 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetering Error Estimation of Fast-Charging Stations Using Charging Data Analytics
Mar 03, 2025



Accurate electric energy metering (EEM) of fast charging stations (FCSs), serving as critical infrastructure in the electric vehicle (EV) industry and as significant carriers of vehicle-to-grid (V2G) technology, is the cornerstone for ensuring fair electric energy transactions. Traditional on-site verification methods, constrained by their high costs and low efficiency, struggle to keep pace with the rapid global expansion of FCSs. In response, this paper adopts a data-driven approach and proposes the measuring performance comparison (MPC) method. By utilizing the estimation value of state-of-charge (SOC) as a medium, MPC establishes comparison chains of EEM performance of multiple FCSs. Therefore, the estimation of EEM errors for FCSs with high efficiency is enabled. Moreover, this paper summarizes the interfering factors of estimation results and establishes corresponding error models and uncertainty models. Also, a method for discriminating whether there are EEM performance defects in FCSs is proposed. Finally, the feasibility of MPC method is validated, with results indicating that for FCSs with an accuracy grade of 2\%, the discriminative accuracy exceeds 95\%. The MPC provides a viable approach for the online monitoring of EEM performance for FCSs, laying a foundation for a fair and just electricity trading market.
AVS-Net: Audio-Visual Scale Net for Self-supervised Monocular Metric Depth Estimation
Dec 02, 2024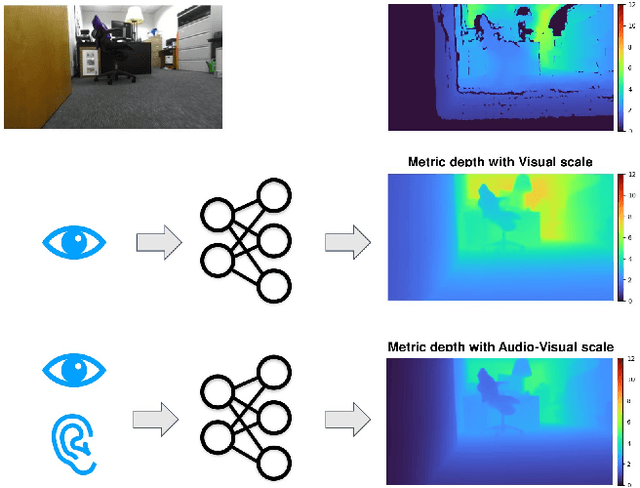

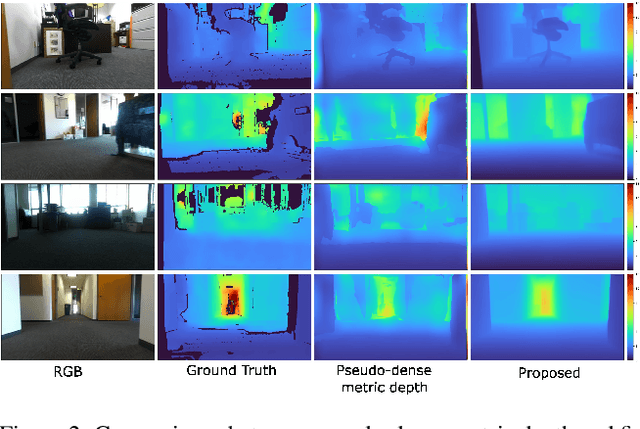
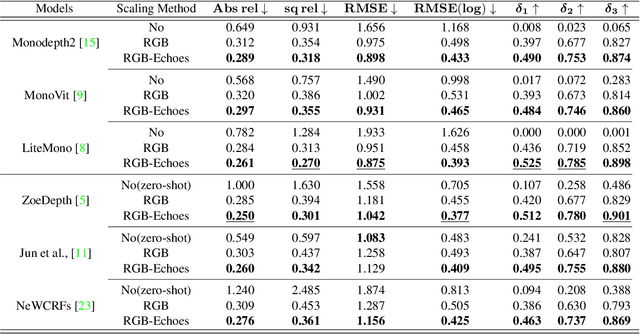
Metric depth prediction from monocular videos suffers from bad generalization between datasets and requires supervised depth data for scale-correct training. Self-supervised training using multi-view reconstruction can benefit from large scale natural videos but not provide correct scale, limiting its benefits. Recently, reflecting audible Echoes off objects is investigated for improved depth prediction and was shown to be sufficient to reconstruct objects at scale even without a visual signal. Because Echoes travel at fixed speed, they have the potential to resolve ambiguities in object scale and appearance. However, predicting depth end-to-end from sound and vision cannot benefit from unsupervised depth prediction approaches, which can process large scale data without sound annotation. In this work we show how Echoes can benefit depth prediction in two ways: When learning metric depth learned from supervised data and as supervisory signal for scale-correct self-supervised training. We show how we can improve the predictions of several state-of-the-art approaches and how the method can scale-correct a self-supervised depth approach.
