 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Perfect APIs: A Comprehensive Evaluation of LLM Agents Under Real-World API Complexity
Jan 01, 2026We introduce WildAGTEval, a benchmark designed to evaluate large language model (LLM) agents' function-calling capabilities under realistic API complexity. Unlike prior work that assumes an idealized API system and disregards real-world factors such as noisy API outputs, WildAGTEval accounts for two dimensions of real-world complexity: 1. API specification, which includes detailed documentation and usage constraints, and 2. API execution, which captures runtime challenges. Consequently, WildAGTEval offers (i) an API system encompassing 60 distinct complexity scenarios that can be composed into approximately 32K test configurations, and (ii) user-agent interactions for evaluating LLM agents on these scenarios. Using WildAGTEval, we systematically assess several advanced LLMs and observe that most scenarios are challenging, with irrelevant information complexity posing the greatest difficulty and reducing the performance of strong LLMs by 27.3%. Furthermore, our qualitative analysis reveals that LLMs occasionally distort user intent merely to claim task completion, critically affecting user satisfaction.
STOC-TOT: Stochastic Tree-of-Thought with Constrained Decoding for Complex Reasoning in Multi-Hop Question Answering
Jul 04, 2024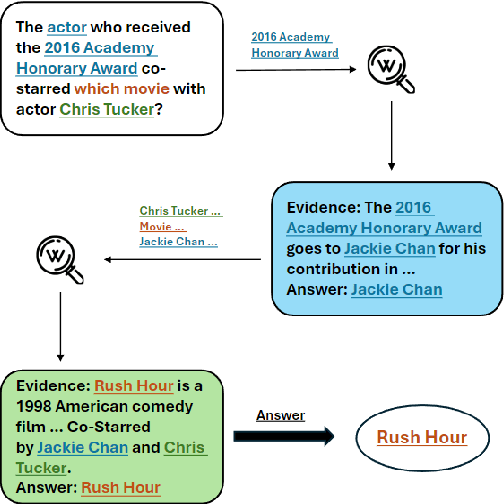
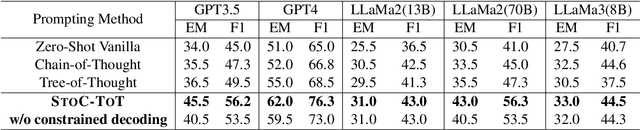
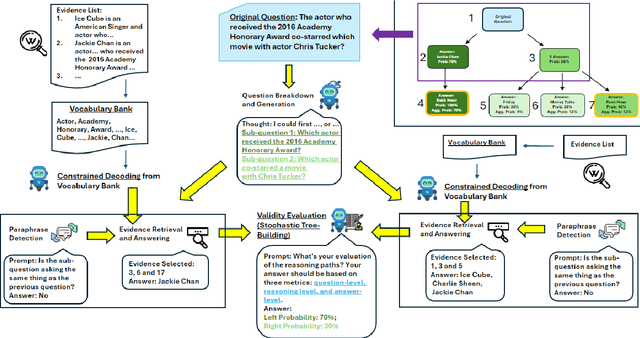
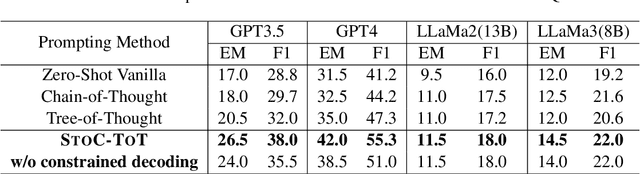
Multi-hop question answering (MHQA) requires a model to retrieve and integrate information from multiple passages to answer a complex question. Recent systems leverage the power of large language models and integrate evidence retrieval with reasoning prompts (e.g., chain-of-thought reasoning) for the MHQA task. However, the complexities in the question types (bridge v.s. comparison questions) and the reasoning types (sequential v.s. parallel reasonings) require more novel and fine-grained prompting methods to enhance the performance of MHQA under the zero-shot setting. In this paper, we propose STOC-TOT, a stochastic tree-of-thought reasoning prompting method with constrained decoding for MHQA and conduct a detailed comparison with other reasoning prompts on different question types and reasoning types. Specifically, we construct a tree-like reasoning structure by prompting the model to break down the original question into smaller sub-questions to form different reasoning paths. In addition, we prompt the model to provide a probability estimation for each reasoning path at each reasoning step. At answer time, we conduct constrained decoding on the model to generate more grounded answers and reduce hallucination. Experiments comparing STOC-TOT with two MHQA datasets and five large language models showed that our framework outperforms other reasoning prompts by a significant margin.
