 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaEmbed: Semi-supervised Domain Adaptation in the Embedding Space
Jan 23, 2024Semi-supervised domain adaptation (SSDA) presents a critical hurdle in computer vision, especially given the frequent scarcity of labeled data in real-world settings. This scarcity often causes foundation models, trained on extensive datasets, to underperform when applied to new domains. AdaEmbed, our newly proposed methodology for SSDA, offers a promising solution to these challenges. Leveraging the potential of unlabeled data, AdaEmbed facilitates the transfer of knowledge from a labeled source domain to an unlabeled target domain by learning a shared embedding space. By generating accurate and uniform pseudo-labels based on the established embedding space, the model overcomes the limitations of conventional SSDA, thus enhancing performance significantly. Our method's effectiveness is validated through extensive experiments on benchmark datasets such as DomainNet, Office-Home, and VisDA-C, where AdaEmbed consistently outperforms all the baselines, setting a new state of the art for SSDA. With its straightforward implementation and high data efficiency, AdaEmbed stands out as a robust and pragmatic solution for real-world scenarios, where labeled data is scarce. To foster further research and application in this area, we are sharing the codebase of our unified framework for semi-supervised domain adaptation.
Adaptation of Surgical Activity Recognition Models Across Operating Rooms
Jul 07, 2022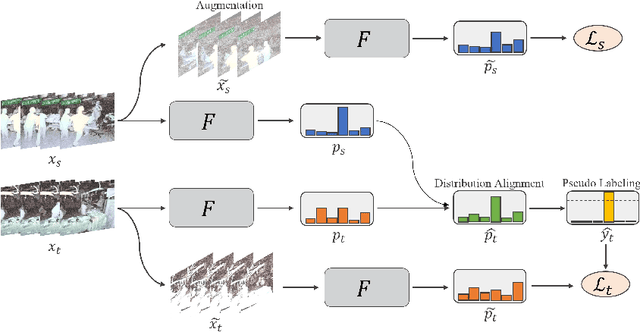

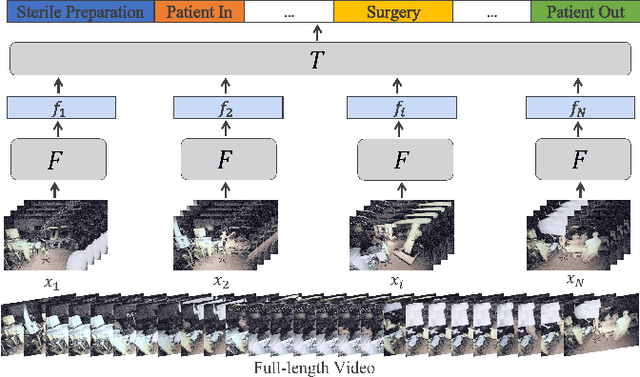

Automatic surgical activity recognition enables more intelligent surgical devices and a more efficient workflow. Integration of such technology in new operating rooms has the potential to improve care delivery to patients and decrease costs. Recent works have achieved a promising performance on surgical activity recognition; however, the lack of generalizability of these models is one of the critical barriers to the wide-scale adoption of this technology. In this work, we study the generalizability of surgical activity recognition models across operating rooms. We propose a new domain adaptation method to improve the performance of the surgical activity recognition model in a new operating room for which we only have unlabeled videos. Our approach generates pseudo labels for unlabeled video clips that it is confident about and trains the model on the augmented version of the clips. We extend our method to a semi-supervised domain adaptation setting where a small portion of the target domain is also labeled. In our experiments, our proposed method consistently outperforms the baselines on a dataset of more than 480 long surgical videos collected from two operating rooms.
