 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePico-Banana-400K: A Large-Scale Dataset for Text-Guided Image Editing
Oct 22, 2025Recent advances in multimodal models have demonstrated remarkable text-guided image editing capabilities, with systems like GPT-4o and Nano-Banana setting new benchmarks. However, the research community's progress remains constrained by the absence of large-scale, high-quality, and openly accessible datasets built from real images. We introduce Pico-Banana-400K, a comprehensive 400K-image dataset for instruction-based image editing. Our dataset is constructed by leveraging Nano-Banana to generate diverse edit pairs from real photographs in the OpenImages collection. What distinguishes Pico-Banana-400K from previous synthetic datasets is our systematic approach to quality and diversity. We employ a fine-grained image editing taxonomy to ensure comprehensive coverage of edit types while maintaining precise content preservation and instruction faithfulness through MLLM-based quality scoring and careful curation. Beyond single turn editing, Pico-Banana-400K enables research into complex editing scenarios. The dataset includes three specialized subsets: (1) a 72K-example multi-turn collection for studying sequential editing, reasoning, and planning across consecutive modifications; (2) a 56K-example preference subset for alignment research and reward model training; and (3) paired long-short editing instructions for developing instruction rewriting and summarization capabilities. By providing this large-scale, high-quality, and task-rich resource, Pico-Banana-400K establishes a robust foundation for training and benchmarking the next generation of text-guided image editing models.
GIE-Bench: Towards Grounded Evaluation for Text-Guided Image Editing
May 16, 2025



Editing images using natural language instructions has become a natural and expressive way to modify visual content; yet, evaluating the performance of such models remains challenging. Existing evaluation approaches often rely on image-text similarity metrics like CLIP, which lack precision. In this work, we introduce a new benchmark designed to evaluate text-guided image editing models in a more grounded manner, along two critical dimensions: (i) functional correctness, assessed via automatically generated multiple-choice questions that verify whether the intended change was successfully applied; and (ii) image content preservation, which ensures that non-targeted regions of the image remain visually consistent using an object-aware masking technique and preservation scoring. The benchmark includes over 1000 high-quality editing examples across 20 diverse content categories, each annotated with detailed editing instructions, evaluation questions, and spatial object masks. We conduct a large-scale study comparing GPT-Image-1, the latest flagship in the text-guided image editing space, against several state-of-the-art editing models, and validate our automatic metrics against human ratings. Results show that GPT-Image-1 leads in instruction-following accuracy, but often over-modifies irrelevant image regions, highlighting a key trade-off in the current model behavior. GIE-Bench provides a scalable, reproducible framework for advancing more accurate evaluation of text-guided image editing.
UniVG: A Generalist Diffusion Model for Unified Image Generation and Editing
Mar 16, 2025Text-to-Image (T2I) diffusion models have shown impressive results in generating visually compelling images following user prompts. Building on this, various methods further fine-tune the pre-trained T2I model for specific tasks. However, this requires separate model architectures, training designs, and multiple parameter sets to handle different tasks. In this paper, we introduce UniVG, a generalist diffusion model capable of supporting a diverse range of image generation tasks with a single set of weights. UniVG treats multi-modal inputs as unified conditions to enable various downstream applications, ranging from T2I generation, inpainting, instruction-based editing, identity-preserving generation, and layout-guided generation, to depth estimation and referring segmentation. Through comprehensive empirical studies on data mixing and multi-task training, we provide detailed insights into the training processes and decisions that inform our final designs. For example, we show that T2I generation and other tasks, such as instruction-based editing, can coexist without performance trade-offs, while auxiliary tasks like depth estimation and referring segmentation enhance image editing. Notably, our model can even outperform some task-specific models on their respective benchmarks, marking a significant step towards a unified image generation model.
