 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes Good Multilingual Reasoning? Disentangling Reasoning Traces with Measurable Features
Apr 06, 2026Large Reasoning Models (LRMs) still exhibit large performance gaps between English and other languages, yet much current work assumes these gaps can be closed simply by making reasoning in every language resemble English reasoning. This work challenges this assumption by asking instead: what actually characterizes effective reasoning in multilingual settings, and to what extent do English-derived reasoning features genuinely help in other languages? We first define a suite of measurable reasoning features spanning multilingual alignment, reasoning step, and reasoning flow aspects of reasoning traces, and use logistic regression to quantify how each feature associates with final answer accuracy. We further train sparse autoencoders over multilingual traces to automatically discover latent reasoning concepts that instantiate or extend these features. Finally, we use the features as test-time selection policies to examine whether they can steer models toward stronger multilingual reasoning. Across two mathematical reasoning benchmarks, four LRMs, and 10 languages, we find that most features are positively associated with accuracy, but the strength of association varies considerably across languages and can even reverse in some. Our findings challenge English-centric reward designs and point toward adaptive objectives that accommodate language-specific reasoning patterns, with concrete implications for multilingual benchmark and reward design.
Pragmatics Meets Culture: Culturally-adapted Artwork Description Generation and Evaluation
Apr 02, 2026Language models are known to exhibit various forms of cultural bias in decision-making tasks, yet much less is known about their degree of cultural familiarity in open-ended text generation tasks. In this paper, we introduce the task of culturally-adapted art description generation, where models describe artworks for audiences from different cultural groups who vary in their familiarity with the cultural symbols and narratives embedded in the artwork. To evaluate cultural competence in this pragmatic generation task, we propose a framework based on culturally grounded question answering. We find that base models are only marginally adequate for this task, but, through a pragmatic speaker model, we can improve simulated listener comprehension by up to 8.2%. A human study further confirms that the model with higher pragmatic competence is rated as more helpful for comprehension by 8.0%.
When AI Benchmarks Plateau: A Systematic Study of Benchmark Saturation
Feb 18, 2026Artificial Intelligence (AI) benchmarks play a central role in measuring progress in model development and guiding deployment decisions. However, many benchmarks quickly become saturated, meaning that they can no longer differentiate between the best-performing models, diminishing their long-term value. In this study, we analyze benchmark saturation across 60 Large Language Model (LLM) benchmarks selected from technical reports by major model developers. To identify factors driving saturation, we characterize benchmarks along 14 properties spanning task design, data construction, and evaluation format. We test five hypotheses examining how each property contributes to saturation rates. Our analysis reveals that nearly half of the benchmarks exhibit saturation, with rates increasing as benchmarks age. Notably, hiding test data (i.e., public vs. private) shows no protective effect, while expert-curated benchmarks resist saturation better than crowdsourced ones. Our findings highlight which design choices extend benchmark longevity and inform strategies for more durable evaluation.
Linguistic Nepotism: Trading-off Quality for Language Preference in Multilingual RAG
Sep 17, 2025Multilingual Retrieval-Augmented Generation (mRAG) systems enable language models to answer knowledge-intensive queries with citation-supported responses across languages. While such systems have been proposed, an open questions is whether the mixture of different document languages impacts generation and citation in unintended ways. To investigate, we introduce a controlled methodology using model internals to measure language preference while holding other factors such as document relevance constant. Across eight languages and six open-weight models, we find that models preferentially cite English sources when queries are in English, with this bias amplified for lower-resource languages and for documents positioned mid-context. Crucially, we find that models sometimes trade-off document relevance for language preference, indicating that citation choices are not always driven by informativeness alone. Our findings shed light on how language models leverage multilingual context and influence citation behavior.
