 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Perfect APIs: A Comprehensive Evaluation of LLM Agents Under Real-World API Complexity
Jan 01, 2026We introduce WildAGTEval, a benchmark designed to evaluate large language model (LLM) agents' function-calling capabilities under realistic API complexity. Unlike prior work that assumes an idealized API system and disregards real-world factors such as noisy API outputs, WildAGTEval accounts for two dimensions of real-world complexity: 1. API specification, which includes detailed documentation and usage constraints, and 2. API execution, which captures runtime challenges. Consequently, WildAGTEval offers (i) an API system encompassing 60 distinct complexity scenarios that can be composed into approximately 32K test configurations, and (ii) user-agent interactions for evaluating LLM agents on these scenarios. Using WildAGTEval, we systematically assess several advanced LLMs and observe that most scenarios are challenging, with irrelevant information complexity posing the greatest difficulty and reducing the performance of strong LLMs by 27.3%. Furthermore, our qualitative analysis reveals that LLMs occasionally distort user intent merely to claim task completion, critically affecting user satisfaction.
MEND: Meta dEmonstratioN Distillation for Efficient and Effective In-Context Learning
Mar 12, 2024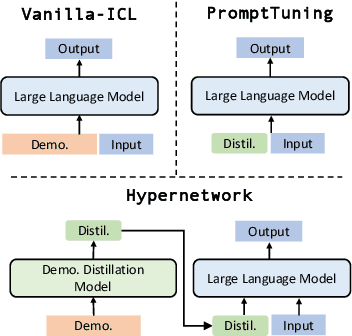
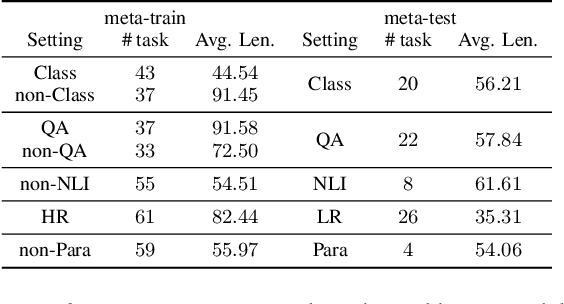
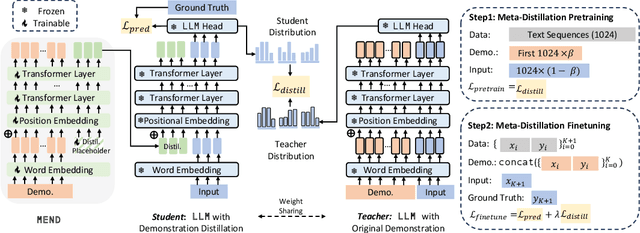
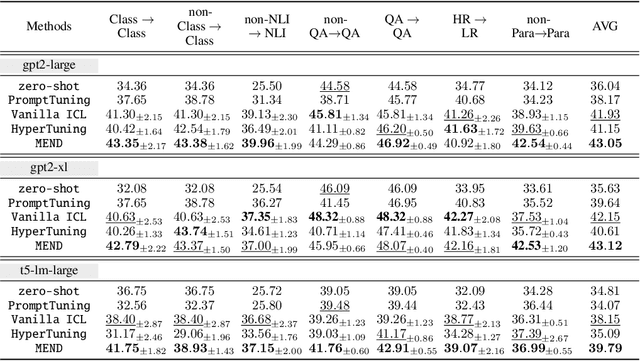
Large Language models (LLMs) have demonstrated impressive in-context learning (ICL) capabilities, where a LLM makes predictions for a given test input together with a few input-output pairs (demonstrations). Nevertheless, the inclusion of demonstrations leads to a quadratic increase in the computational overhead of the self-attention mechanism. Existing solutions attempt to distill lengthy demonstrations into compact vectors. However, they often require task-specific retraining or compromise LLM's in-context learning performance. To mitigate these challenges, we present Meta dEmonstratioN Distillation (MEND), where a language model learns to distill any lengthy demonstrations into vectors without retraining