CLICKER: Attention-Based Cross-Lingual Commonsense Knowledge Transfer
Feb 26, 2023Recent advances in cross-lingual commonsense reasoning (CSR) are facilitated by the development of multilingual pre-trained models (mPTMs). While mPTMs show the potential to encode commonsense knowledge for different languages, transferring commonsense knowledge learned in large-scale English corpus to other languages is challenging. To address this problem, we propose the attention-based Cross-LIngual Commonsense Knowledge transfER (CLICKER) framework, which minimizes the performance gaps between English and non-English languages in commonsense question-answering tasks. CLICKER effectively improves commonsense reasoning for non-English languages by differentiating non-commonsense knowledge from commonsense knowledge. Experimental results on public benchmarks demonstrate that CLICKER achieves remarkable improvements in the cross-lingual CSR task for languages other than English.
Query Expansion and Entity Weighting for Query Reformulation Retrieval in Voice Assistant Systems
Feb 22, 2022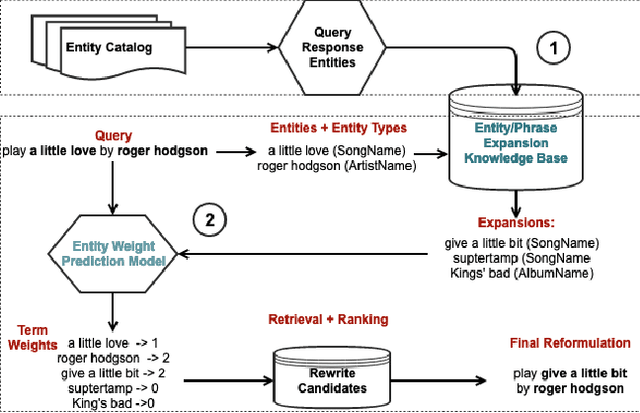
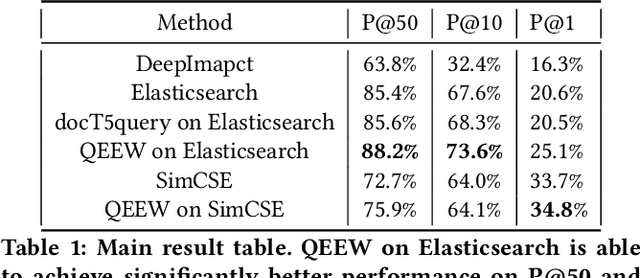
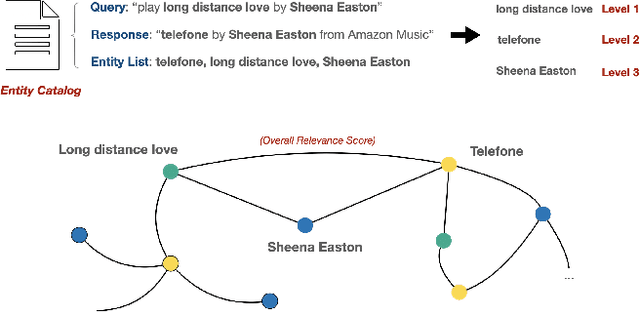
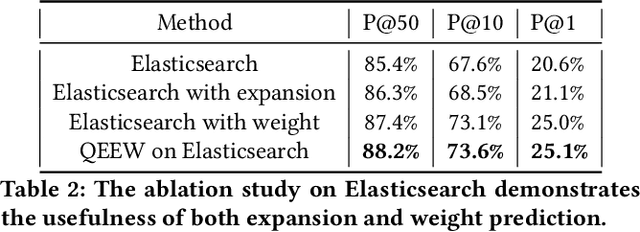
Voice assistants such as Alexa, Siri, and Google Assistant have become increasingly popular worldwide. However, linguistic variations, variability of speech patterns, ambient acoustic conditions, and other such factors are often correlated with the assistants misinterpreting the user's query. In order to provide better customer experience, retrieval based query reformulation (QR) systems are widely used to reformulate those misinterpreted user queries. Current QR systems typically focus on neural retrieval model training or direct entities retrieval for the reformulating. However, these methods rarely focus on query expansion and entity weighting simultaneously, which may limit the scope and accuracy of the query reformulation retrieval. In this work, we propose a novel Query Expansion and Entity Weighting method (QEEW), which leverages the relationships between entities in the entity catalog (consisting of users' queries, assistant's responses, and corresponding entities), to enhance the query reformulation performance. Experiments on Alexa annotated data demonstrate that QEEW improves all top precision metrics, particularly 6% improvement in top10 precision, compared with baselines not using query expansion and weighting; and more than 5% improvement in top10 precision compared with other baselines using query expansion and weighting.