Multiple LLM Agents Debate for Equitable Cultural Alignment
May 30, 2025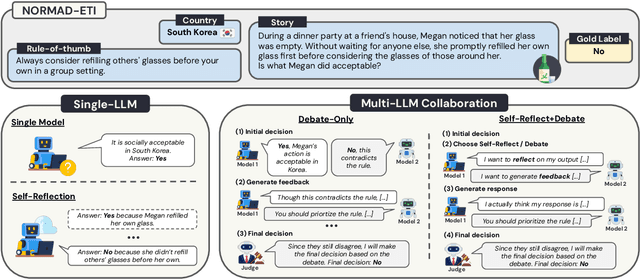
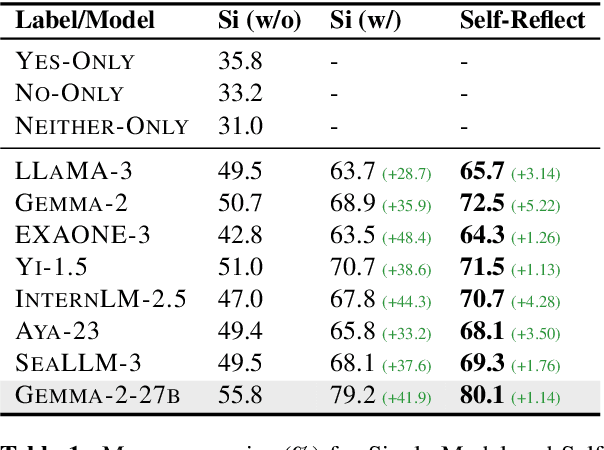
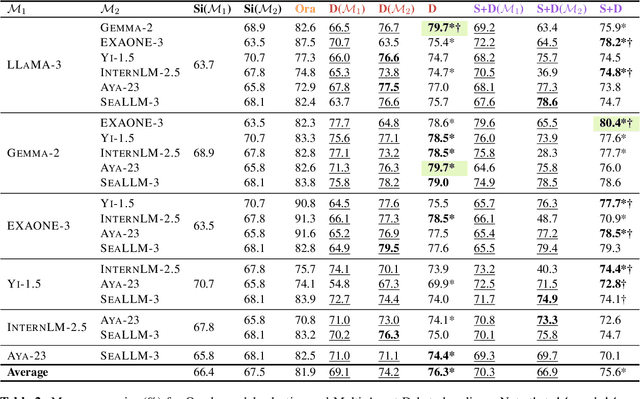
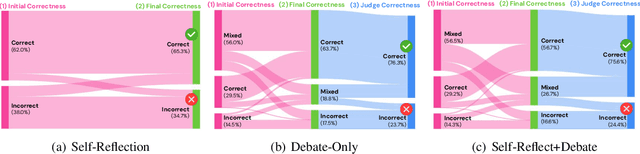
Large Language Models (LLMs) need to adapt their predictions to diverse cultural contexts to benefit diverse communities across the world. While previous efforts have focused on single-LLM, single-turn approaches, we propose to exploit the complementary strengths of multiple LLMs to promote cultural adaptability. We introduce a Multi-Agent Debate framework, where two LLM-based agents debate over a cultural scenario and collaboratively reach a final decision. We propose two variants: one where either LLM agents exclusively debate and another where they dynamically choose between self-reflection and debate during their turns. We evaluate these approaches on 7 open-weight LLMs (and 21 LLM combinations) using the NormAd-ETI benchmark for social etiquette norms in 75 countries. Experiments show that debate improves both overall accuracy and cultural group parity over single-LLM baselines. Notably, multi-agent debate enables relatively small LLMs (7-9B) to achieve accuracies comparable to that of a much larger model (27B parameters).