for a new downstream task. We exploit the knowledge distillation to enhance alignment between MEND and LLM, achieving both efficiency and effectiveness simultaneously. MEND is endowed with the meta-knowledge of distilling demonstrations through a two-stage training process, which includes meta-distillation pretraining and fine-tuning. Comprehensive evaluations across seven diverse ICL task partitions using decoder-only (GPT-2) and encoder-decoder (T5) attest to MEND's prowess. It not only matches but often outperforms the Vanilla ICL as well as other state-of-the-art distillation models, while significantly reducing the computational demands. This innovation promises enhanced scalability and efficiency for the practical deployment of large language models
Distilled One-Shot Federated Learning
Sep 17, 2020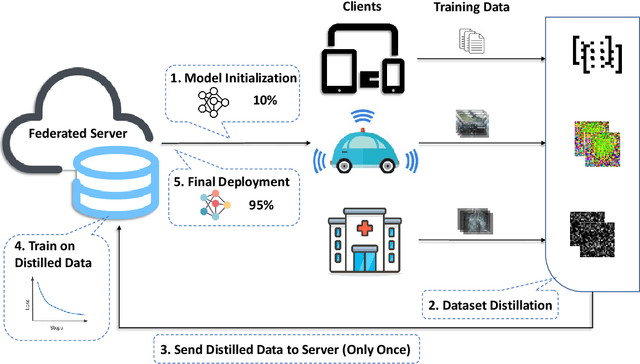
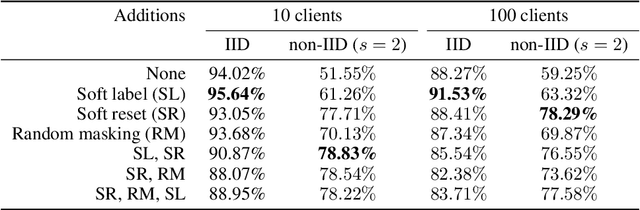
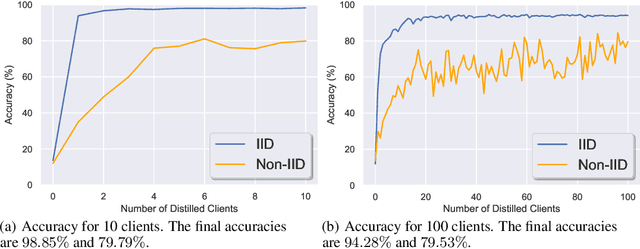
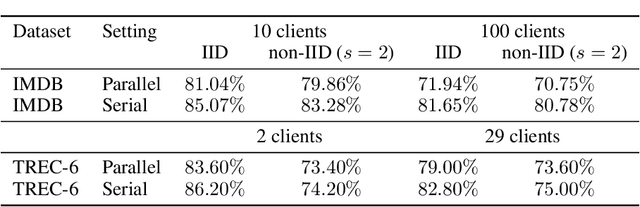
Current federated learning algorithms take tens of communication rounds transmitting unwieldy model weights under ideal circumstances and hundreds when data is poorly distributed. Inspired by recent work on dataset distillation and distributed one-shot learning, we propose Distilled One-Shot Federated Learning, which reduces the number of communication rounds required to train a performant model to only one. Each client distills their private dataset and sends the synthetic data (e.g. images or sentences) to the server. The distilled data look like noise and become useless after model fitting. We empirically show that, in only one round of communication, our method can achieve 96% test accuracy on federated MNIST with LeNet (centralized 99%), 81% on federated IMDB with a customized CNN (centralized 86%), and 84% on federated TREC-6 with a Bi-LSTM (centralized 89%). Using only a few rounds, DOSFL can match the centralized baseline on all three tasks. By evading the need for model-wise updates (i.e., weights, gradients, loss, etc.), the total communication cost of DOSFL is reduced by over an order of magnitude. We believe that DOSFL represents a new direction orthogonal to previous work, towards weight-less and gradient-less federated learning.
