 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Transcription of Drum Strokes in Carnatic Music
Nov 28, 2022The mridangam is a double-headed percussion instrument that plays a key role in Carnatic music concerts. This paper presents a novel automatic transcription algorithm to classify the strokes played on the mridangam. Onset detection is first performed to segment the audio signal into individual strokes, and feature vectors consisting of the DFT magnitude spectrum of the segmented signal are generated. A multi-layer feedforward neural network is trained using the feature vectors as inputs and the manual transcriptions as targets. Since the mridangam is a tonal instrument tuned to a given tonic, tonic invariance is an important feature of the classifier. Tonic invariance is achieved by augmenting the dataset with pitch-shifted copies of the audio. This algorithm consistently yields over 83% accuracy on a held-out test dataset.
Learning Relationships between Text, Audio, and Video via Deep Canonical Correlation for Multimodal Language Analysis
Nov 30, 2019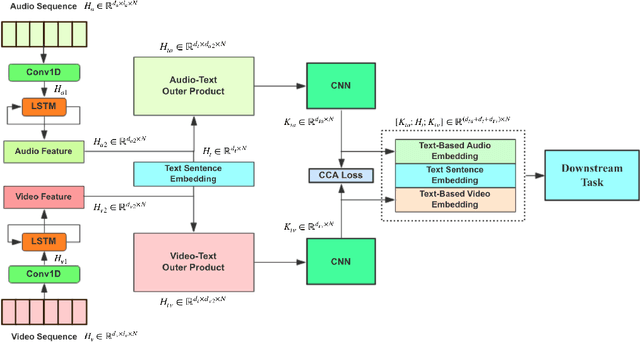
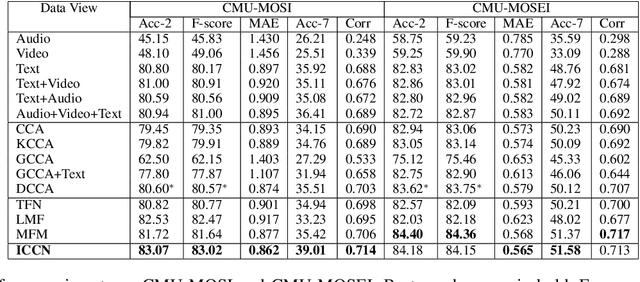
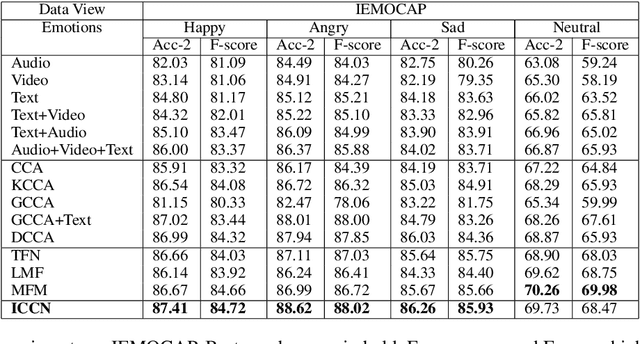
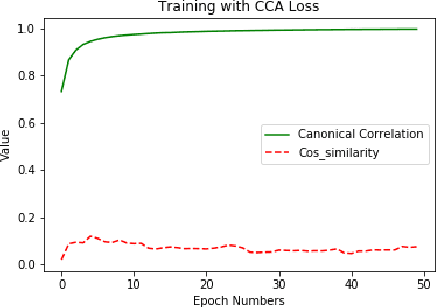
Multimodal language analysis often considers relationships between features based on text and those based on acoustical and visual properties. Text features typically outperform non-text features in sentiment analysis or emotion recognition tasks in part because the text features are derived from advanced language models or word embeddings trained on massive data sources while audio and video features are human-engineered and comparatively underdeveloped. Given that the text, audio, and video are describing the same utterance in different ways, we hypothesize that the multimodal sentiment analysis and emotion recognition can be improved by learning (hidden) correlations between features extracted from the outer product of text and audio (we call this text-based audio) and analogous text-based video. This paper proposes a novel model, the Interaction Canonical Correlation Network (ICCN), to learn such multimodal embeddings. ICCN learns correlations between all three modes via deep canonical correlation analysis (DCCA) and the proposed embeddings are then tested on several benchmark datasets and against other state-of-the-art multimodal embedding algorithms. Empirical results and ablation studies confirm the effectiveness of ICCN in capturing useful information from all three views.