Medical symptom recognition from patient text: An active learning approach for long-tailed multilabel distributions
Nov 12, 2020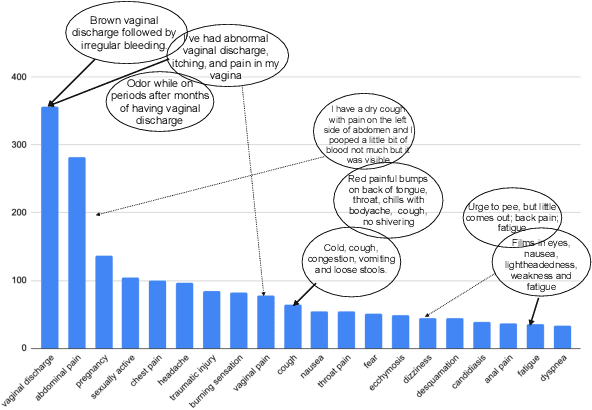
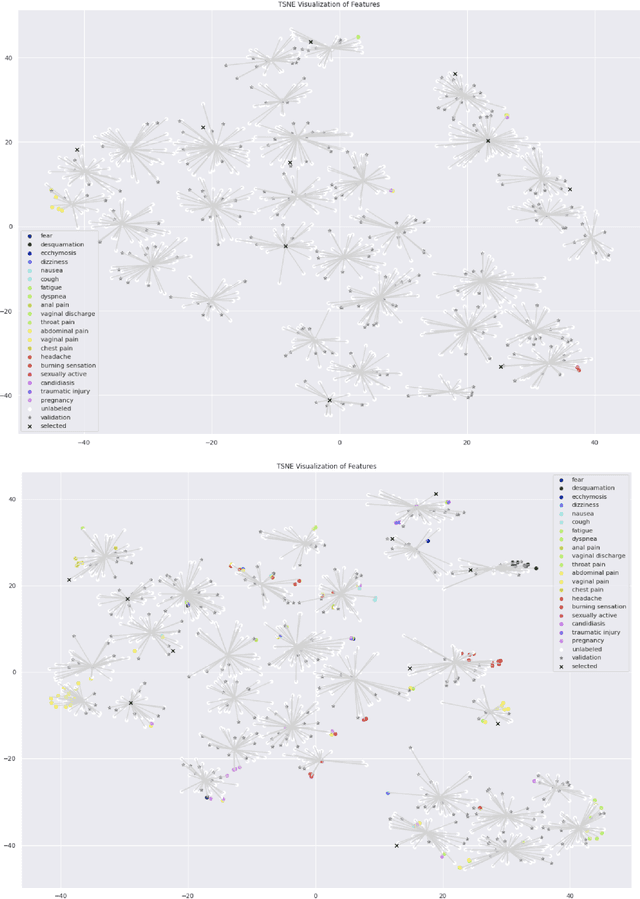
We study the problem of medical symptoms recognition from patient text, for the purposes of gathering pertinent information from the patient (known as history-taking). We introduce an active learning method that leverages underlying structure of a continually refined, learned latent space to select the most informative examples to label. This enables the selection of the most informative examples that progressively increases the coverage on the universe of symptoms via the learned model, despite the long tail in data distribution.
Adversarial Representation Active Learning
Dec 20, 2019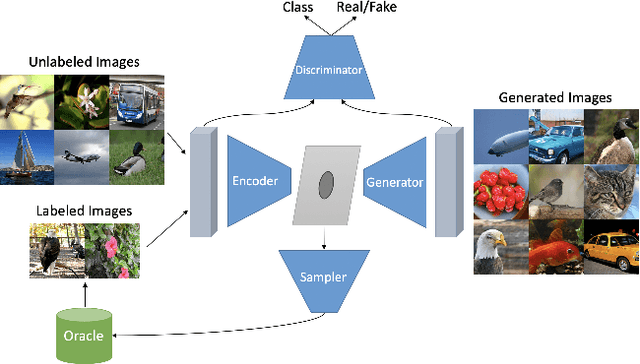
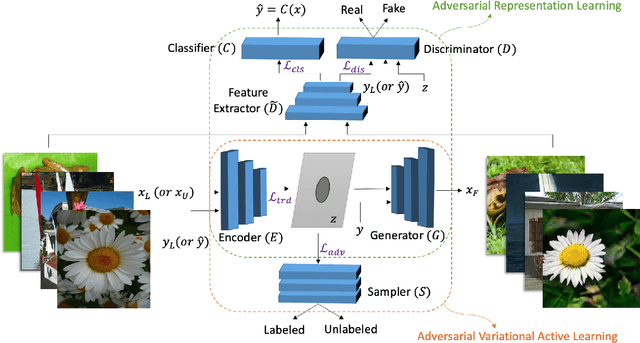
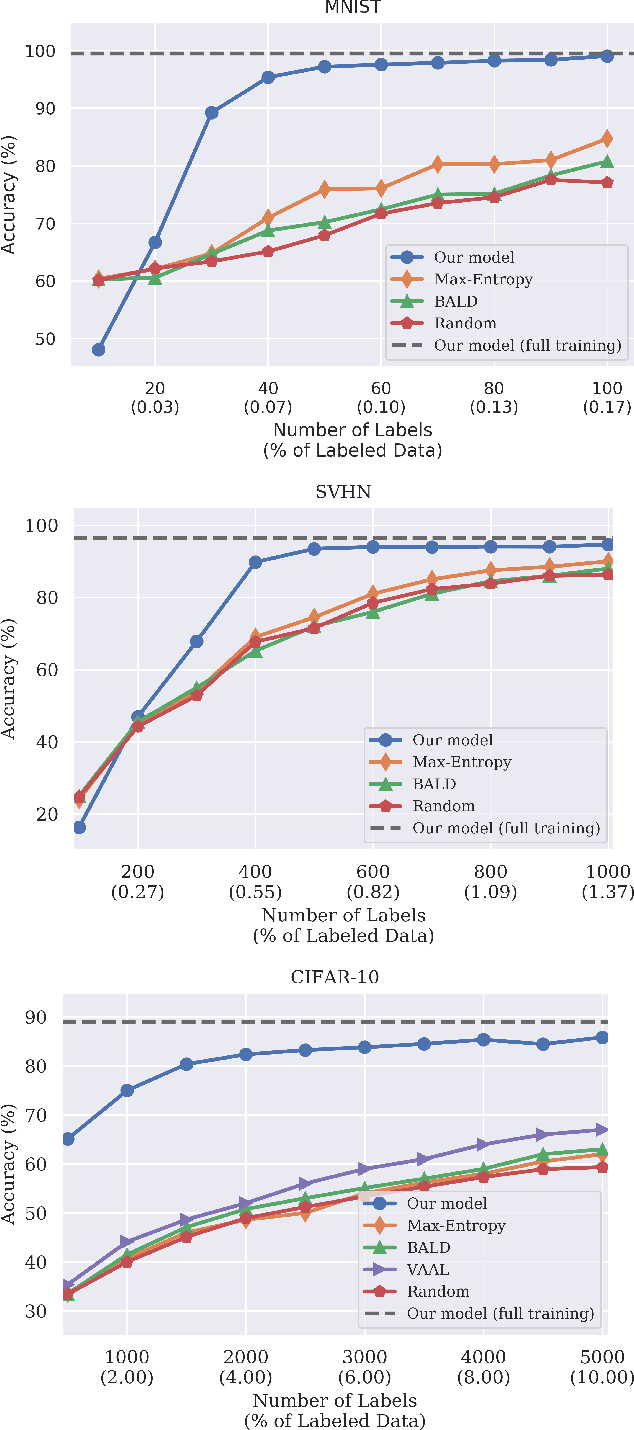