Asking Complex Questions with Multi-hop Answer-focused Reasoning
Sep 16, 2020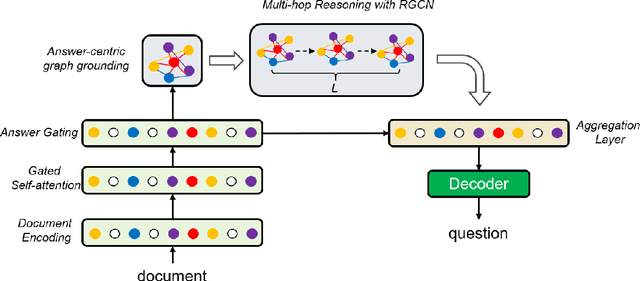
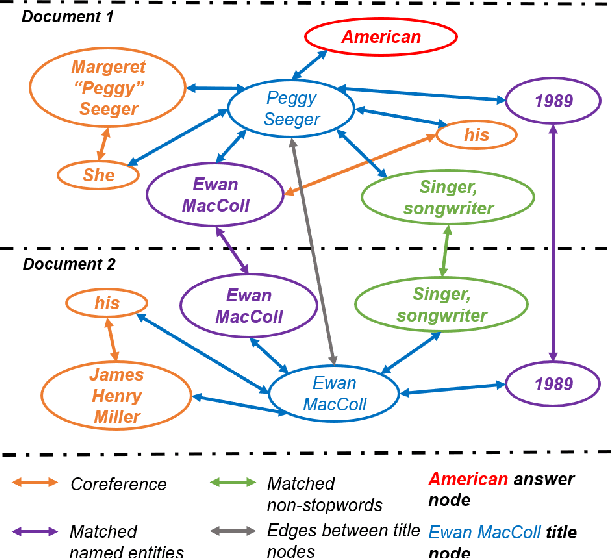
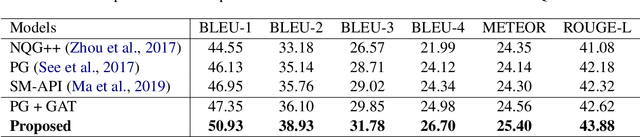
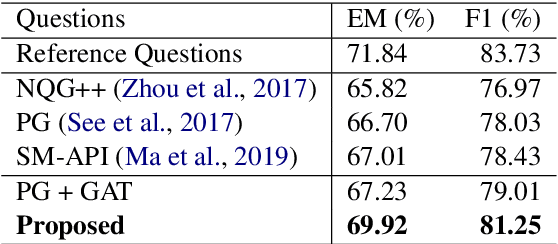
Asking questions from natural language text has attracted increasing attention recently, and several schemes have been proposed with promising results by asking the right question words and copy relevant words from the input to the question. However, most state-of-the-art methods focus on asking simple questions involving single-hop relations. In this paper, we propose a new task called multihop question generation that asks complex and semantically relevant questions by additionally discovering and modeling the multiple entities and their semantic relations given a collection of documents and the corresponding answer 1. To solve the problem, we propose multi-hop answer-focused reasoning on the grounded answer-centric entity graph to include different granularity levels of semantic information including the word-level and document-level semantics of the entities and their semantic relations. Through extensive experiments on the HOTPOTQA dataset, we demonstrate the superiority and effectiveness of our proposed model that serves as a baseline to motivate future work.
