 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-BrowseComp: A Web Browsing Agent Benchmark Grounded in Korean Contexts
Jun 01, 2026Frontier model evaluations are shifting from foundational capabilities (e.g., instruction following and reasoning) toward compositional, agentic ones, but Korean agentic benchmarks remain scarce. We introduce K-BrowseComp, a web-browsing agent benchmark grounded in Korean contexts, consisting of 400 problems. The 300-problem K-BrowseComp-Verified subset is manually constructed and validated by native Korean speakers. On this subset, frontier LLMs, including GPT-5.5, DeepSeek-V4-Pro, and GLM-5.1, reach only 30.00--45.67\%, a substantial drop from BrowseComp, while Korean LLMs released through Korea's Proprietary AI Foundation Model program obtain only 0.00--10.33\%. We further construct a 100-problem synthetic split using hard few-shot exemplars and failure-mode-targeted generation to exploit the asymmetry between solving and creating web browsing problems. On the adversarially filtered synthetic diagnostic split, the strongest model reaches only 26.00\%, and we report this split separately as a targeted stress test. We publicly release our data and code.
Verus-SpecGym: An Agentic Environment for Evaluating Specification Autoformalization
May 26, 2026AI coding agents are increasingly used to write real-world software, but ensuring that their outputs are correct remains a fundamental challenge. Formal verification offers a promising path: an agent generates code together with a machine-checked proof, guaranteeing that the code satisfies a formal specification. However, there is no guarantee that the formal spec itself matches the user's intent. In this work, we study specification autoformalization: whether LLM agents can translate informal programming problems into faithful formal specifications. We introduce Verus-SpecBench, a benchmark of 581 spec-writing tasks derived from Codeforces problems targeting Verus, a verifier for Rust, and Verus-SpecGym, an agentic environment in which models interact with Verus, bash, & the filesystem to develop these specs. The central challenge is evaluation: expert-written reference specs are expensive to write, & LLM judges can miss subtle mistakes. We address this by (a) extending Verus's exec_spec mechanism so that generated specs can be executed as Rust code, & (b) testing them against official Codeforces tests & adversarial cases extracted from Codeforces "hacks", which are edge cases written by competitors to break incorrect solutions. On Verus-SpecBench, the strongest model, Gemini 3.1 Pro, solves 77.8% of tasks, other frontier models solve 51.1--57.8% & OSS models reach only 21.5--25.5%. Our analysis of failure modes shows that model-generated specs can omit important input assumptions, accept incorrect outputs, & reject valid ones. We also find that LLM-as-a-judge evaluation misses 26% of the failures our evaluator catches. Overall, our results suggest that spec autoformalization is within reach for frontier agents but remains brittle even on problems where they can already generate correct code. The code, data, & logs can be found at https://github.com/formal-verif-is-cool/verus-spec-gym
On the limits and opportunities of AI reviewers: Reviewing the reviews of Nature-family papers with 45 expert scientists
May 20, 2026With the advancement of AI capabilities, AI reviewers are beginning to be deployed in scientific peer review, yet their capability and credibility remain in question: many scientists simply view them as probabilistic systems without the expertise to evaluate research, while other researchers are more optimistic about their readiness without concrete evidence. Understanding what AI reviewers do well, where they fall short, and what challenges remain is essential. However, existing evaluations of AI reviewers have focused on whether their verdicts match human verdicts (e.g., score alignment, acceptance prediction), which is insufficient to characterize their capabilities and limits. In this paper, we close this gap through a large-scale expert annotation study, in which 45 domain scientists in Physical, Biological, and Health Sciences spent 469 hours rating 2,960 individual criticisms (each targeting one specific aspect of a paper) from human-written and AI-generated reviews of 82 Nature-family papers on correctness, significance, and sufficiency of evidence. On a composite of all three dimensions, a reviewing agent powered by GPT-5.2 scores above each paper's top-rated human reviewer (60.0% vs. 48.2%, p = 0.009), while all three AI reviewers (including Gemini 3.0 Pro and Claude Opus 4.5) exceed the lowest-rated human across every dimension. AI reviewers' accurate criticisms are also more often rated significant and well-evidenced, and surface a distinct 26% of issues no human raises. However, AI reviewers overlap far more than humans do (21% vs. 3% for cross-reviewer pairs), and exhibit 16 recurring weaknesses humans do not share, such as limited subfield knowledge, lack of long context management over multiple files, and overly critical stance on minor issues. Overall, our results position current AI reviewers as complements to, not substitutes for, human reviewers.
