 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIHEval: Evaluating Language Models on Following the Instruction Hierarchy
Feb 12, 2025The instruction hierarchy, which establishes a priority order from system messages to user messages, conversation history, and tool outputs, is essential for ensuring consistent and safe behavior in language models (LMs). Despite its importance, this topic receives limited attention, and there is a lack of comprehensive benchmarks for evaluating models' ability to follow the instruction hierarchy. We bridge this gap by introducing IHEval, a novel benchmark comprising 3,538 examples across nine tasks, covering cases where instructions in different priorities either align or conflict. Our evaluation of popular LMs highlights their struggle to recognize instruction priorities. All evaluated models experience a sharp performance decline when facing conflicting instructions, compared to their original instruction-following performance. Moreover, the most competitive open-source model only achieves 48% accuracy in resolving such conflicts. Our results underscore the need for targeted optimization in the future development of LMs.
Let's Ask GNN: Empowering Large Language Model for Graph In-Context Learning
Oct 09, 2024



Textual Attributed Graphs (TAGs) are crucial for modeling complex real-world systems, yet leveraging large language models (LLMs) for TAGs presents unique challenges due to the gap between sequential text processing and graph-structured data. We introduce AskGNN, a novel approach that bridges this gap by leveraging In-Context Learning (ICL) to integrate graph data and task-specific information into LLMs. AskGNN employs a Graph Neural Network (GNN)-powered structure-enhanced retriever to select labeled nodes across graphs, incorporating complex graph structures and their supervision signals. Our learning-to-retrieve algorithm optimizes the retriever to select example nodes that maximize LLM performance on graph. Experiments across three tasks and seven LLMs demonstrate AskGNN's superior effectiveness in graph task performance, opening new avenues for applying LLMs to graph-structured data without extensive fine-tuning.
Reducing and Exploiting Data Augmentation Noise through Meta Reweighting Contrastive Learning for Text Classification
Sep 26, 2024



Data augmentation has shown its effectiveness in resolving the data-hungry problem and improving model's generalization ability. However, the quality of augmented data can be varied, especially compared with the raw/original data. To boost deep learning models' performance given augmented data/samples in text classification tasks, we propose a novel framework, which leverages both meta learning and contrastive learning techniques as parts of our design for reweighting the augmented samples and refining their feature representations based on their quality. As part of the framework, we propose novel weight-dependent enqueue and dequeue algorithms to utilize augmented samples' weight/quality information effectively. Through experiments, we show that our framework can reasonably cooperate with existing deep learning models (e.g., RoBERTa-base and Text-CNN) and augmentation techniques (e.g., Wordnet and Easydata) for specific supervised learning tasks. Experiment results show that our framework achieves an average of 1.6%, up to 4.3% absolute improvement on Text-CNN encoders and an average of 1.4%, up to 4.4% absolute improvement on RoBERTa-base encoders on seven GLUE benchmark datasets compared with the best baseline. We present an indepth analysis of our framework design, revealing the non-trivial contributions of our network components. Our code is publicly available for better reproducibility.
* IEEE BigData 2021
Empowering Large Language Models for Textual Data Augmentation
Apr 26, 2024



With the capabilities of understanding and executing natural language instructions, Large language models (LLMs) can potentially act as a powerful tool for textual data augmentation. However, the quality of augmented data depends heavily on the augmentation instructions provided, and the effectiveness can fluctuate across different downstream tasks. While manually crafting and selecting instructions can offer some improvement, this approach faces scalability and consistency issues in practice due to the diversity of downstream tasks. In this work, we address these limitations by proposing a new solution, which can automatically generate a large pool of augmentation instructions and select the most suitable task-informed instructions, thereby empowering LLMs to create high-quality augmented data for different downstream tasks. Empirically, the proposed approach consistently generates augmented data with better quality compared to non-LLM and LLM-based data augmentation methods, leading to the best performance on 26 few-shot learning tasks sourced from a wide range of application domains.