A Batch Normalized Inference Network Keeps the KL Vanishing Away
Jun 01, 2020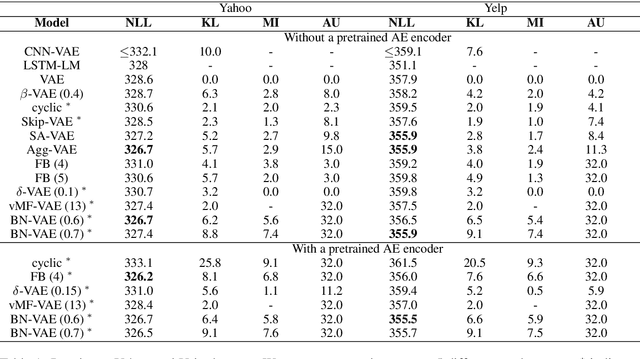
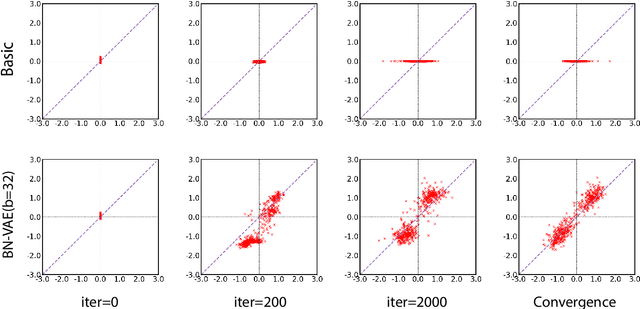
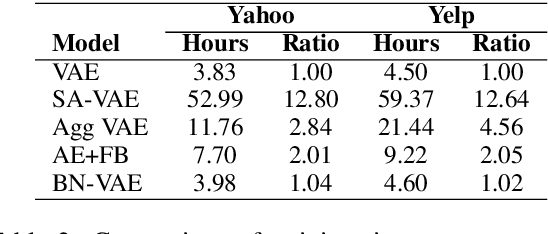
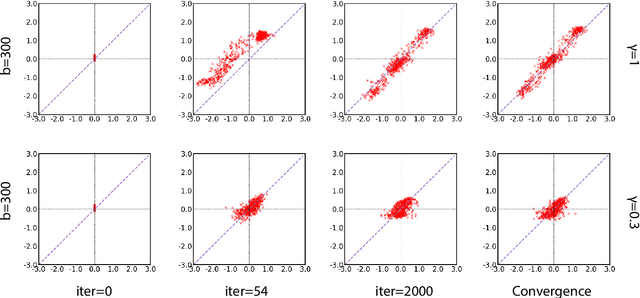
Variational Autoencoder (VAE) is widely used as a generative model to approximate a model's posterior on latent variables by combining the amortized variational inference and deep neural networks. However, when paired with strong autoregressive decoders, VAE often converges to a degenerated local optimum known as "posterior collapse". Previous approaches consider the Kullback Leibler divergence (KL) individual for each datapoint. We propose to let the KL follow a distribution across the whole dataset, and analyze that it is sufficient to prevent posterior collapse by keeping the expectation of the KL's distribution positive. Then we propose Batch Normalized-VAE (BN-VAE), a simple but effective approach to set a lower bound of the expectation by regularizing the distribution of the approximate posterior's parameters. Without introducing any new model component or modifying the objective, our approach can avoid the posterior collapse effectively and efficiently. We further show that the proposed BN-VAE can be extended to conditional VAE (CVAE). Empirically, our approach surpasses strong autoregressive baselines on language modeling, text classification and dialogue generation, and rivals more complex approaches while keeping almost the same training time as VAE.
Improving Question Generation with Sentence-level Semantic Matching and Answer Position Inferring
Feb 03, 2020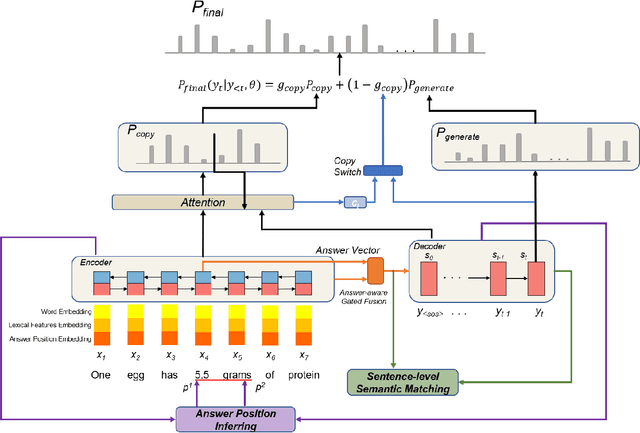

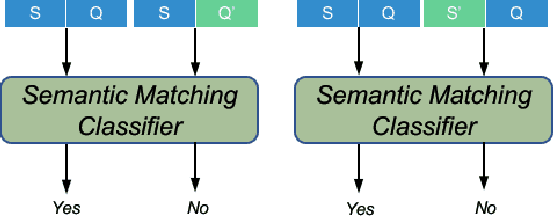
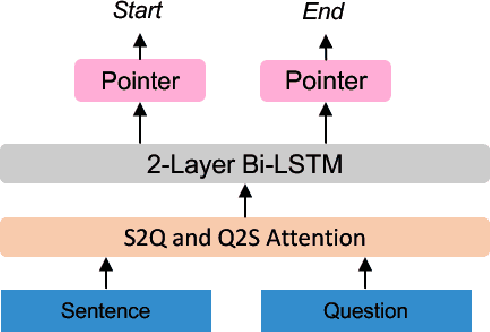
Taking an answer and its context as input, sequence-to-sequence models have made considerable progress on question generation. However, we observe that these approaches often generate wrong question words or keywords and copy answer-irrelevant words from the input. We believe that lacking global question semantics and exploiting answer position-awareness not well are the key root causes. In this paper, we propose a neural question generation model with two concrete modules: sentence-level semantic matching and answer position inferring. Further, we enhance the initial state of the decoder by leveraging the answer-aware gated fusion mechanism. Experimental results demonstrate that our model outperforms the state-of-the-art (SOTA) models on SQuAD and MARCO datasets. Owing to its generality, our work also improves the existing models significantly.