Reasoning over mathematical objects: on-policy reward modeling and test time aggregation
Mar 19, 2026The ability to precisely derive mathematical objects is a core requirement for downstream STEM applications, including mathematics, physics, and chemistry, where reasoning must culminate in formally structured expressions. Yet, current LM evaluations of mathematical and scientific reasoning rely heavily on simplified answer formats such as numerical values or multiple choice options due to the convenience of automated assessment. In this paper we provide three contributions for improving reasoning over mathematical objects: (i) we build and release training data and benchmarks for deriving mathematical objects, the Principia suite; (ii) we provide training recipes with strong LLM-judges and verifiers, where we show that on-policy judge training boosts performance; (iii) we show how on-policy training can also be used to scale test-time compute via aggregation. We find that strong LMs such as Qwen3-235B and o3 struggle on Principia, while our training recipes can bring significant improvements over different LLM backbones, while simultaneously improving results on existing numerical and MCQA tasks, demonstrating cross-format generalization of reasoning abilities.
OptimalThinkingBench: Evaluating Over and Underthinking in LLMs
Aug 18, 2025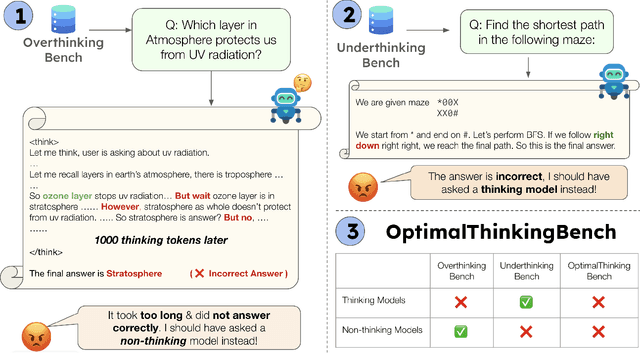
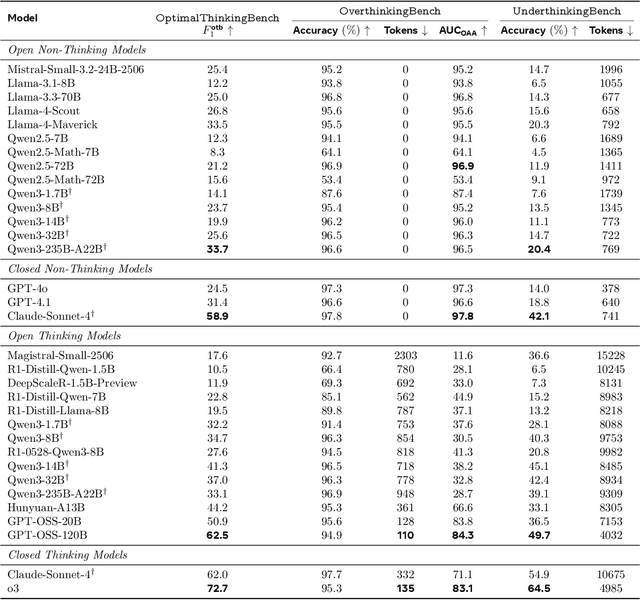

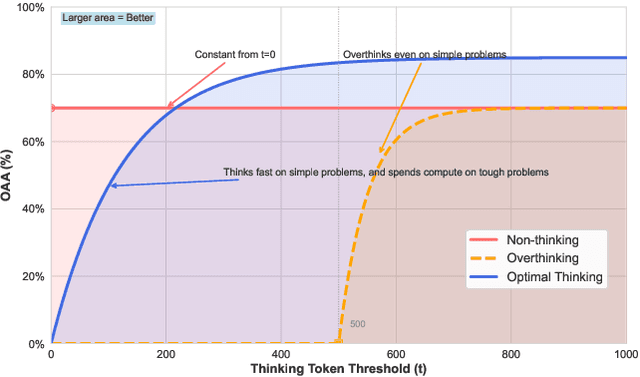
Thinking LLMs solve complex tasks at the expense of increased compute and overthinking on simpler problems, while non-thinking LLMs are faster and cheaper but underthink on harder reasoning problems. This has led to the development of separate thinking and non-thinking LLM variants, leaving the onus of selecting the optimal model for each query on the end user. In this work, we introduce OptimalThinkingBench, a unified benchmark that jointly evaluates overthinking and underthinking in LLMs and also encourages the development of optimally-thinking models that balance performance and efficiency. Our benchmark comprises two sub-benchmarks: OverthinkingBench, featuring simple queries in 72 domains, and UnderthinkingBench, containing 11 challenging reasoning tasks. Using novel thinking-adjusted accuracy metrics, we perform extensive evaluation of 33 different thinking and non-thinking models and show that no model is able to optimally think on our benchmark. Thinking models often overthink for hundreds of tokens on the simplest user queries without improving performance. In contrast, large non-thinking models underthink, often falling short of much smaller thinking models. We further explore several methods to encourage optimal thinking, but find that these approaches often improve on one sub-benchmark at the expense of the other, highlighting the need for better unified and optimal models in the future.
