 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-EXAONE Technical Report
Jan 05, 2026This technical report presents K-EXAONE, a large-scale multilingual language model developed by LG AI Research. K-EXAONE is built on a Mixture-of-Experts architecture with 236B total parameters, activating 23B parameters during inference. It supports a 256K-token context window and covers six languages: Korean, English, Spanish, German, Japanese, and Vietnamese. We evaluate K-EXAONE on a comprehensive benchmark suite spanning reasoning, agentic, general, Korean, and multilingual abilities. Across these evaluations, K-EXAONE demonstrates performance comparable to open-weight models of similar size. K-EXAONE, designed to advance AI for a better life, is positioned as a powerful proprietary AI foundation model for a wide range of industrial and research applications.
EXAONE 4.0: Unified Large Language Models Integrating Non-reasoning and Reasoning Modes
Jul 15, 2025This technical report introduces EXAONE 4.0, which integrates a Non-reasoning mode and a Reasoning mode to achieve both the excellent usability of EXAONE 3.5 and the advanced reasoning abilities of EXAONE Deep. To pave the way for the agentic AI era, EXAONE 4.0 incorporates essential features such as agentic tool use, and its multilingual capabilities are extended to support Spanish in addition to English and Korean. The EXAONE 4.0 model series consists of two sizes: a mid-size 32B model optimized for high performance, and a small-size 1.2B model designed for on-device applications. The EXAONE 4.0 demonstrates superior performance compared to open-weight models in its class and remains competitive even against frontier-class models. The models are publicly available for research purposes and can be easily downloaded via https://huggingface.co/LGAI-EXAONE.
KoBALT: Korean Benchmark For Advanced Linguistic Tasks
May 22, 2025We introduce KoBALT (Korean Benchmark for Advanced Linguistic Tasks), a comprehensive linguistically-motivated benchmark comprising 700 multiple-choice questions spanning 24 phenomena across five linguistic domains: syntax, semantics, pragmatics, phonetics/phonology, and morphology. KoBALT is designed to advance the evaluation of large language models (LLMs) in Korean, a morphologically rich language, by addressing the limitations of conventional benchmarks that often lack linguistic depth and typological grounding. It introduces a suite of expert-curated, linguistically motivated questions with minimal n-gram overlap with standard Korean corpora, substantially mitigating the risk of data contamination and allowing a more robust assessment of true language understanding. Our evaluation of 20 contemporary LLMs reveals significant performance disparities, with the highest-performing model achieving 61\% general accuracy but showing substantial variation across linguistic domains - from stronger performance in semantics (66\%) to considerable weaknesses in phonology (31\%) and morphology (36\%). Through human preference evaluation with 95 annotators, we demonstrate a strong correlation between KoBALT scores and human judgments, validating our benchmark's effectiveness as a discriminative measure of Korean language understanding. KoBALT addresses critical gaps in linguistic evaluation for typologically diverse languages and provides a robust framework for assessing genuine linguistic competence in Korean language models.
Reasoning Models Better Express Their Confidence
May 20, 2025Despite their strengths, large language models (LLMs) often fail to communicate their confidence accurately, making it difficult to assess when they might be wrong and limiting their reliability. In this work, we demonstrate that reasoning models-LLMs that engage in extended chain-of-thought (CoT) reasoning-exhibit superior performance not only in problem-solving but also in accurately expressing their confidence. Specifically, we benchmark six reasoning models across six datasets and find that they achieve strictly better confidence calibration than their non-reasoning counterparts in 33 out of the 36 settings. Our detailed analysis reveals that these gains in calibration stem from the slow thinking behaviors of reasoning models-such as exploring alternative approaches and backtracking-which enable them to adjust their confidence dynamically throughout their CoT, making it progressively more accurate. In particular, we find that reasoning models become increasingly better calibrated as their CoT unfolds, a trend not observed in non-reasoning models. Moreover, removing slow thinking behaviors from the CoT leads to a significant drop in calibration. Lastly, we show that these gains are not exclusive to reasoning models-non-reasoning models also benefit when guided to perform slow thinking via in-context learning.