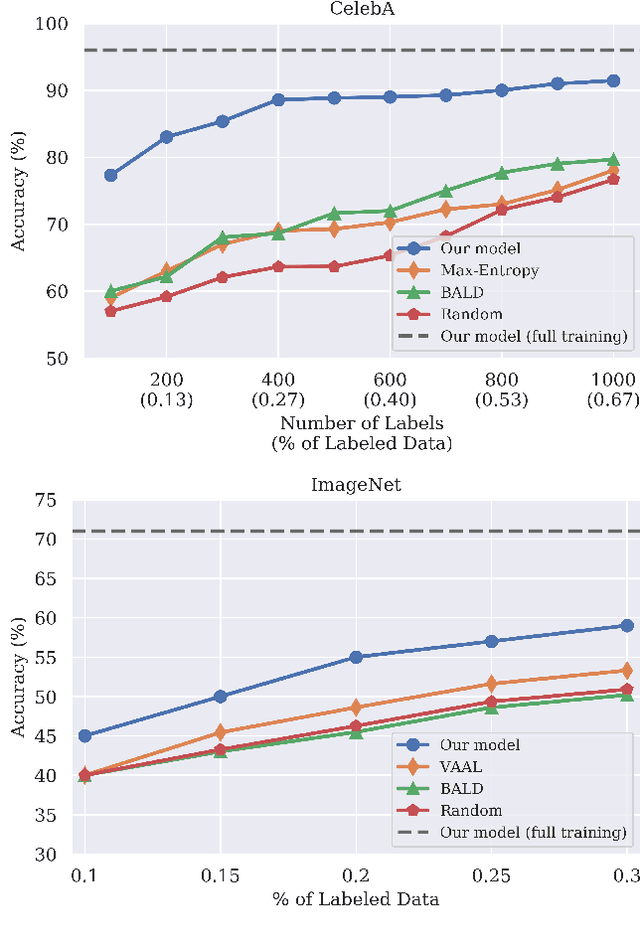
Active learning aims to develop label-efficient algorithms by querying the most informative samples to be labeled by an oracle. The design of efficient training methods that require fewer labels is an important research direction that allows more effective use of computational and human resources for labeling and training deep neural networks. In this work, we demonstrate how we can use recent advances in deep generative models, to outperform the state-of-the-art in achieving the highest classification accuracy using as few labels as possible. Unlike previous approaches, our approach uses not only labeled images to train the classifier but also unlabeled images and generated images for co-training the whole model. Our experiments show that the proposed method significantly outperforms existing approaches in active learning on a wide range of datasets (MNIST, CIFAR-10, SVHN, CelebA, and ImageNet).