Should I Share this Translation? Evaluating Quality Feedback for User Reliance on Machine Translation
May 30, 2025As people increasingly use AI systems in work and daily life, feedback mechanisms that help them use AI responsibly are urgently needed, particularly in settings where users are not equipped to assess the quality of AI predictions. We study a realistic Machine Translation (MT) scenario where monolingual users decide whether to share an MT output, first without and then with quality feedback. We compare four types of quality feedback: explicit feedback that directly give users an assessment of translation quality using 1) error highlights and 2) LLM explanations, and implicit feedback that helps users compare MT inputs and outputs through 3) backtranslation and 4) question-answer (QA) tables. We find that all feedback types, except error highlights, significantly improve both decision accuracy and appropriate reliance. Notably, implicit feedback, especially QA tables, yields significantly greater gains than explicit feedback in terms of decision accuracy, appropriate reliance, and user perceptions, receiving the highest ratings for helpfulness and trust, and the lowest for mental burden.
GraphicBench: A Planning Benchmark for Graphic Design with Language Agents
Apr 15, 2025



Large Language Model (LLM)-powered agents have unlocked new possibilities for automating human tasks. While prior work has focused on well-defined tasks with specified goals, the capabilities of agents in creative design tasks with open-ended goals remain underexplored. We introduce GraphicBench, a new planning benchmark for graphic design that covers 1,079 user queries and input images across four design types. We further present GraphicTown, an LLM agent framework with three design experts and 46 actions (tools) to choose from for executing each step of the planned workflows in web environments. Experiments with six LLMs demonstrate their ability to generate workflows that integrate both explicit design constraints from user queries and implicit commonsense constraints. However, these workflows often do not lead to successful execution outcomes, primarily due to challenges in: (1) reasoning about spatial relationships, (2) coordinating global dependencies across experts, and (3) retrieving the most appropriate action per step. We envision GraphicBench as a challenging yet valuable testbed for advancing LLM-agent planning and execution in creative design tasks.
AskQE: Question Answering as Automatic Evaluation for Machine Translation
Apr 15, 2025How can a monolingual English speaker determine whether an automatic translation in French is good enough to be shared? Existing MT error detection and quality estimation (QE) techniques do not address this practical scenario. We introduce AskQE, a question generation and answering framework designed to detect critical MT errors and provide actionable feedback, helping users decide whether to accept or reject MT outputs even without the knowledge of the target language. Using ContraTICO, a dataset of contrastive synthetic MT errors in the COVID-19 domain, we explore design choices for AskQE and develop an optimized version relying on LLaMA-3 70B and entailed facts to guide question generation. We evaluate the resulting system on the BioMQM dataset of naturally occurring MT errors, where AskQE has higher Kendall's Tau correlation and decision accuracy with human ratings compared to other QE metrics.
Automatic Input Rewriting Improves Translation with Large Language Models
Feb 23, 2025



Can we improve machine translation (MT) with LLMs by rewriting their inputs automatically? Users commonly rely on the intuition that well-written text is easier to translate when using off-the-shelf MT systems. LLMs can rewrite text in many ways but in the context of MT, these capabilities have been primarily exploited to rewrite outputs via post-editing. We present an empirical study of 21 input rewriting methods with 3 open-weight LLMs for translating from English into 6 target languages. We show that text simplification is the most effective MT-agnostic rewrite strategy and that it can be improved further when using quality estimation to assess translatability. Human evaluation further confirms that simplified rewrites and their MT outputs both largely preserve the original meaning of the source and MT. These results suggest LLM-assisted input rewriting as a promising direction for improving translations.
* 27 pages, 8 figures
The Prompt Report: A Systematic Survey of Prompting Techniques
Jun 06, 2024Generative Artificial Intelligence (GenAI) systems are being increasingly deployed across all parts of industry and research settings. Developers and end users interact with these systems through the use of prompting or prompt engineering. While prompting is a widespread and highly researched concept, there exists conflicting terminology and a poor ontological understanding of what constitutes a prompt due to the area's nascency. This paper establishes a structured understanding of prompts, by assembling a taxonomy of prompting techniques and analyzing their use. We present a comprehensive vocabulary of 33 vocabulary terms, a taxonomy of 58 text-only prompting techniques, and 40 techniques for other modalities. We further present a meta-analysis of the entire literature on natural language prefix-prompting.