Adaptive Leader-Follower Formation Control and Obstacle Avoidance via Deep Reinforcement Learning
Nov 15, 2019
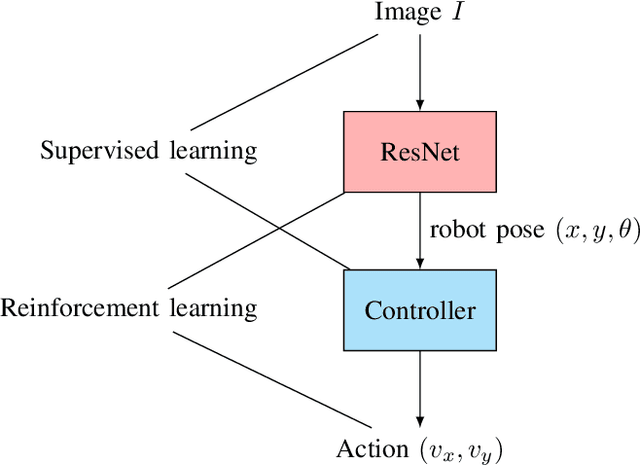
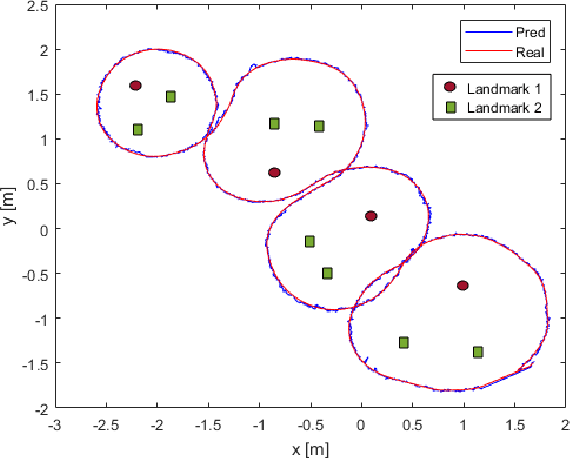
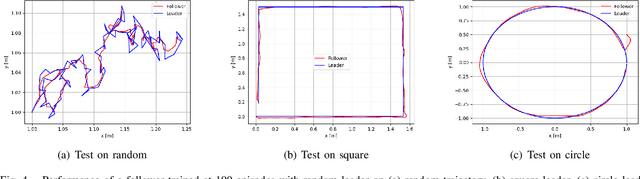
We propose a deep reinforcement learning (DRL) methodology for the tracking, obstacle avoidance, and formation control of nonholonomic robots. By separating vision-based control into a perception module and a controller module, we can train a DRL agent without sophisticated physics or 3D modeling. In addition, the modular framework averts daunting retrains of an image-to-action end-to-end neural network, and provides flexibility in transferring the controller to different robots. First, we train a convolutional neural network (CNN) to accurately localize in an indoor setting with dynamic foreground/background. Then, we design a new DRL algorithm named Momentum Policy Gradient (MPG) for continuous control tasks and prove its convergence. We also show that MPG is robust at tracking varying leader movements and can naturally be extended to problems of formation control. Leveraging reward shaping, features such as collision and obstacle avoidance can be easily integrated into a DRL controller.
* Accepted IROS 2019 paper with minor revisions