Efficient Reinforcement Learning of Task Planners for Robotic Palletization through Iterative Action Masking Learning
Apr 07, 2024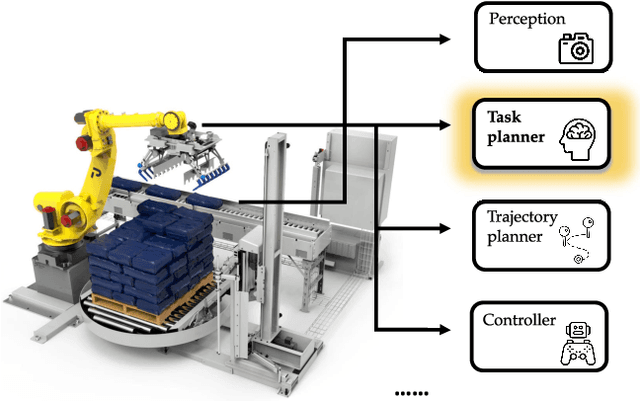
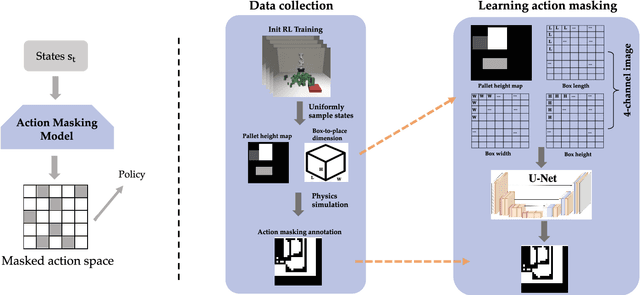
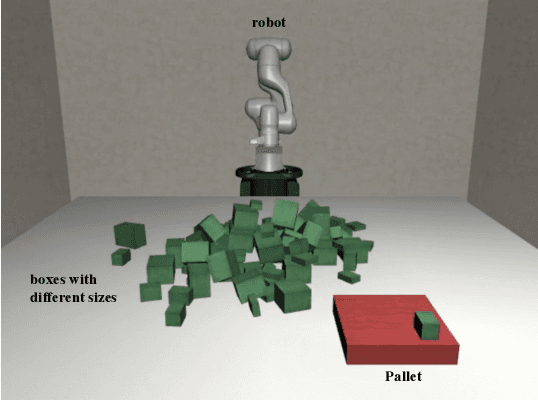
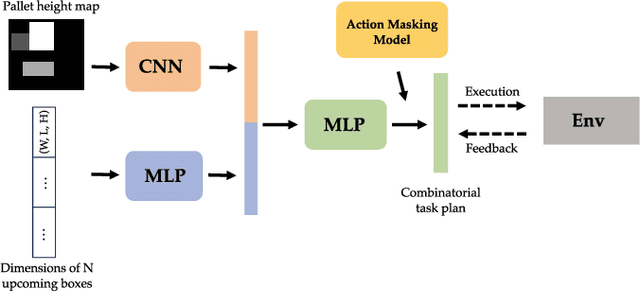
The development of robotic systems for palletization in logistics scenarios is of paramount importance, addressing critical efficiency and precision demands in supply chain management. This paper investigates the application of Reinforcement Learning (RL) in enhancing task planning for such robotic systems. Confronted with the substantial challenge of a vast action space, which is a significant impediment to efficiently apply out-of-the-shelf RL methods, our study introduces a novel method of utilizing supervised learning to iteratively prune and manage the action space effectively. By reducing the complexity of the action space, our approach not only accelerates the learning phase but also ensures the effectiveness and reliability of the task planning in robotic palletization. The experimental results underscore the efficacy of this method, highlighting its potential in improving the performance of RL applications in complex and high-dimensional environments like logistics palletization.