Understanding Alignment in Multimodal LLMs: A Comprehensive Study
Jul 02, 2024



Preference alignment has become a crucial component in enhancing the performance of Large Language Models (LLMs), yet its impact in Multimodal Large Language Models (MLLMs) remains comparatively underexplored. Similar to language models, MLLMs for image understanding tasks encounter challenges like hallucination. In MLLMs, hallucination can occur not only by stating incorrect facts but also by producing responses that are inconsistent with the image content. A primary objective of alignment for MLLMs is to encourage these models to align responses more closely with image information. Recently, multiple works have introduced preference datasets for MLLMs and examined different alignment methods, including Direct Preference Optimization (DPO) and Proximal Policy Optimization (PPO). However, due to variations in datasets, base model types, and alignment methods, it remains unclear which specific elements contribute most significantly to the reported improvements in these works. In this paper, we independently analyze each aspect of preference alignment in MLLMs. We start by categorizing the alignment algorithms into two groups, offline (such as DPO), and online (such as online-DPO), and show that combining offline and online methods can improve the performance of the model in certain scenarios. We review a variety of published multimodal preference datasets and discuss how the details of their construction impact model performance. Based on these insights, we introduce a novel way of creating multimodal preference data called Bias-Driven Hallucination Sampling (BDHS) that needs neither additional annotation nor external models, and show that it can achieve competitive performance to previously published alignment work for multimodal models across a range of benchmarks.
MIA-Bench: Towards Better Instruction Following Evaluation of Multimodal LLMs
Jul 01, 2024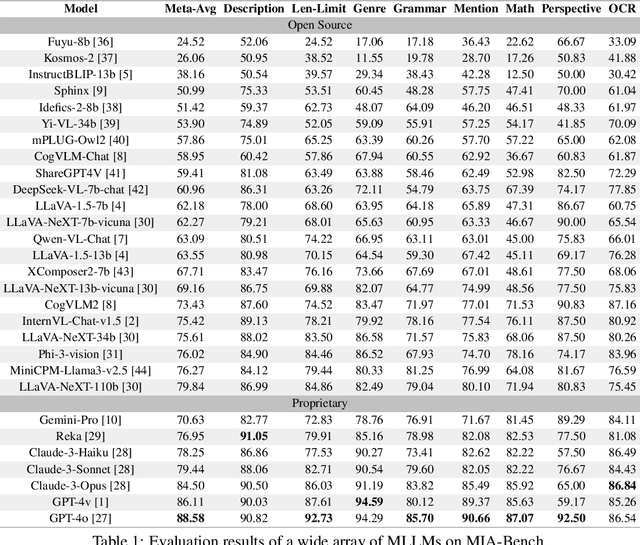
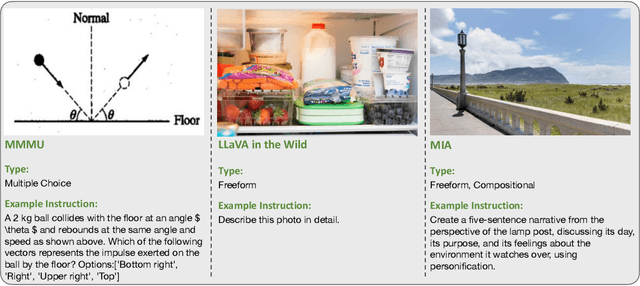
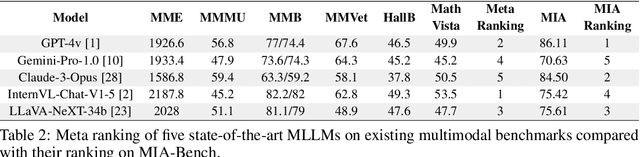
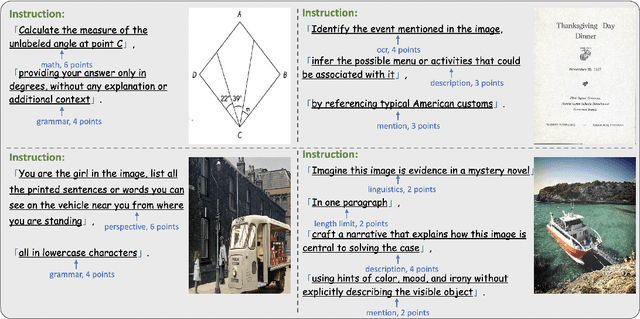
We introduce MIA-Bench, a new benchmark designed to evaluate multimodal large language models (MLLMs) on their ability to strictly adhere to complex instructions. Our benchmark comprises a diverse set of 400 image-prompt pairs, each crafted to challenge the models' compliance with layered instructions in generating accurate responses that satisfy specific requested patterns. Evaluation results from a wide array of state-of-the-art MLLMs reveal significant variations in performance, highlighting areas for improvement in instruction fidelity. Additionally, we create extra training data and explore supervised fine-tuning to enhance the models' ability to strictly follow instructions without compromising performance on other tasks. We hope this benchmark not only serves as a tool for measuring MLLM adherence to instructions, but also guides future developments in MLLM training methods.
