 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical symptom recognition from patient text: An active learning approach for long-tailed multilabel distributions
Nov 12, 2020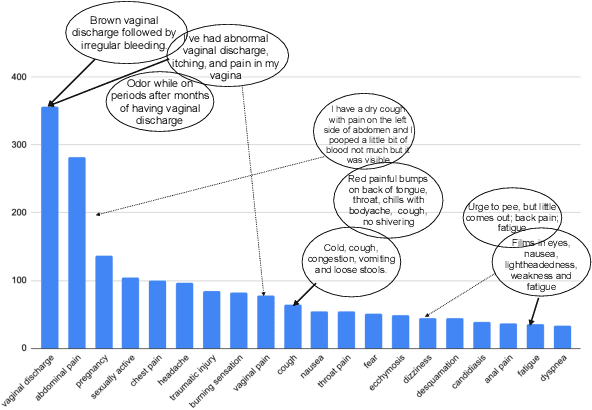
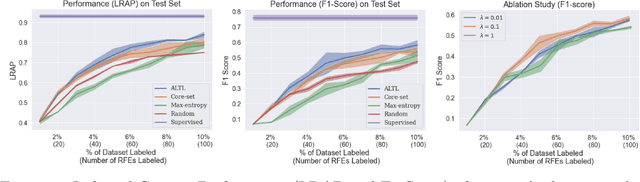
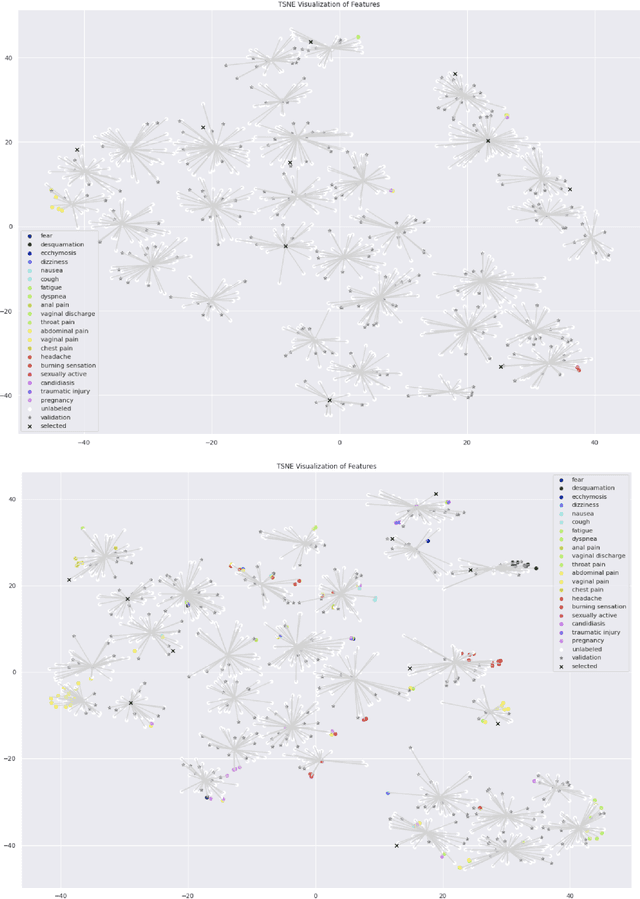
We study the problem of medical symptoms recognition from patient text, for the purposes of gathering pertinent information from the patient (known as history-taking). We introduce an active learning method that leverages underlying structure of a continually refined, learned latent space to select the most informative examples to label. This enables the selection of the most informative examples that progressively increases the coverage on the universe of symptoms via the learned model, despite the long tail in data distribution.