DBPF: A Framework for Efficient and Robust Dynamic Bin-Picking
Mar 25, 2024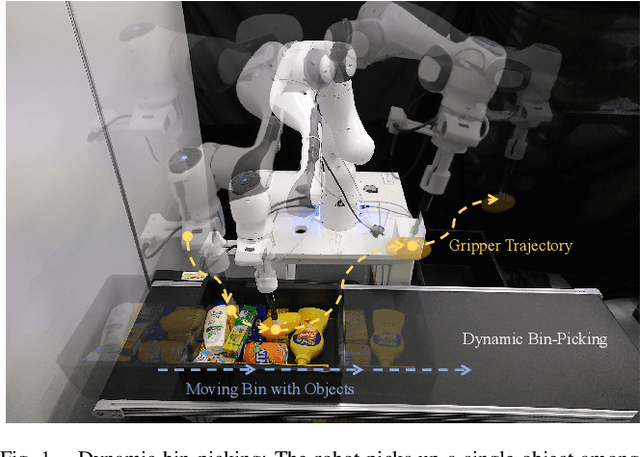
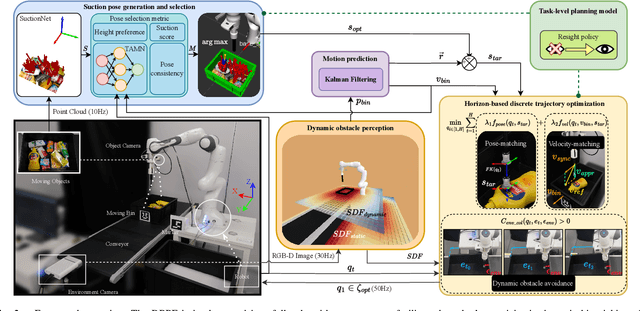
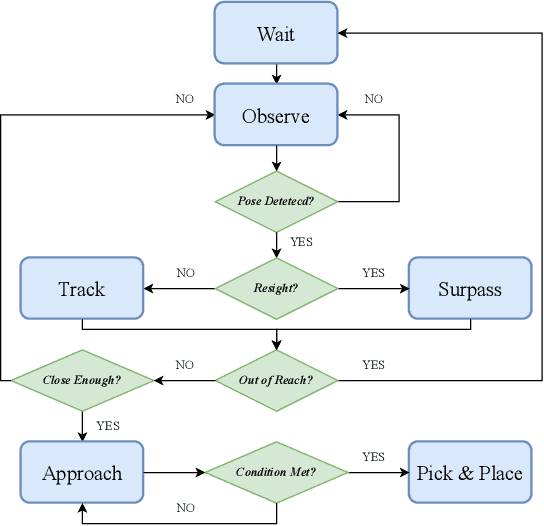

Efficiency and reliability are critical in robotic bin-picking as they directly impact the productivity of automated industrial processes. However, traditional approaches, demanding static objects and fixed collisions, lead to deployment limitations, operational inefficiencies, and process unreliability. This paper introduces a Dynamic Bin-Picking Framework (DBPF) that challenges traditional static assumptions. The DBPF endows the robot with the reactivity to pick multiple moving arbitrary objects while avoiding dynamic obstacles, such as the moving bin. Combined with scene-level pose generation, the proposed pose selection metric leverages the Tendency-Aware Manipulability Network optimizing suction pose determination. Heuristic task-specific designs like velocity-matching, dynamic obstacle avoidance, and the resight policy, enhance the picking success rate and reliability. Empirical experiments demonstrate the importance of these components. Our method achieves an average 84% success rate, surpassing the 60% of the most comparable baseline, crucially, with zero collisions. Further evaluations under diverse dynamic scenarios showcase DBPF's robust performance in dynamic bin-picking. Results suggest that our framework offers a promising solution for efficient and reliable robotic bin-picking under dynamics.
