 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilled One-Shot Federated Learning
Paper and Code
Sep 17, 2020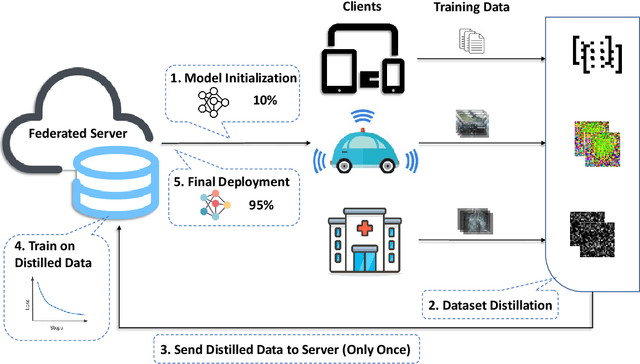
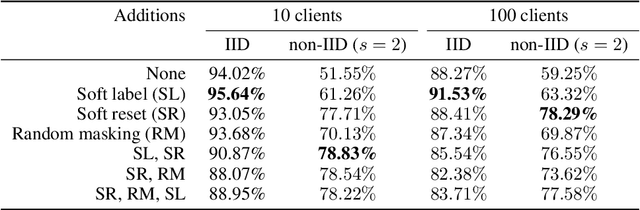
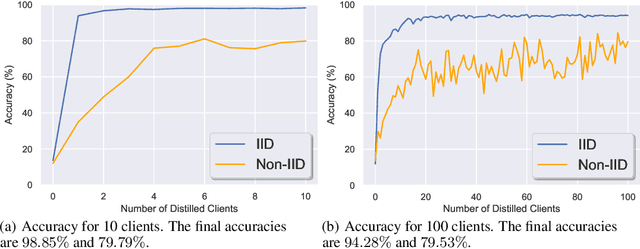
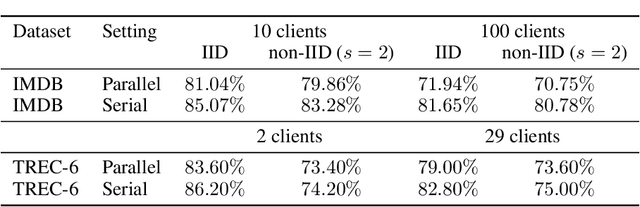
Current federated learning algorithms take tens of communication rounds transmitting unwieldy model weights under ideal circumstances and hundreds when data is poorly distributed. Inspired by recent work on dataset distillation and distributed one-shot learning, we propose Distilled One-Shot Federated Learning, which reduces the number of communication rounds required to train a performant model to only one. Each client distills their private dataset and sends the synthetic data (e.g. images or sentences) to the server. The distilled data look like noise and become useless after model fitting. We empirically show that, in only one round of communication, our method can achieve 96% test accuracy on federated MNIST with LeNet (centralized 99%), 81% on federated IMDB with a customized CNN (centralized 86%), and 84% on federated TREC-6 with a Bi-LSTM (centralized 89%). Using only a few rounds, DOSFL can match the centralized baseline on all three tasks. By evading the need for model-wise updates (i.e., weights, gradients, loss, etc.), the total communication cost of DOSFL is reduced by over an order of magnitude. We believe that DOSFL represents a new direction orthogonal to previous work, towards weight-less and gradient-less federated learning.