OBTAIN: Real-Time Beat Tracking in Audio Signals
Oct 27, 2017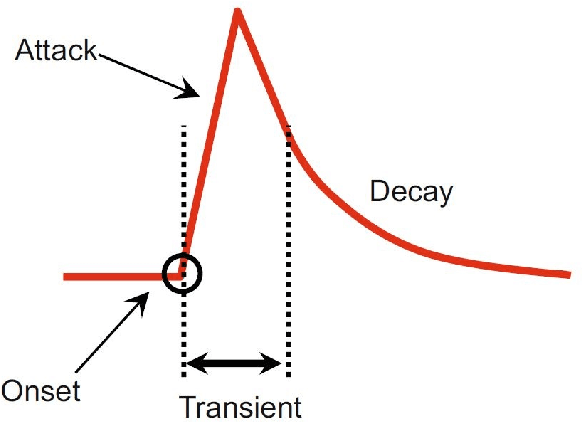
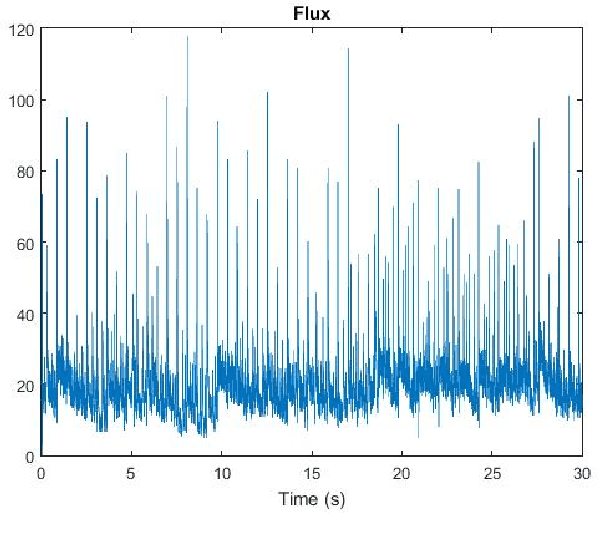
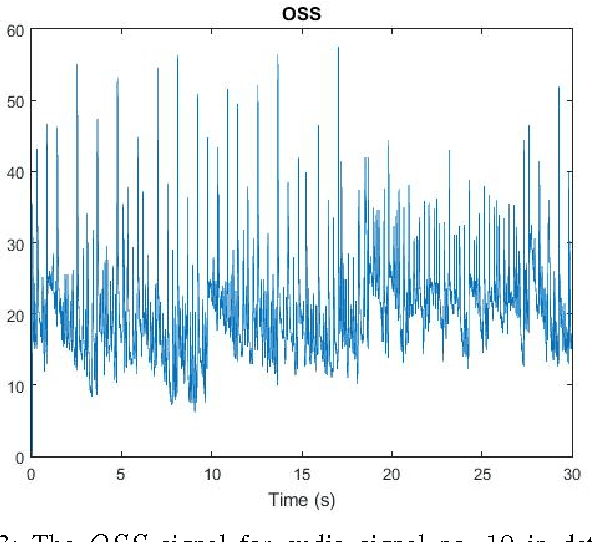
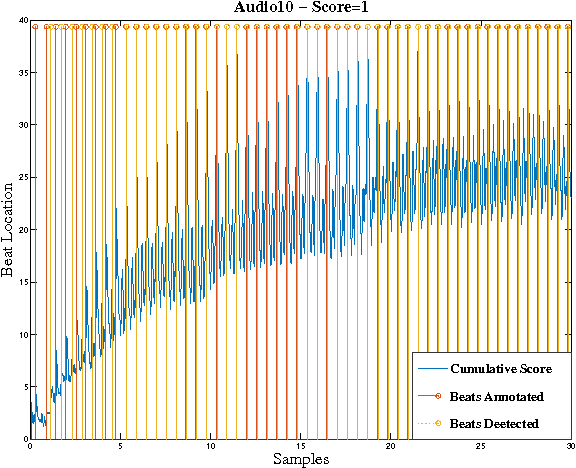
In this paper, we design a system in order to perform the real-time beat tracking for an audio signal. We use Onset Strength Signal (OSS) to detect the onsets and estimate the tempos. Then, we form Cumulative Beat Strength Signal (CBSS) by taking advantage of OSS and estimated tempos. Next, we perform peak detection by extracting the periodic sequence of beats among all CBSS peaks. In simulations, we can see that our proposed algorithm, Online Beat TrAckINg (OBTAIN), outperforms state-of-art results in terms of prediction accuracy while maintaining comparable and practical computational complexity. The real-time performance is tractable visually as illustrated in the simulations.