 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Parallel Sequence Models to Foundation-Scale Vision Encoders
May 30, 2026Vision foundation models are bottlenecked by the quadratic cost of self-attention, which limits usable resolution and increases the cost of large-scale pretraining. Subquadratic alternatives such as linear attention and state-space models reduce this cost, but often serialize images into 1D token streams and weaken the 2D spatial structure important for vision. Generalized Spatial Propagation Networks (GSPN) instead propagate context directly on the 2D grid through line-scan recurrences, achieving near-linear complexity without positional embeddings, but have seen little use as foundation-scale encoders. We present C-GSPN, a foundation-scale vision encoder based on 2D spatial propagation. C-GSPN makes the operator practical through three improvements: (1) a fast GSPN CUDA kernel that fuses per-step launches into a single warp-specialized implementation with shared-memory tiling, coalesced access, and a compact multi-channel propagation, reaching over 90% of peak memory bandwidth and running up to 40--52x faster than the original GSPN implementation; (2) a compressed latent-space propagation block with fused normalization, which turns kernel-level speed into block- and model-level efficiency; and (3) a two-stage cross-operator distillation recipe that trains the new architecture from an attention teacher without the cost of from-scratch foundation-scale training. Distilled with 600M image-text pairs, C-GSPN matches an isomorphic ViT baseline with 15% fewer parameters, improves ADE20K segmentation by +2.1%, transfers to high resolution with a fraction of the data needed from scratch, and delivers a 4x end-to-end block speedup at 2K with single-pass, tiling-free inference.
JetViT: Efficient High-Resolution Vision Transformer with Post-Training Attention Search
May 26, 2026We introduce JetViT, a novel family of hybrid-architecture Vision Transformer (ViT) models that match the accuracy of state-of-the-art full-attention vision foundation models while achieving substantially higher inference efficiency on high-resolution images. At the core of our approach is Post-Training Attention Search, a post-training acceleration framework that converts pre-trained full-attention ViTs into efficient hybrid-attention variants by identifying and replacing redundant full-attention blocks with linear or window-attention blocks. By inheriting the MLP and attention weights from the base model, Post-Training Attention Search efficiently explores the architectural design space through three key steps: (1) optimizing the linear-attention block design; (2) finding the best combination of linear-attention and window-attention blocks; and (3) identifying and preserving critical full-attention blocks. We evaluate JetViT on two representative high-resolution vision foundation models, DINOv3 and DepthAnythingV2. On the NVIDIA H100 GPU, JetViT achieves up to 1.79x higher throughput and up to 44.81% lower latency without sacrificing accuracy. We will release our code and accelerated ViT models soon.
Nemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence
Apr 27, 2026We introduce Nemotron 3 Nano Omni, the latest model in the Nemotron multimodal series and the first to natively support audio inputs alongside text, images, and video. Nemotron 3 Nano Omni delivers consistent accuracy improvements over its predecessor, Nemotron Nano V2 VL, across all modalities, enabled by advances in architecture, training data and recipes. In particular, Nemotron 3 delivers leading results in real-world document understanding, long audio-video comprehension, and agentic computer use. Built on the highly efficient Nemotron 3 Nano 30B-A3B backbone, Nemotron 3 Nano Omni further incorporates innovative multimodal token-reduction techniques to deliver substantially lower inference latency and higher throughput than other models of similar size. We are releasing model checkpoints in BF16, FP8, and FP4 formats, along with portions of the training data and codebase to facilitate further research and development.
Attend Before Attention: Efficient and Scalable Video Understanding via Autoregressive Gazing
Mar 12, 2026Multi-modal large language models (MLLMs) have advanced general-purpose video understanding but struggle with long, high-resolution videos -- they process every pixel equally in their vision transformers (ViTs) or LLMs despite significant spatiotemporal redundancy. We introduce AutoGaze, a lightweight module that removes redundant patches before processed by a ViT or an MLLM. Trained with next-token prediction and reinforcement learning, AutoGaze autoregressively selects a minimal set of multi-scale patches that can reconstruct the video within a user-specified error threshold, eliminating redundancy while preserving information. Empirically, AutoGaze reduces visual tokens by 4x-100x and accelerates ViTs and MLLMs by up to 19x, enabling scaling MLLMs to 1K-frame 4K-resolution videos and achieving superior results on video benchmarks (e.g., 67.0% on VideoMME). Furthermore, we introduce HLVid: the first high-resolution, long-form video QA benchmark with 5-minute 4K-resolution videos, where an MLLM scaled with AutoGaze improves over the baseline by 10.1% and outperforms the previous best MLLM by 4.5%. Project page: https://autogaze.github.io/.