MEND: Meta dEmonstratioN Distillation for Efficient and Effective In-Context Learning
Mar 12, 2024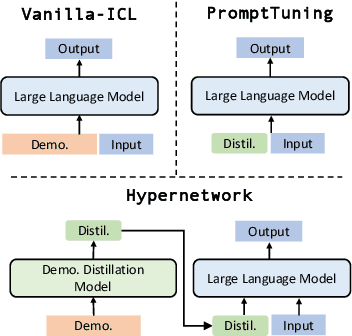
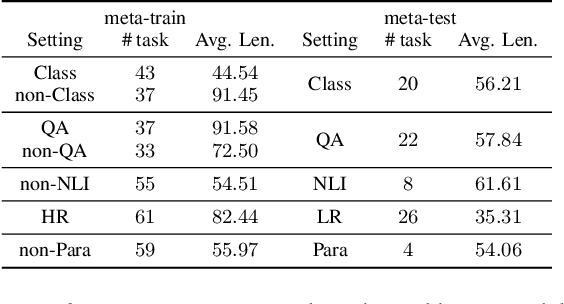
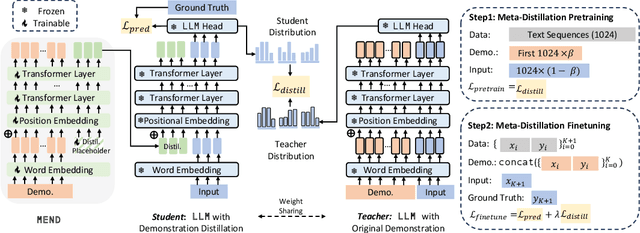
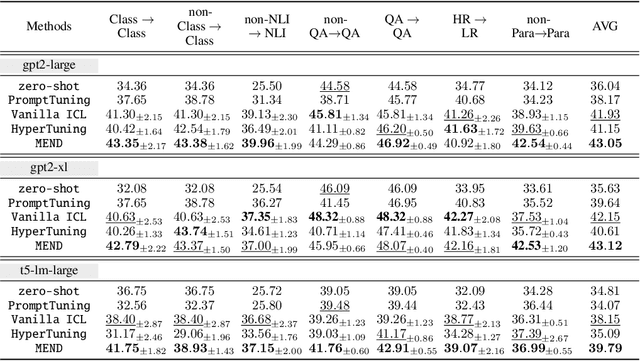
Large Language models (LLMs) have demonstrated impressive in-context learning (ICL) capabilities, where a LLM makes predictions for a given test input together with a few input-output pairs (demonstrations). Nevertheless, the inclusion of demonstrations leads to a quadratic increase in the computational overhead of the self-attention mechanism. Existing solutions attempt to distill lengthy demonstrations into compact vectors. However, they often require task-specific retraining or compromise LLM's in-context learning performance. To mitigate these challenges, we present Meta dEmonstratioN Distillation (MEND), where a language model learns to distill any lengthy demonstrations into vectors without retraining for a new downstream task. We exploit the knowledge distillation to enhance alignment between MEND and LLM, achieving both efficiency and effectiveness simultaneously. MEND is endowed with the meta-knowledge of distilling demonstrations through a two-stage training process, which includes meta-distillation pretraining and fine-tuning. Comprehensive evaluations across seven diverse ICL task partitions using decoder-only (GPT-2) and encoder-decoder (T5) attest to MEND's prowess. It not only matches but often outperforms the Vanilla ICL as well as other state-of-the-art distillation models, while significantly reducing the computational demands. This innovation promises enhanced scalability and efficiency for the practical deployment of large language models
GRENADE: Graph-Centric Language Model for Self-Supervised Representation Learning on Text-Attributed Graphs
Oct 23, 2023



Self-supervised representation learning on text-attributed graphs, which aims to create expressive and generalizable representations for various downstream tasks, has received increasing research attention lately. However, existing methods either struggle to capture the full extent of structural context information or rely on task-specific training labels, which largely hampers their effectiveness and generalizability in practice. To solve the problem of self-supervised representation learning on text-attributed graphs, we develop a novel Graph-Centric Language model -- GRENADE. Specifically, GRENADE exploits the synergistic effect of both pre-trained language model and graph neural network by optimizing with two specialized self-supervised learning algorithms: graph-centric contrastive learning and graph-centric knowledge alignment. The proposed graph-centric self-supervised learning algorithms effectively help GRENADE to capture informative textual semantics as well as structural context information on text-attributed graphs. Through extensive experiments, GRENADE shows its superiority over state-of-the-art methods. Implementation is available at \url{https://github.com/bigheiniu/GRENADE}.
