flexible silicone skin further increases contact friction and contact area, enabling stable grasps for diverse objects. Experiments show that the palm can deform up to 28%, matching human hand flexibility, while achieving more than twice the payload capacity and three times the contact area compared to a rigid palm design. The RIM Hand thus offers improved dexterity, compliance, and anthropomorphism, making it promising for prosthetic and service-robot applications.
GlueNN: gluing patchwise analytic solutions with neural networks
Jan 09, 2026In many problems in physics and engineering, one encounters complicated differential equations with strongly scale-dependent terms for which exact analytical or numerical solutions are not available. A common strategy is to divide the domain into several regions (patches) and simplify the equation in each region. When approximate analytic solutions can be obtained in each patch, they are then matched at the interfaces to construct a global solution. However, this patching procedure can fail to reproduce the correct solution, since the approximate forms may break down near the matching boundaries. In this work, we propose a learning framework in which the integration constants of asymptotic analytic solutions are promoted to scale-dependent functions. By constraining these coefficient functions with the original differential equation over the domain, the network learns a globally valid solution that smoothly interpolates between asymptotic regimes, eliminating the need for arbitrary boundary matching. We demonstrate the effectiveness of this framework in representative problems from chemical kinetics and cosmology, where it accurately reproduces global solutions and outperforms conventional matching procedures.
Beyond Perfect APIs: A Comprehensive Evaluation of LLM Agents Under Real-World API Complexity
Jan 01, 2026We introduce WildAGTEval, a benchmark designed to evaluate large language model (LLM) agents' function-calling capabilities under realistic API complexity. Unlike prior work that assumes an idealized API system and disregards real-world factors such as noisy API outputs, WildAGTEval accounts for two dimensions of real-world complexity: 1. API specification, which includes detailed documentation and usage constraints, and 2. API execution, which captures runtime challenges. Consequently, WildAGTEval offers (i) an API system encompassing 60 distinct complexity scenarios that can be composed into approximately 32K test configurations, and (ii) user-agent interactions for evaluating LLM agents on these scenarios. Using WildAGTEval, we systematically assess several advanced LLMs and observe that most scenarios are challenging, with irrelevant information complexity posing the greatest difficulty and reducing the performance of strong LLMs by 27.3%. Furthermore, our qualitative analysis reveals that LLMs occasionally distort user intent merely to claim task completion, critically affecting user satisfaction.
References Indeed Matter? Reference-Free Preference Optimization for Conversational Query Reformulation
May 10, 2025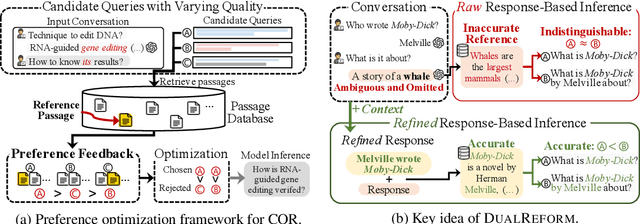
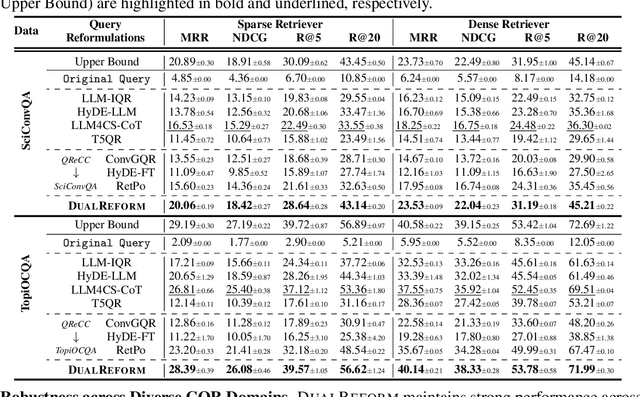
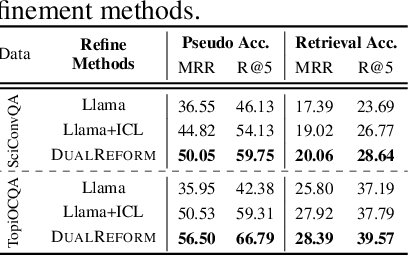
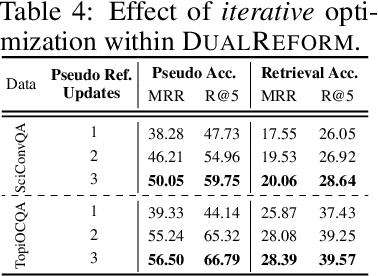
Conversational query reformulation (CQR) has become indispensable for improving retrieval in dialogue-based applications. However, existing approaches typically rely on reference passages for optimization, which are impractical to acquire in real-world scenarios. To address this limitation, we introduce a novel reference-free preference optimization framework DualReform that generates pseudo reference passages from commonly-encountered conversational datasets containing only queries and responses. DualReform attains this goal through two key innovations: (1) response-based inference, where responses serve as proxies to infer pseudo reference passages, and (2) response refinement via the dual-role of CQR, where a CQR model refines responses based on the shared objectives between response refinement and CQR. Despite not relying on reference passages, DualReform achieves 96.9--99.1% of the retrieval accuracy attainable only with reference passages and surpasses the state-of-the-art method by up to 31.6%.
Cognitive Map for Language Models: Optimal Planning via Verbally Representing the World Model
Jun 21, 2024