EXAONE Deep: Reasoning Enhanced Language Models
Mar 16, 2025We present EXAONE Deep series, which exhibits superior capabilities in various reasoning tasks, including math and coding benchmarks. We train our models mainly on the reasoning-specialized dataset that incorporates long streams of thought processes. Evaluation results show that our smaller models, EXAONE Deep 2.4B and 7.8B, outperform other models of comparable size, while the largest model, EXAONE Deep 32B, demonstrates competitive performance against leading open-weight models. All EXAONE Deep models are openly available for research purposes and can be downloaded from https://huggingface.co/LGAI-EXAONE
EXAONE 3.5: Series of Large Language Models for Real-world Use Cases
Dec 09, 2024



This technical report introduces the EXAONE 3.5 instruction-tuned language models, developed and released by LG AI Research. The EXAONE 3.5 language models are offered in three configurations: 32B, 7.8B, and 2.4B. These models feature several standout capabilities: 1) exceptional instruction following capabilities in real-world scenarios, achieving the highest scores across seven benchmarks, 2) outstanding long-context comprehension, attaining the top performance in four benchmarks, and 3) competitive results compared to state-of-the-art open models of similar sizes across nine general benchmarks. The EXAONE 3.5 language models are open to anyone for research purposes and can be downloaded from https://huggingface.co/LGAI-EXAONE. For commercial use, please reach out to the official contact point of LG AI Research: contact_us@lgresearch.ai.
EXAONE 3.0 7.8B Instruction Tuned Language Model
Aug 07, 2024



We introduce EXAONE 3.0 instruction-tuned language model, the first open model in the family of Large Language Models (LLMs) developed by LG AI Research. Among different model sizes, we publicly release the 7.8B instruction-tuned model to promote open research and innovations. Through extensive evaluations across a wide range of public and in-house benchmarks, EXAONE 3.0 demonstrates highly competitive real-world performance with instruction-following capability against other state-of-the-art open models of similar size. Our comparative analysis shows that EXAONE 3.0 excels particularly in Korean, while achieving compelling performance across general tasks and complex reasoning. With its strong real-world effectiveness and bilingual proficiency, we hope that EXAONE keeps contributing to advancements in Expert AI. Our EXAONE 3.0 instruction-tuned model is available at https://huggingface.co/LGAI-EXAONE/EXAONE-3.0-7.8B-Instruct
Boosting Cross-lingual Transferability in Multilingual Models via In-Context Learning
May 24, 2023Existing cross-lingual transfer (CLT) prompting methods are only concerned with monolingual demonstration examples in the source language. In this paper, we propose In-CLT, a novel cross-lingual transfer prompting method that leverages both source and target languages to construct the demonstration examples. We conduct comprehensive evaluations on multilingual benchmarks, focusing on question answering tasks. Experiment results show that In-CLT prompt not only improves multilingual models' cross-lingual transferability, but also demonstrates remarkable unseen language generalization ability. In-CLT prompting, in particular, improves model performance by 10 to 20\% points on average when compared to prior cross-lingual transfer approaches. We also observe the surprising performance gain on the other multilingual benchmarks, especially in reasoning tasks. Furthermore, we investigate the relationship between lexical similarity and pre-training corpora in terms of the cross-lingual transfer gap.