KEPLET: Knowledge-Enhanced Pretrained Language Model with Topic Entity Awareness
May 02, 2023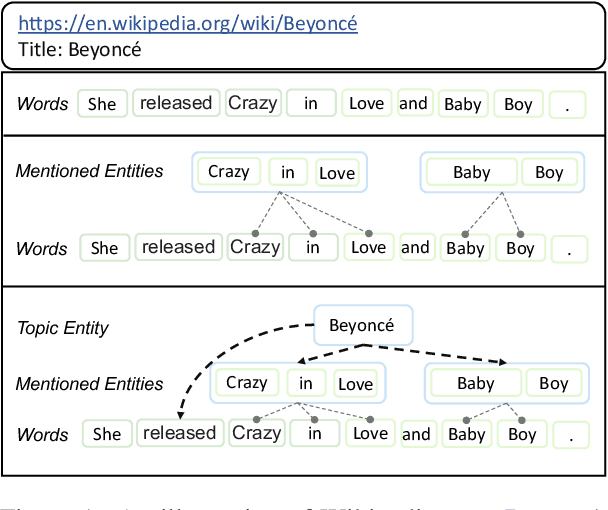
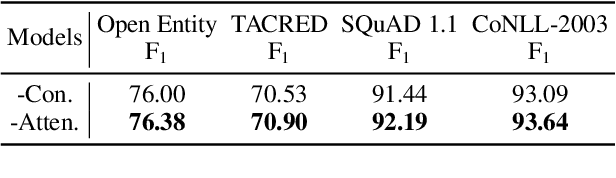
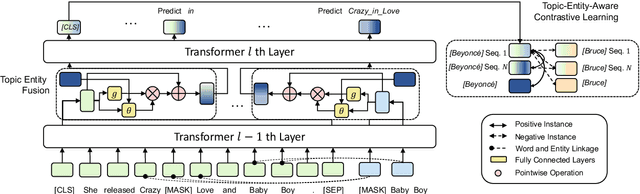
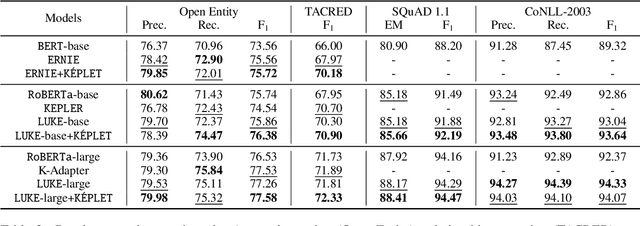
In recent years, Pre-trained Language Models (PLMs) have shown their superiority by pre-training on unstructured text corpus and then fine-tuning on downstream tasks. On entity-rich textual resources like Wikipedia, Knowledge-Enhanced PLMs (KEPLMs) incorporate the interactions between tokens and mentioned entities in pre-training, and are thus more effective on entity-centric tasks such as entity linking and relation classification. Although exploiting Wikipedia's rich structures to some extent, conventional KEPLMs still neglect a unique layout of the corpus where each Wikipedia page is around a topic entity (identified by the page URL and shown in the page title). In this paper, we demonstrate that KEPLMs without incorporating the topic entities will lead to insufficient entity interaction and biased (relation) word semantics. We thus propose KEPLET, a novel Knowledge-Enhanced Pre-trained LanguagE model with Topic entity awareness. In an end-to-end manner, KEPLET identifies where to add the topic entity's information in a Wikipedia sentence, fuses such information into token and mentioned entities representations, and supervises the network learning, through which it takes topic entities back into consideration. Experiments demonstrated the generality and superiority of KEPLET which was applied to two representative KEPLMs, achieving significant improvements on four entity-centric tasks.
Two-Stage Grasping: A New Bin Picking Framework for Small Objects
Mar 07, 2023This paper proposes a novel bin picking framework, two-stage grasping, aiming at precise grasping of cluttered small objects. Object density estimation and rough grasping are conducted in the first stage. Fine segmentation, detection, grasping, and pushing are performed in the second stage. A small object bin picking system has been realized to exhibit the concept of two-stage grasping. Experiments have shown the effectiveness of the proposed framework. Unlike traditional bin picking methods focusing on vision-based grasping planning using classic frameworks, the challenges of picking cluttered small objects can be solved by the proposed new framework with simple vision detection and planning.