Speech-Hands: A Self-Reflection Voice Agentic Approach to Speech Recognition and Audio Reasoning with Omni Perception
Jan 14, 2026We introduce a voice-agentic framework that learns one critical omni-understanding skill: knowing when to trust itself versus when to consult external audio perception. Our work is motivated by a crucial yet counterintuitive finding: naively fine-tuning an omni-model on both speech recognition and external sound understanding tasks often degrades performance, as the model can be easily misled by noisy hypotheses. To address this, our framework, Speech-Hands, recasts the problem as an explicit self-reflection decision. This learnable reflection primitive proves effective in preventing the model from being derailed by flawed external candidates. We show that this agentic action mechanism generalizes naturally from speech recognition to complex, multiple-choice audio reasoning. Across the OpenASR leaderboard, Speech-Hands consistently outperforms strong baselines by 12.1% WER on seven benchmarks. The model also achieves 77.37% accuracy and high F1 on audio QA decisions, showing robust generalization and reliability across diverse audio question answering datasets. By unifying perception and decision-making, our work offers a practical path toward more reliable and resilient audio intelligence.
Test-Time Scaling Strategies for Generative Retrieval in Multimodal Conversational Recommendations
Aug 25, 2025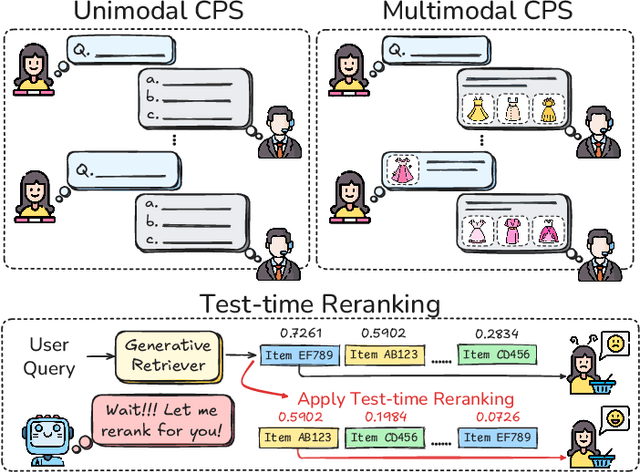
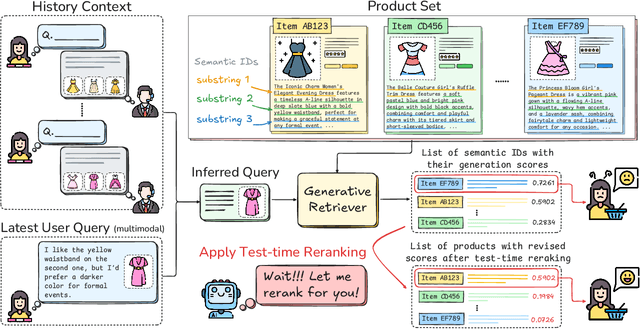
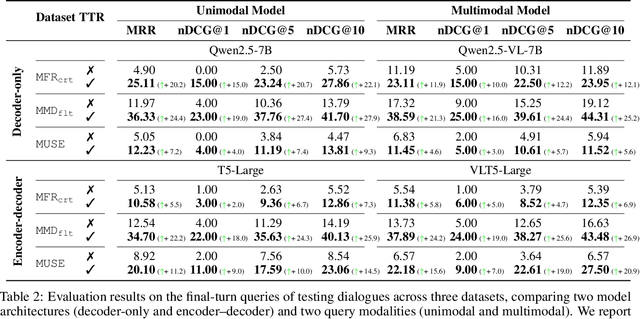
The rapid evolution of e-commerce has exposed the limitations of traditional product retrieval systems in managing complex, multi-turn user interactions. Recent advances in multimodal generative retrieval -- particularly those leveraging multimodal large language models (MLLMs) as retrievers -- have shown promise. However, most existing methods are tailored to single-turn scenarios and struggle to model the evolving intent and iterative nature of multi-turn dialogues when applied naively. Concurrently, test-time scaling has emerged as a powerful paradigm for improving large language model (LLM) performance through iterative inference-time refinement. Yet, its effectiveness typically relies on two conditions: (1) a well-defined problem space (e.g., mathematical reasoning), and (2) the model's ability to self-correct -- conditions that are rarely met in conversational product search. In this setting, user queries are often ambiguous and evolving, and MLLMs alone have difficulty grounding responses in a fixed product corpus. Motivated by these challenges, we propose a novel framework that introduces test-time scaling into conversational multimodal product retrieval. Our approach builds on a generative retriever, further augmented with a test-time reranking (TTR) mechanism that improves retrieval accuracy and better aligns results with evolving user intent throughout the dialogue. Experiments across multiple benchmarks show consistent improvements, with average gains of 14.5 points in MRR and 10.6 points in nDCG@1.