MEND: Meta dEmonstratioN Distillation for Efficient and Effective In-Context Learning
Mar 12, 2024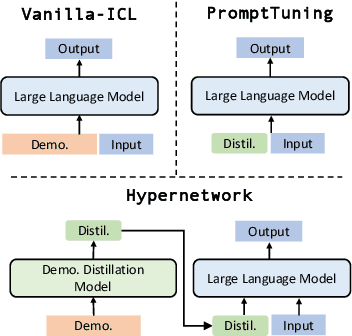
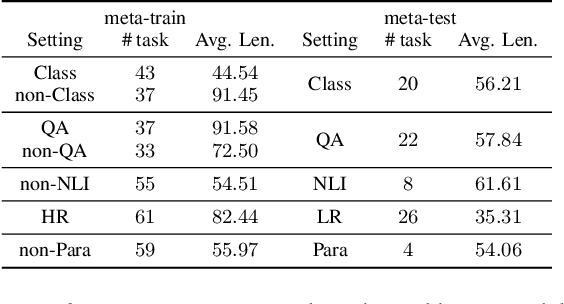
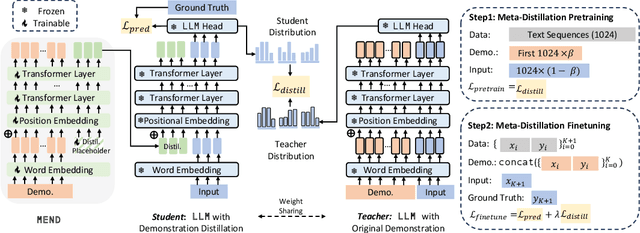
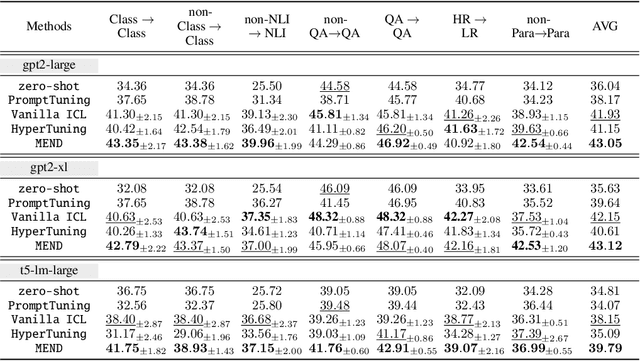
Large Language models (LLMs) have demonstrated impressive in-context learning (ICL) capabilities, where a LLM makes predictions for a given test input together with a few input-output pairs (demonstrations). Nevertheless, the inclusion of demonstrations leads to a quadratic increase in the computational overhead of the self-attention mechanism. Existing solutions attempt to distill lengthy demonstrations into compact vectors. However, they often require task-specific retraining or compromise LLM's in-context learning performance. To mitigate these challenges, we present Meta dEmonstratioN Distillation (MEND), where a language model learns to distill any lengthy demonstrations into vectors without retraining for a new downstream task. We exploit the knowledge distillation to enhance alignment between MEND and LLM, achieving both efficiency and effectiveness simultaneously. MEND is endowed with the meta-knowledge of distilling demonstrations through a two-stage training process, which includes meta-distillation pretraining and fine-tuning. Comprehensive evaluations across seven diverse ICL task partitions using decoder-only (GPT-2) and encoder-decoder (T5) attest to MEND's prowess. It not only matches but often outperforms the Vanilla ICL as well as other state-of-the-art distillation models, while significantly reducing the computational demands. This innovation promises enhanced scalability and efficiency for the practical deployment of large language models
A Self-Healing Magnetic-Array-Type Current Sensor with Data-Driven Identification of Abnormal Magnetic Measurement Units
Feb 18, 2024



Magnetic-array-type current sensors have garnered increasing popularity owing to their notable advantages, including broadband functionality, a large dynamic range, cost-effectiveness, and compact dimensions. However, the susceptibility of the measurement error of one or more magnetic measurement units (MMUs) within the current sensor to drift significantly from the nominal value due to environmental factors poses a potential threat to the measurement accuracy of the current sensor.In light of the need to ensure sustained measurement accuracy over the long term, this paper proposes an innovative self-healing approach rooted in cyber-physics correlation. This approach aims to identify MMUs exhibiting abnormal measurement errors, allowing for the exclusive utilization of the remaining unaffected MMUs in the current measurement process. To achieve this, principal component analysis (PCA) is employed to discern the primary component, arising from fluctuations of the measured current, from the residual component, attributed to the drift in measurement error. This analysis is conducted by scrutinizing the measured data obtained from the MMUs. Subsequently, the squared prediction error (SPE) statistic (also called $Q$ statistic) is deployed to individually identify any MMU displaying abnormal behavior. The experimental results demonstrate the successful online identification of abnormal MMUs without the need for a standard magnetic field sensor. By eliminating the contributions from the identified abnormal MMUs, the accuracy of the current measurement is effectively preserved.