Multi-modal Sentiment Analysis using Deep Canonical Correlation Analysis
Jul 15, 2019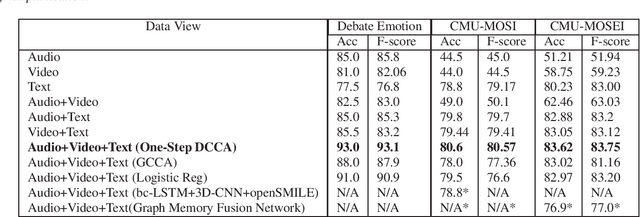
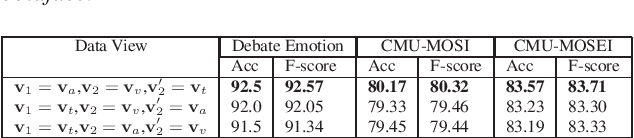
This paper learns multi-modal embeddings from text, audio, and video views/modes of data in order to improve upon down-stream sentiment classification. The experimental framework also allows investigation of the relative contributions of the individual views in the final multi-modal embedding. Individual features derived from the three views are combined into a multi-modal embedding using Deep Canonical Correlation Analysis (DCCA) in two ways i) One-Step DCCA and ii) Two-Step DCCA. This paper learns text embeddings using BERT, the current state-of-the-art in text encoders. We posit that this highly optimized algorithm dominates over the contribution of other views, though each view does contribute to the final result. Classification tasks are carried out on two benchmark datasets and on a new Debate Emotion data set, and together these demonstrate that the one-Step DCCA outperforms the current state-of-the-art in learning multi-modal embeddings.
Target Image Video Search Based on Local Features
Aug 11, 2018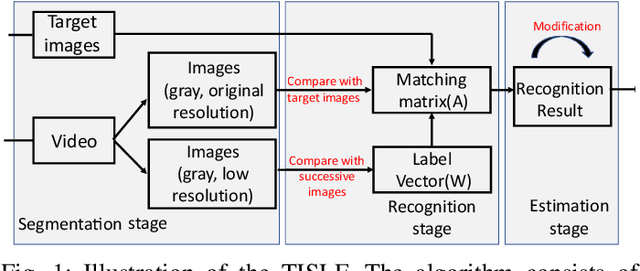

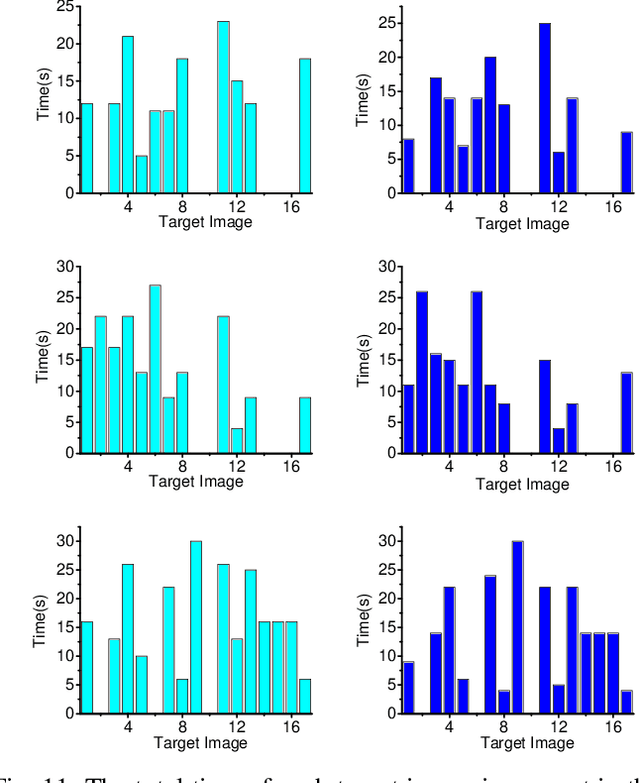
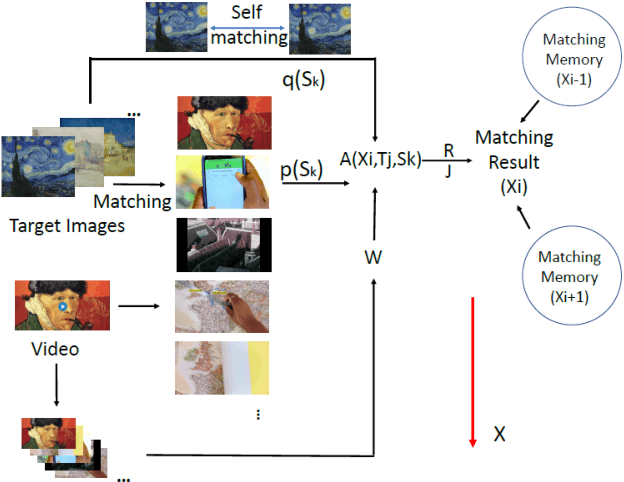
This paper presents a new search algorithm called Target Image Search based on Local Features (TISLF) which compares target images and video source images using local features. TISLF can be used to locate frames where target images occur in a video, and by computing and comparing the matching probability matrix, estimates the time of appearance, the duration, and the time of disappearance of the target image from the video stream. The algorithm is applicable to a variety of applications such as tracking the appearance and duration of advertisements in the broadcast of a sports event, searching and labelling painting in documentaries, and searching landmarks of different cities in videos. The algorithm is compared to a deep learning method and shows competitive performance in experiments.