VAE based Text Style Transfer with Pivot Words Enhancement Learning
Dec 06, 2021

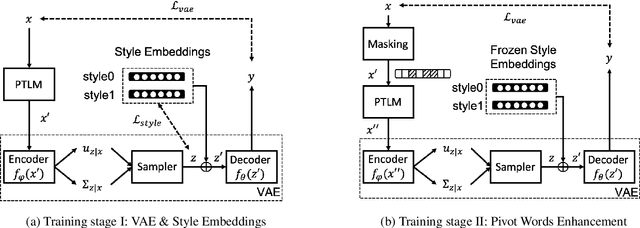
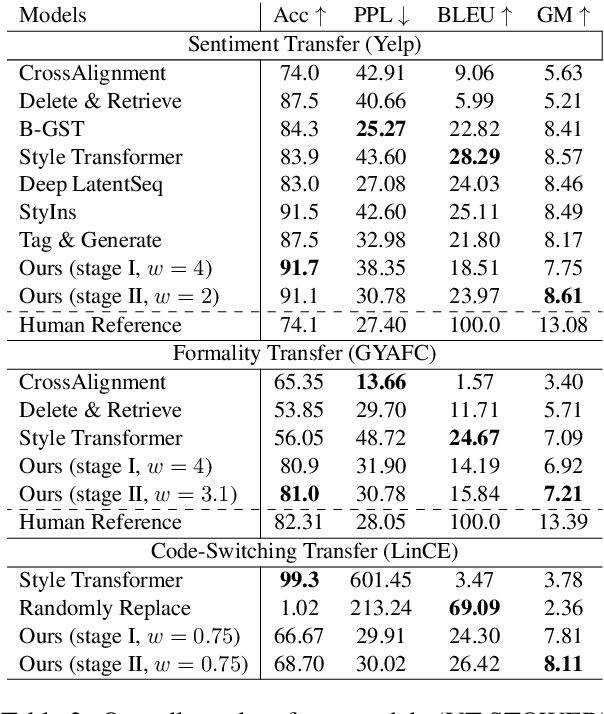
Text Style Transfer (TST) aims to alter the underlying style of the source text to another specific style while keeping the same content. Due to the scarcity of high-quality parallel training data, unsupervised learning has become a trending direction for TST tasks. In this paper, we propose a novel VAE based Text Style Transfer with pivOt Words Enhancement leaRning (VT-STOWER) method which utilizes Variational AutoEncoder (VAE) and external style embeddings to learn semantics and style distribution jointly. Additionally, we introduce pivot words learning, which is applied to learn decisive words for a specific style and thereby further improve the overall performance of the style transfer. The proposed VT-STOWER can be scaled to different TST scenarios given very limited and non-parallel training data with a novel and flexible style strength control mechanism. Experiments demonstrate that the VT-STOWER outperforms the state-of-the-art on sentiment, formality, and code-switching TST tasks.