PersonaPKT: Building Personalized Dialogue Agents via Parameter-efficient Knowledge Transfer
Jun 13, 2023Personalized dialogue agents (DAs) powered by large pre-trained language models (PLMs) often rely on explicit persona descriptions to maintain personality consistency. However, such descriptions may not always be available or may pose privacy concerns. To tackle this bottleneck, we introduce PersonaPKT, a lightweight transfer learning approach that can build persona-consistent dialogue models without explicit persona descriptions. By representing each persona as a continuous vector, PersonaPKT learns implicit persona-specific features directly from a small number of dialogue samples produced by the same persona, adding less than 0.1% trainable parameters for each persona on top of the PLM backbone. Empirical results demonstrate that PersonaPKT effectively builds personalized DAs with high storage efficiency, outperforming various baselines in terms of persona consistency while maintaining good response generation quality. In addition, it enhances privacy protection by avoiding explicit persona descriptions. Overall, PersonaPKT is an effective solution for creating personalized DAs that respect user privacy.
Query Expansion and Entity Weighting for Query Reformulation Retrieval in Voice Assistant Systems
Feb 22, 2022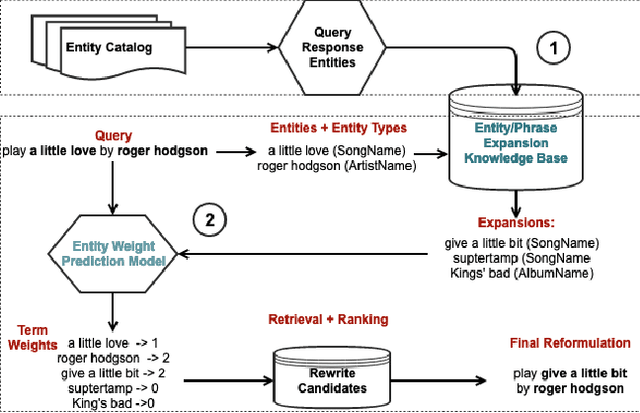
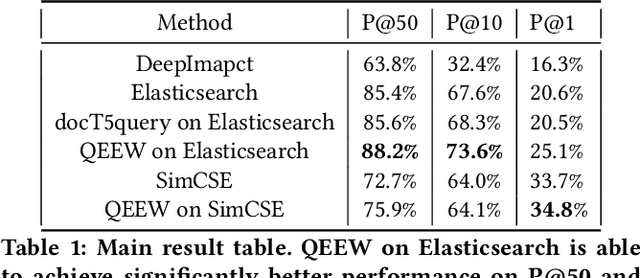
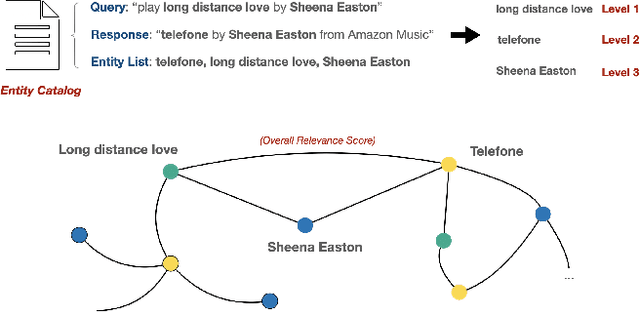
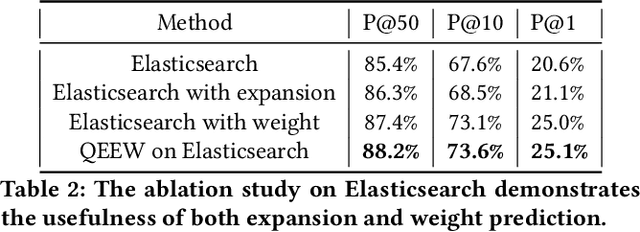
Voice assistants such as Alexa, Siri, and Google Assistant have become increasingly popular worldwide. However, linguistic variations, variability of speech patterns, ambient acoustic conditions, and other such factors are often correlated with the assistants misinterpreting the user's query. In order to provide better customer experience, retrieval based query reformulation (QR) systems are widely used to reformulate those misinterpreted user queries. Current QR systems typically focus on neural retrieval model training or direct entities retrieval for the reformulating. However, these methods rarely focus on query expansion and entity weighting simultaneously, which may limit the scope and accuracy of the query reformulation retrieval. In this work, we propose a novel Query Expansion and Entity Weighting method (QEEW), which leverages the relationships between entities in the entity catalog (consisting of users' queries, assistant's responses, and corresponding entities), to enhance the query reformulation performance. Experiments on Alexa annotated data demonstrate that QEEW improves all top precision metrics, particularly 6% improvement in top10 precision, compared with baselines not using query expansion and weighting; and more than 5% improvement in top10 precision compared with other baselines using query expansion and weighting.