Language models have demonstrated impressive capabilities across various natural language processing tasks, yet they struggle with planning tasks requiring multi-step simulations. Inspired by human cognitive processes, this paper investigates the optimal planning power of language models that can construct a cognitive map of a given environment. Our experiments demonstrate that cognitive map significantly enhances the performance of both optimal and reachable planning generation ability in the Gridworld path planning task. We observe that our method showcases two key characteristics similar to human cognition: \textbf{generalization of its planning ability to extrapolated environments and rapid adaptation with limited training data.} We hope our findings in the Gridworld task provide insights into modeling human cognitive processes in language models, potentially leading to the development of more advanced and robust systems that better resemble human cognition.
Mélange: Cost Efficient Large Language Model Serving by Exploiting GPU Heterogeneity
Apr 22, 2024



Large language models (LLMs) are increasingly integrated into many online services. However, a major challenge in deploying LLMs is their high cost, due primarily to the use of expensive GPU instances. To address this problem, we find that the significant heterogeneity of GPU types presents an opportunity to increase GPU cost efficiency and reduce deployment costs. The broad and growing market of GPUs creates a diverse option space with varying costs and hardware specifications. Within this space, we show that there is not a linear relationship between GPU cost and performance, and identify three key LLM service characteristics that significantly affect which GPU type is the most cost effective: model request size, request rate, and latency service-level objective (SLO). We then present M\'elange, a framework for navigating the diversity of GPUs and LLM service specifications to derive the most cost-efficient set of GPUs for a given LLM service. We frame the task of GPU selection as a cost-aware bin-packing problem, where GPUs are bins with a capacity and cost, and items are request slices defined by a request size and rate. Upon solution, M\'elange derives the minimal-cost GPU allocation that adheres to a configurable latency SLO. Our evaluations across both real-world and synthetic datasets demonstrate that M\'elange can reduce deployment costs by up to 77% as compared to utilizing only a single GPU type, highlighting the importance of making heterogeneity-aware GPU provisioning decisions for LLM serving. Our source code is publicly available at https://github.com/tyler-griggs/melange-release.
Self-Explore to Avoid the Pit: Improving the Reasoning Capabilities of Language Models with Fine-grained Rewards
Apr 16, 2024



Training on large amounts of rationales (i.e., CoT Fine-tuning) is effective at improving the reasoning capabilities of large language models (LLMs). However, acquiring human-authored rationales or augmenting rationales from proprietary models is costly and not scalable. In this paper, we study the problem of whether LLMs could self-improve their reasoning capabilities. To this end, we propose Self-Explore, where the LLM is tasked to explore the first wrong step (i.e., the first pit) within the rationale and use such signals as fine-grained rewards for further improvement. On the GSM8K and MATH test set, Self-Explore achieves 11.57% and 2.89% improvement on average across three LLMs compared to supervised fine-tuning (SFT). Our code is available at https://github.com/hbin0701/Self-Explore.
Semiparametric Token-Sequence Co-Supervision
Mar 14, 2024



In this work, we introduce a semiparametric token-sequence co-supervision training method. It trains a language model by simultaneously leveraging supervision from the traditional next token prediction loss which is calculated over the parametric token embedding space and the next sequence prediction loss which is calculated over the nonparametric sequence embedding space. The nonparametric sequence embedding space is constructed by a separate language model tasked to condense an input text into a single representative embedding. Our experiments demonstrate that a model trained via both supervisions consistently surpasses models trained via each supervision independently. Analysis suggests that this co-supervision encourages a broader generalization capability across the model. Especially, the robustness of parametric token space which is established during the pretraining step tends to effectively enhance the stability of nonparametric sequence embedding space, a new space established by another language model.
Joint Mechanical and Electrical Adjustment of IRS-aided LEO Satellite MIMO Communications
Jan 12, 2024In this letter, we propose a joint mechanical and electrical adjustment of intelligent reflecting surface (IRS) for the performance improvements of low-earth orbit (LEO) satellite multiple-input multiple-output (MIMO) communications. In particular, we construct a three-dimensional (3D) MIMO channel model for the mechanically-tilted IRS, and consider two types of scenarios with and without the direct path of LEO-ground user link due to the orbital flight. With the aim of maximizing the end-to-end performance, we jointly optimize tilting angle and phase shift of IRS along with the transceiver beamforming, whose performance superiority is verified via simulations.