Learning Relationships between Text, Audio, and Video via Deep Canonical Correlation for Multimodal Language Analysis
Nov 30, 2019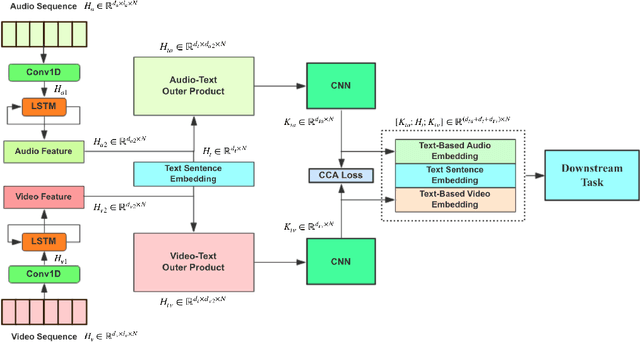
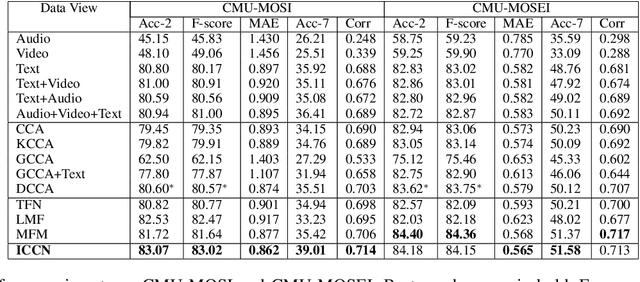
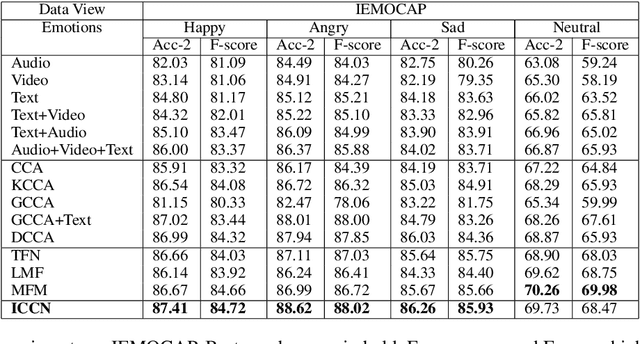
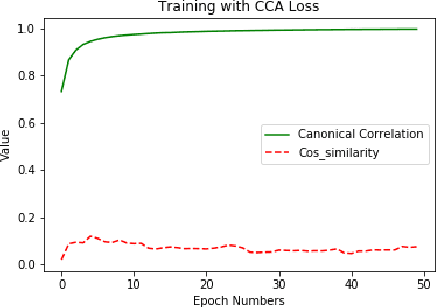
Multimodal language analysis often considers relationships between features based on text and those based on acoustical and visual properties. Text features typically outperform non-text features in sentiment analysis or emotion recognition tasks in part because the text features are derived from advanced language models or word embeddings trained on massive data sources while audio and video features are human-engineered and comparatively underdeveloped. Given that the text, audio, and video are describing the same utterance in different ways, we hypothesize that the multimodal sentiment analysis and emotion recognition can be improved by learning (hidden) correlations between features extracted from the outer product of text and audio (we call this text-based audio) and analogous text-based video. This paper proposes a novel model, the Interaction Canonical Correlation Network (ICCN), to learn such multimodal embeddings. ICCN learns correlations between all three modes via deep canonical correlation analysis (DCCA) and the proposed embeddings are then tested on several benchmark datasets and against other state-of-the-art multimodal embedding algorithms. Empirical results and ablation studies confirm the effectiveness of ICCN in capturing useful information from all three views.
Multi-modal Sentiment Analysis using Deep Canonical Correlation Analysis
Jul 15, 2019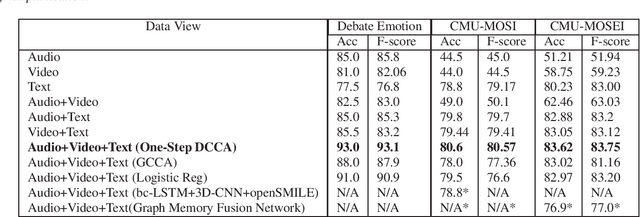
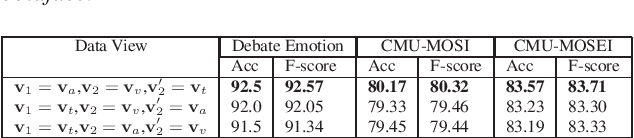
This paper learns multi-modal embeddings from text, audio, and video views/modes of data in order to improve upon down-stream sentiment classification. The experimental framework also allows investigation of the relative contributions of the individual views in the final multi-modal embedding. Individual features derived from the three views are combined into a multi-modal embedding using Deep Canonical Correlation Analysis (DCCA) in two ways i) One-Step DCCA and ii) Two-Step DCCA. This paper learns text embeddings using BERT, the current state-of-the-art in text encoders. We posit that this highly optimized algorithm dominates over the contribution of other views, though each view does contribute to the final result. Classification tasks are carried out on two benchmark datasets and on a new Debate Emotion data set, and together these demonstrate that the one-Step DCCA outperforms the current state-of-the-art in learning multi-modal embeddings.