KLUE: Korean Language Understanding Evaluation
Jun 11, 2021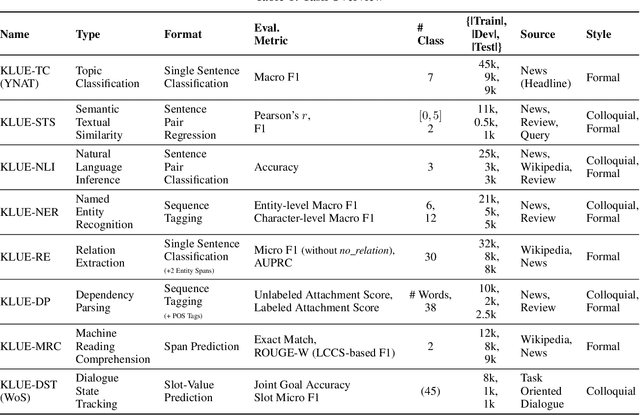
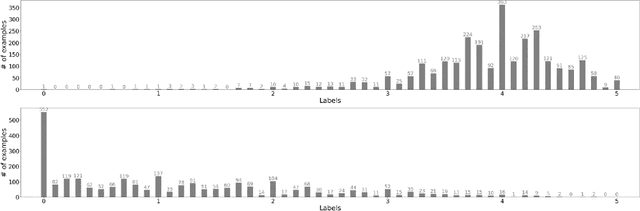
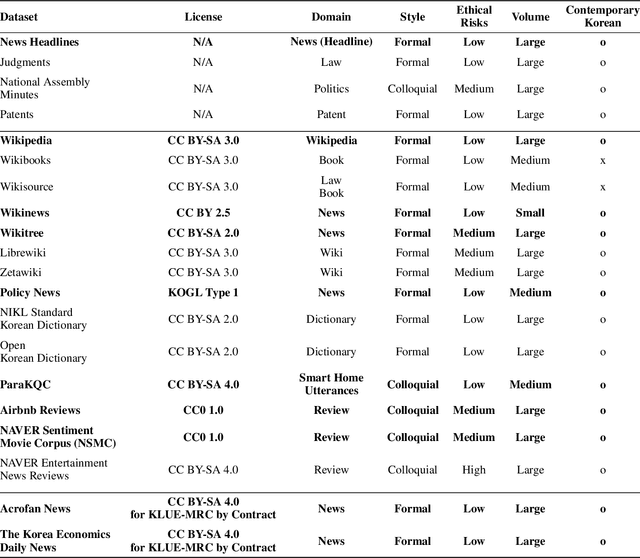
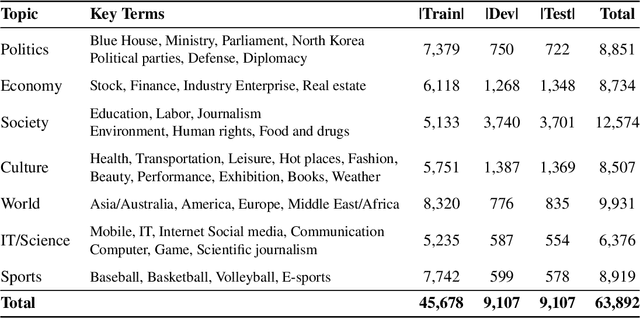
We introduce Korean Language Understanding Evaluation (KLUE) benchmark. KLUE is a collection of 8 Korean natural language understanding (NLU) tasks, including Topic Classification, SemanticTextual Similarity, Natural Language Inference, Named Entity Recognition, Relation Extraction, Dependency Parsing, Machine Reading Comprehension, and Dialogue State Tracking. We build all of the tasks from scratch from diverse source corpora while respecting copyrights, to ensure accessibility for anyone without any restrictions. With ethical considerations in mind, we carefully design annotation protocols. Along with the benchmark tasks and data, we provide suitable evaluation metrics and fine-tuning recipes for pretrained language models for each task. We furthermore release the pretrained language models (PLM), KLUE-BERT and KLUE-RoBERTa, to help reproducing baseline models on KLUE and thereby facilitate future research. We make a few interesting observations from the preliminary experiments using the proposed KLUE benchmark suite, already demonstrating the usefulness of this new benchmark suite. First, we find KLUE-RoBERTa-large outperforms other baselines, including multilingual PLMs and existing open-source Korean PLMs. Second, we see minimal degradation in performance even when we replace personally identifiable information from the pretraining corpus, suggesting that privacy and NLU capability are not at odds with each other. Lastly, we find that using BPE tokenization in combination with morpheme-level pre-tokenization is effective in tasks involving morpheme-level tagging, detection and generation. In addition to accelerating Korean NLP research, our comprehensive documentation on creating KLUE will facilitate creating similar resources for other languages in the future. KLUE is available at https://klue-benchmark.com.