Let's Predict Sentence by Sentence
May 28, 2025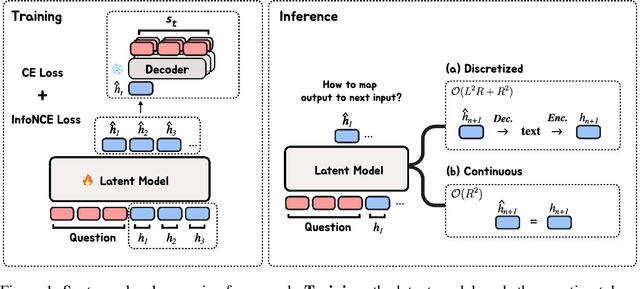
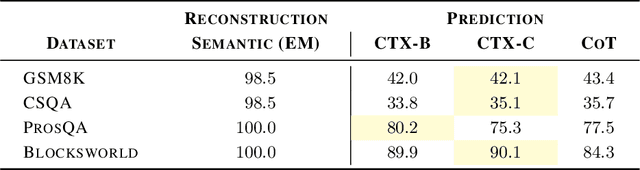
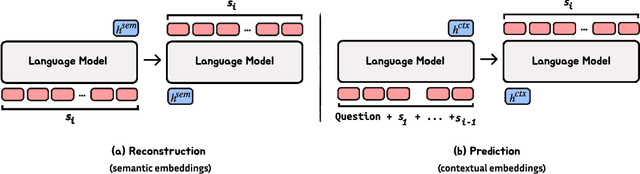
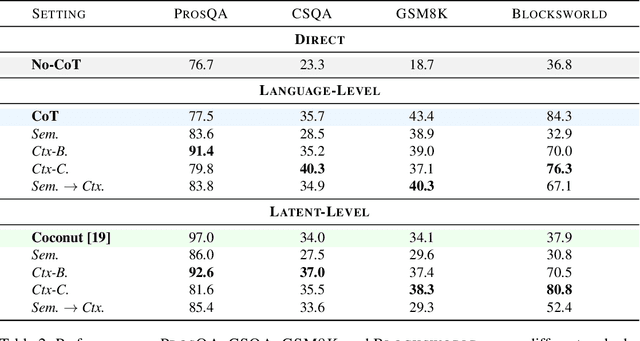
Autoregressive language models (LMs) generate one token at a time, yet human reasoning operates over higher-level abstractions - sentences, propositions, and concepts. This contrast raises a central question- Can LMs likewise learn to reason over structured semantic units rather than raw token sequences? In this work, we investigate whether pretrained LMs can be lifted into such abstract reasoning spaces by building on their learned representations. We present a framework that adapts a pretrained token-level LM to operate in sentence space by autoregressively predicting continuous embeddings of next sentences. We explore two embedding paradigms inspired by classical representation learning: 1) semantic embeddings, learned via autoencoding to preserve surface meaning; and 2) contextual embeddings, trained via next-sentence prediction to encode anticipatory structure. We evaluate both under two inference regimes: Discretized, which decodes each predicted embedding into text before re-encoding; and Continuous, which reasons entirely in embedding space for improved efficiency. Across four domains - mathematics, logic, commonsense, and planning - contextual embeddings under continuous inference show competitive performance with Chain-of-Thought (CoT) while reducing inference-time FLOPs on average by half. We also present early signs of scalability and modular adaptation. Finally, to visualize latent trajectories, we introduce SentenceLens, a diagnostic tool that decodes intermediate model states into interpretable sentences. Together, our results indicate that pretrained LMs can effectively transition to abstract, structured reasoning within latent embedding spaces.
Measuring Sycophancy of Language Models in Multi-turn Dialogues
May 28, 2025Large Language Models (LLMs) are expected to provide helpful and harmless responses, yet they often exhibit sycophancy--conforming to user beliefs regardless of factual accuracy or ethical soundness. Prior research on sycophancy has primarily focused on single-turn factual correctness, overlooking the dynamics of real-world interactions. In this work, we introduce SYCON Bench, a novel benchmark for evaluating sycophantic behavior in multi-turn, free-form conversational settings. Our benchmark measures how quickly a model conforms to the user (Turn of Flip) and how frequently it shifts its stance under sustained user pressure (Number of Flip). Applying SYCON Bench to 17 LLMs across three real-world scenarios, we find that sycophancy remains a prevalent failure mode. Our analysis shows that alignment tuning amplifies sycophantic behavior, whereas model scaling and reasoning optimization strengthen the model's ability to resist undesirable user views. Reasoning models generally outperform instruction-tuned models but often fail when they over-index on logical exposition instead of directly addressing the user's underlying beliefs. Finally, we evaluate four additional prompting strategies and demonstrate that adopting a third-person perspective reduces sycophancy by up to 63.8% in debate scenario. We release our code and data at https://github.com/JiseungHong/SYCON-Bench.