Scaling RL to Long Videos
Jul 10, 2025We introduce a full-stack framework that scales up reasoning in vision-language models (VLMs) to long videos, leveraging reinforcement learning. We address the unique challenges of long video reasoning by integrating three critical components: (1) a large-scale dataset, LongVideo-Reason, comprising 52K long video QA pairs with high-quality reasoning annotations across diverse domains such as sports, games, and vlogs; (2) a two-stage training pipeline that extends VLMs with chain-of-thought supervised fine-tuning (CoT-SFT) and reinforcement learning (RL); and (3) a training infrastructure for long video RL, named Multi-modal Reinforcement Sequence Parallelism (MR-SP), which incorporates sequence parallelism and a vLLM-based engine tailored for long video, using cached video embeddings for efficient rollout and prefilling. In experiments, LongVILA-R1-7B achieves strong performance on long video QA benchmarks such as VideoMME. It also outperforms Video-R1-7B and even matches Gemini-1.5-Pro across temporal reasoning, goal and purpose reasoning, spatial reasoning, and plot reasoning on our LongVideo-Reason-eval benchmark. Notably, our MR-SP system achieves up to 2.1x speedup on long video RL training. LongVILA-R1 demonstrates consistent performance gains as the number of input video frames scales. LongVILA-R1 marks a firm step towards long video reasoning in VLMs. In addition, we release our training system for public availability that supports RL training on various modalities (video, text, and audio), various models (VILA and Qwen series), and even image and video generation models. On a single A100 node (8 GPUs), it supports RL training on hour-long videos (e.g., 3,600 frames / around 256k tokens).
Multi-Task Label Discovery via Hierarchical Task Tokens for Partially Annotated Dense Predictions
Nov 27, 2024In recent years, simultaneous learning of multiple dense prediction tasks with partially annotated label data has emerged as an important research area. Previous works primarily focus on constructing cross-task consistency or conducting adversarial training to regularize cross-task predictions, which achieve promising performance improvements, while still suffering from the lack of direct pixel-wise supervision for multi-task dense predictions. To tackle this challenge, we propose a novel approach to optimize a set of learnable hierarchical task tokens, including global and fine-grained ones, to discover consistent pixel-wise supervision signals in both feature and prediction levels. Specifically, the global task tokens are designed for effective cross-task feature interactions in a global context. Then, a group of fine-grained task-specific spatial tokens for each task is learned from the corresponding global task tokens. It is embedded to have dense interactions with each task-specific feature map. The learned global and local fine-grained task tokens are further used to discover pseudo task-specific dense labels at different levels of granularity, and they can be utilized to directly supervise the learning of the multi-task dense prediction framework. Extensive experimental results on challenging NYUD-v2, Cityscapes, and PASCAL Context datasets demonstrate significant improvements over existing state-of-the-art methods for partially annotated multi-task dense prediction.