Shallow Domain Adaptive Embeddings for Sentiment Analysis
Aug 16, 2019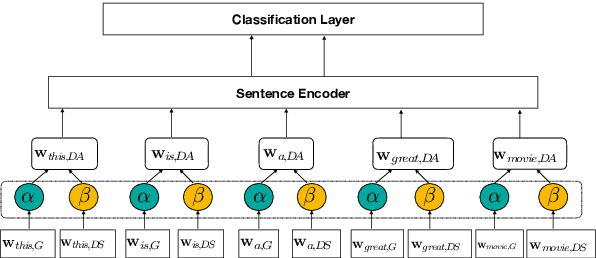

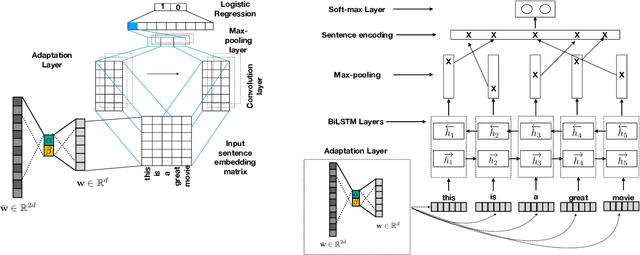
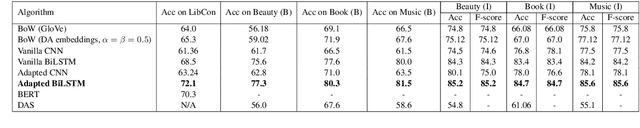
This paper proposes a way to improve the performance of existing algorithms for text classification in domains with strong language semantics. We propose a domain adaptation layer learns weights to combine a generic and a domain specific (DS) word embedding into a domain adapted (DA) embedding. The DA word embeddings are then used as inputs to a generic encoder + classifier framework to perform a downstream task such as classification. This adaptation layer is particularly suited to datasets that are modest in size, and which are, therefore, not ideal candidates for (re)training a deep neural network architecture. Results on binary and multi-class classification tasks using popular encoder architectures, including current state-of-the-art methods (with and without the shallow adaptation layer) show the effectiveness of the proposed approach.
Multi-modal Sentiment Analysis using Deep Canonical Correlation Analysis
Jul 15, 2019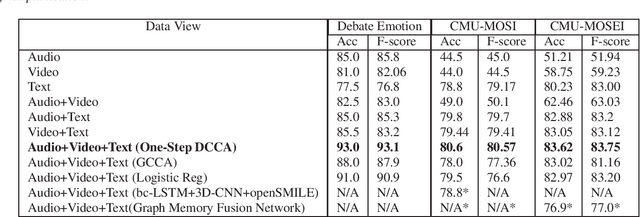
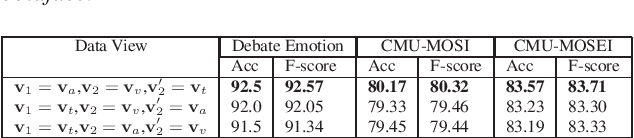
This paper learns multi-modal embeddings from text, audio, and video views/modes of data in order to improve upon down-stream sentiment classification. The experimental framework also allows investigation of the relative contributions of the individual views in the final multi-modal embedding. Individual features derived from the three views are combined into a multi-modal embedding using Deep Canonical Correlation Analysis (DCCA) in two ways i) One-Step DCCA and ii) Two-Step DCCA. This paper learns text embeddings using BERT, the current state-of-the-art in text encoders. We posit that this highly optimized algorithm dominates over the contribution of other views, though each view does contribute to the final result. Classification tasks are carried out on two benchmark datasets and on a new Debate Emotion data set, and together these demonstrate that the one-Step DCCA outperforms the current state-of-the-art in learning multi-modal embeddings.
Domain Adapted Word Embeddings for Improved Sentiment Classification
May 11, 2018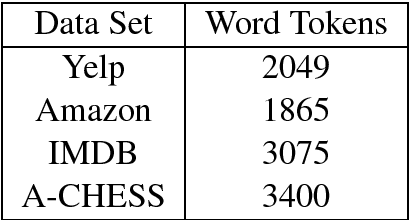
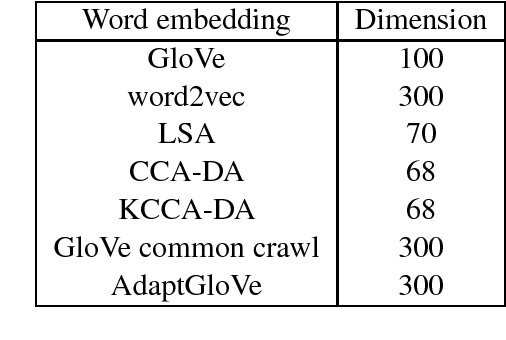
Generic word embeddings are trained on large-scale generic corpora; Domain Specific (DS) word embeddings are trained only on data from a domain of interest. This paper proposes a method to combine the breadth of generic embeddings with the specificity of domain specific embeddings. The resulting embeddings, called Domain Adapted (DA) word embeddings, are formed by aligning corresponding word vectors using Canonical Correlation Analysis (CCA) or the related nonlinear Kernel CCA. Evaluation results on sentiment classification tasks show that the DA embeddings substantially outperform both generic and DS embeddings when used as input features to standard or state-of-the-art sentence encoding algorithms for classification.