FREESON: Retriever-Free Retrieval-Augmented Reasoning via Corpus-Traversing MCTS
May 22, 2025Large Reasoning Models (LRMs) have demonstrated remarkable capabilities in multi-step reasoning and calling search engines at appropriate steps. However, existing retrieval-augmented reasoning approaches rely on separate retrieval models, limiting the LRM's role in retrieval to deciding when to retrieve and how to query. This separation not only increases hardware and operational costs but also leads to errors in the retrieval process due to the representation bottleneck, a phenomenon where the retriever's embedding space is not expressive enough to meet the generator's requirements. To address this, we shift our perspective from sequence-to-sequence matching to locating the answer-containing paths within the corpus, and propose a novel framework called FREESON (Retriever-FREE Retrieval-Augmented ReaSONing). This framework enables LRMs to retrieve relevant knowledge on their own by acting as both a generator and retriever. To achieve this, we introduce a variant of the MCTS algorithm specialized for the retrieval task, which we call CT-MCTS (Corpus-Traversing Monte Carlo Tree Search). In this algorithm, LRMs traverse through the corpus toward answer-containing regions. Our results on five open-domain QA benchmarks, including single-hop and multi-hop questions, show that FREESON achieves an average improvement of 14.4% in EM and F1 over four multi-step reasoning models with a separate retriever, and it also performs comparably to the strongest baseline, surpassing it by 3% on PopQA and 2WikiMultihopQA.
Web-Shepherd: Advancing PRMs for Reinforcing Web Agents
May 21, 2025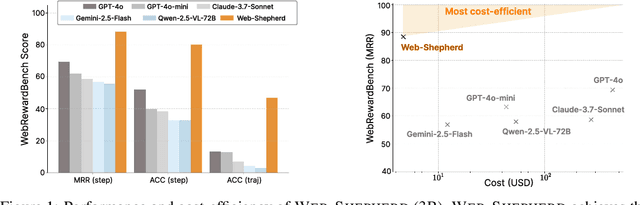


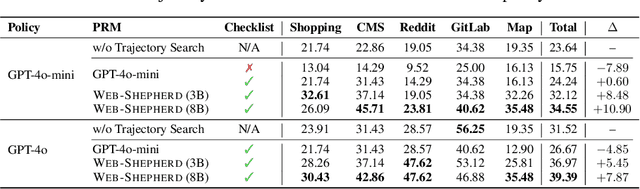
Web navigation is a unique domain that can automate many repetitive real-life tasks and is challenging as it requires long-horizon sequential decision making beyond typical multimodal large language model (MLLM) tasks. Yet, specialized reward models for web navigation that can be utilized during both training and test-time have been absent until now. Despite the importance of speed and cost-effectiveness, prior works have utilized MLLMs as reward models, which poses significant constraints for real-world deployment. To address this, in this work, we propose the first process reward model (PRM) called Web-Shepherd which could assess web navigation trajectories in a step-level. To achieve this, we first construct the WebPRM Collection, a large-scale dataset with 40K step-level preference pairs and annotated checklists spanning diverse domains and difficulty levels. Next, we also introduce the WebRewardBench, the first meta-evaluation benchmark for evaluating PRMs. In our experiments, we observe that our Web-Shepherd achieves about 30 points better accuracy compared to using GPT-4o on WebRewardBench. Furthermore, when testing on WebArena-lite by using GPT-4o-mini as the policy and Web-Shepherd as the verifier, we achieve 10.9 points better performance, in 10 less cost compared to using GPT-4o-mini as the verifier. Our model, dataset, and code are publicly available at LINK.
Reasoning Models Better Express Their Confidence
May 20, 2025



Despite their strengths, large language models (LLMs) often fail to communicate their confidence accurately, making it difficult to assess when they might be wrong and limiting their reliability. In this work, we demonstrate that reasoning models-LLMs that engage in extended chain-of-thought (CoT) reasoning-exhibit superior performance not only in problem-solving but also in accurately expressing their confidence. Specifically, we benchmark six reasoning models across six datasets and find that they achieve strictly better confidence calibration than their non-reasoning counterparts in 33 out of the 36 settings. Our detailed analysis reveals that these gains in calibration stem from the slow thinking behaviors of reasoning models-such as exploring alternative approaches and backtracking-which enable them to adjust their confidence dynamically throughout their CoT, making it progressively more accurate. In particular, we find that reasoning models become increasingly better calibrated as their CoT unfolds, a trend not observed in non-reasoning models. Moreover, removing slow thinking behaviors from the CoT leads to a significant drop in calibration. Lastly, we show that these gains are not exclusive to reasoning models-non-reasoning models also benefit when guided to perform slow thinking via in-context learning.