 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Sentiment Analysis using Deep Canonical Correlation Analysis
Jul 15, 2019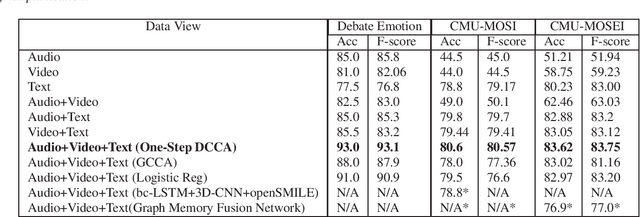
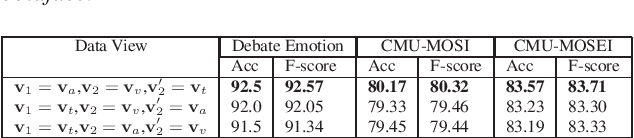
This paper learns multi-modal embeddings from text, audio, and video views/modes of data in order to improve upon down-stream sentiment classification. The experimental framework also allows investigation of the relative contributions of the individual views in the final multi-modal embedding. Individual features derived from the three views are combined into a multi-modal embedding using Deep Canonical Correlation Analysis (DCCA) in two ways i) One-Step DCCA and ii) Two-Step DCCA. This paper learns text embeddings using BERT, the current state-of-the-art in text encoders. We posit that this highly optimized algorithm dominates over the contribution of other views, though each view does contribute to the final result. Classification tasks are carried out on two benchmark datasets and on a new Debate Emotion data set, and together these demonstrate that the one-Step DCCA outperforms the current state-of-the-art in learning multi-modal embeddings.