 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShallow Domain Adaptive Embeddings for Sentiment Analysis
Paper and Code
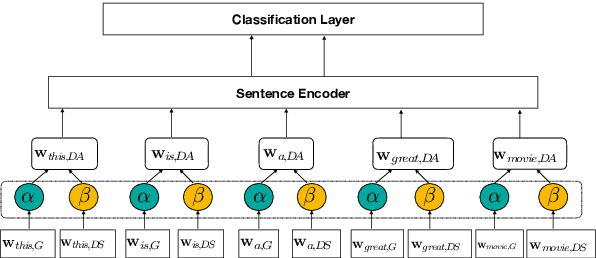

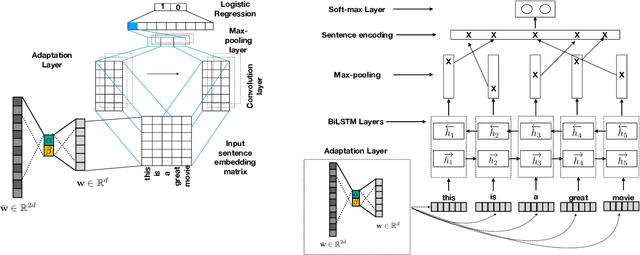
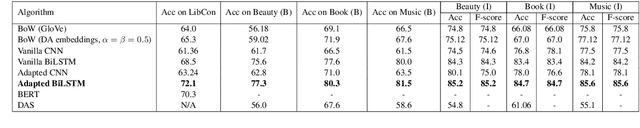
This paper proposes a way to improve the performance of existing algorithms for text classification in domains with strong language semantics. We propose a domain adaptation layer learns weights to combine a generic and a domain specific (DS) word embedding into a domain adapted (DA) embedding. The DA word embeddings are then used as inputs to a generic encoder + classifier framework to perform a downstream task such as classification. This adaptation layer is particularly suited to datasets that are modest in size, and which are, therefore, not ideal candidates for (re)training a deep neural network architecture. Results on binary and multi-class classification tasks using popular encoder architectures, including current state-of-the-art methods (with and without the shallow adaptation layer) show the effectiveness of the proposed approach.