MM-Ego: Towards Building Egocentric Multimodal LLMs
Oct 09, 2024



This research aims to comprehensively explore building a multimodal foundation model for egocentric video understanding. To achieve this goal, we work on three fronts. First, as there is a lack of QA data for egocentric video understanding, we develop a data engine that efficiently generates 7M high-quality QA samples for egocentric videos ranging from 30 seconds to one hour long, based on human-annotated data. This is currently the largest egocentric QA dataset. Second, we contribute a challenging egocentric QA benchmark with 629 videos and 7,026 questions to evaluate the models' ability in recognizing and memorizing visual details across videos of varying lengths. We introduce a new de-biasing evaluation method to help mitigate the unavoidable language bias present in the models being evaluated. Third, we propose a specialized multimodal architecture featuring a novel "Memory Pointer Prompting" mechanism. This design includes a global glimpse step to gain an overarching understanding of the entire video and identify key visual information, followed by a fallback step that utilizes the key visual information to generate responses. This enables the model to more effectively comprehend extended video content. With the data, benchmark, and model, we successfully build MM-Ego, an egocentric multimodal LLM that shows powerful performance on egocentric video understanding.
MIA-Bench: Towards Better Instruction Following Evaluation of Multimodal LLMs
Jul 01, 2024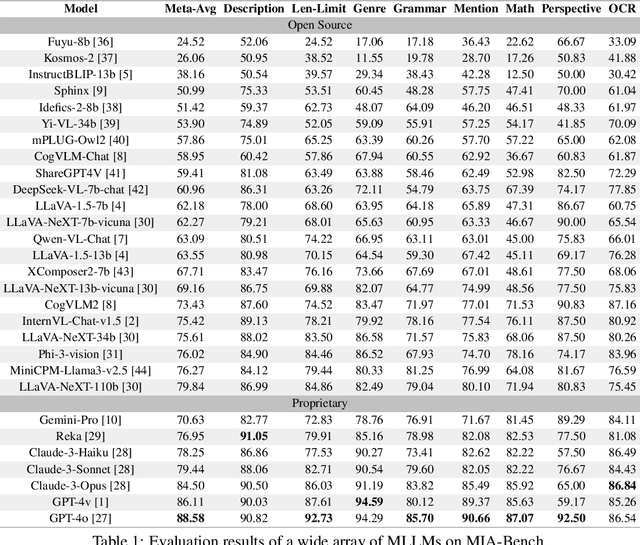
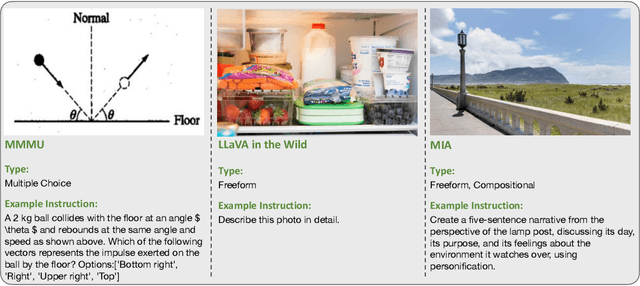
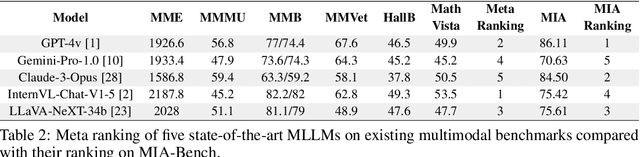
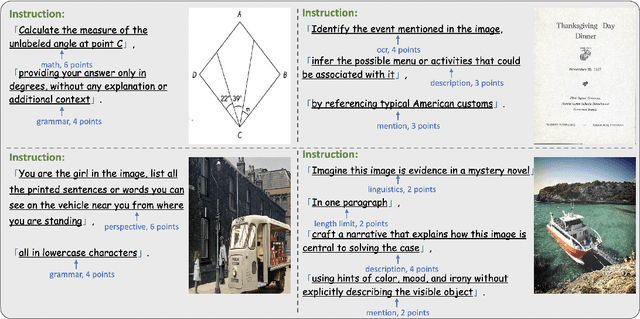
We introduce MIA-Bench, a new benchmark designed to evaluate multimodal large language models (MLLMs) on their ability to strictly adhere to complex instructions. Our benchmark comprises a diverse set of 400 image-prompt pairs, each crafted to challenge the models' compliance with layered instructions in generating accurate responses that satisfy specific requested patterns. Evaluation results from a wide array of state-of-the-art MLLMs reveal significant variations in performance, highlighting areas for improvement in instruction fidelity. Additionally, we create extra training data and explore supervised fine-tuning to enhance the models' ability to strictly follow instructions without compromising performance on other tasks. We hope this benchmark not only serves as a tool for measuring MLLM adherence to instructions, but also guides future developments in MLLM training methods.