How Easy is It to Fool Your Multimodal LLMs? An Empirical Analysis on Deceptive Prompts
Feb 20, 2024



The remarkable advancements in Multimodal Large Language Models (MLLMs) have not rendered them immune to challenges, particularly in the context of handling deceptive information in prompts, thus producing hallucinated responses under such conditions. To quantitatively assess this vulnerability, we present MAD-Bench, a carefully curated benchmark that contains 850 test samples divided into 6 categories, such as non-existent objects, count of objects, spatial relationship, and visual confusion. We provide a comprehensive analysis of popular MLLMs, ranging from GPT-4V, Gemini-Pro, to open-sourced models, such as LLaVA-1.5 and CogVLM. Empirically, we observe significant performance gaps between GPT-4V and other models; and previous robust instruction-tuned models, such as LRV-Instruction and LLaVA-RLHF, are not effective on this new benchmark. While GPT-4V achieves 75.02% accuracy on MAD-Bench, the accuracy of any other model in our experiments ranges from 5% to 35%. We further propose a remedy that adds an additional paragraph to the deceptive prompts to encourage models to think twice before answering the question. Surprisingly, this simple method can even double the accuracy; however, the absolute numbers are still too low to be satisfactory. We hope MAD-Bench can serve as a valuable benchmark to stimulate further research to enhance models' resilience against deceptive prompts.
Reducing Gender Bias in Word-Level Language Models with a Gender-Equalizing Loss Function
Jun 03, 2019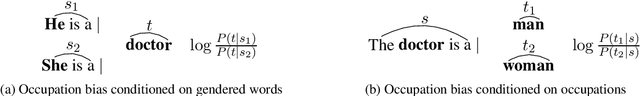
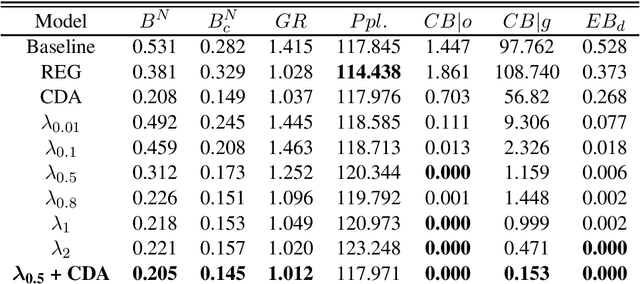
Gender bias exists in natural language datasets which neural language models tend to learn, resulting in biased text generation. In this research, we propose a debiasing approach based on the loss function modification. We introduce a new term to the loss function which attempts to equalize the probabilities of male and female words in the output. Using an array of bias evaluation metrics, we provide empirical evidence that our approach successfully mitigates gender bias in language models without increasing perplexity. In comparison to existing debiasing strategies, data augmentation, and word embedding debiasing, our method performs better in several aspects, especially in reducing gender bias in occupation words. Finally, we introduce a combination of data augmentation and our approach, and show that it outperforms existing strategies in all bias evaluation metrics.