 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiCSAR: Probabilistic Confidence Selection And Ranking
Aug 29, 2025Best-of-n sampling improves the accuracy of large language models (LLMs) and large reasoning models (LRMs) by generating multiple candidate solutions and selecting the one with the highest reward. The key challenge for reasoning tasks is designing a scoring function that can identify correct reasoning chains without access to ground-truth answers. We propose Probabilistic Confidence Selection And Ranking (PiCSAR): a simple, training-free method that scores each candidate generation using the joint log-likelihood of the reasoning and final answer. The joint log-likelihood of the reasoning and final answer naturally decomposes into reasoning confidence and answer confidence. PiCSAR achieves substantial gains across diverse benchmarks (+10.18 on MATH500, +9.81 on AIME2025), outperforming baselines with at least 2x fewer samples in 16 out of 20 comparisons. Our analysis reveals that correct reasoning chains exhibit significantly higher reasoning and answer confidence, justifying the effectiveness of PiCSAR.
How Well Can Reasoning Models Identify and Recover from Unhelpful Thoughts?
Jun 12, 2025Recent reasoning models show the ability to reflect, backtrack, and self-validate their reasoning, which is crucial in spotting mistakes and arriving at accurate solutions. A natural question that arises is how effectively models can perform such self-reevaluation. We tackle this question by investigating how well reasoning models identify and recover from four types of unhelpful thoughts: uninformative rambling thoughts, thoughts irrelevant to the question, thoughts misdirecting the question as a slightly different question, and thoughts that lead to incorrect answers. We show that models are effective at identifying most unhelpful thoughts but struggle to recover from the same thoughts when these are injected into their thinking process, causing significant performance drops. Models tend to naively continue the line of reasoning of the injected irrelevant thoughts, which showcases that their self-reevaluation abilities are far from a general "meta-cognitive" awareness. Moreover, we observe non/inverse-scaling trends, where larger models struggle more than smaller ones to recover from short irrelevant thoughts, even when instructed to reevaluate their reasoning. We demonstrate the implications of these findings with a jailbreak experiment using irrelevant thought injection, showing that the smallest models are the least distracted by harmful-response-triggering thoughts. Overall, our findings call for improvement in self-reevaluation of reasoning models to develop better reasoning and safer systems.
Let's Predict Sentence by Sentence
May 28, 2025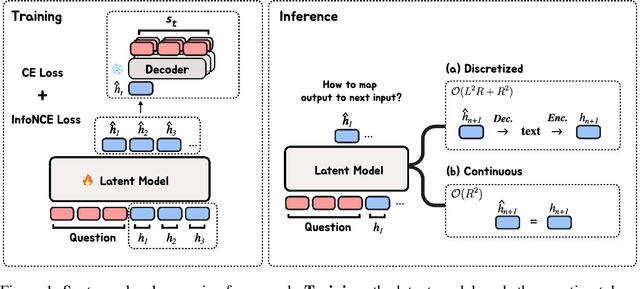
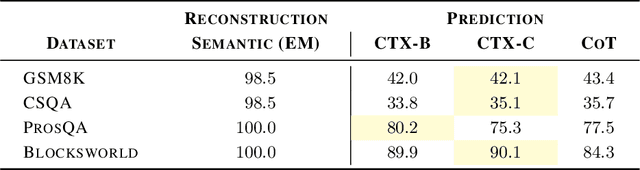
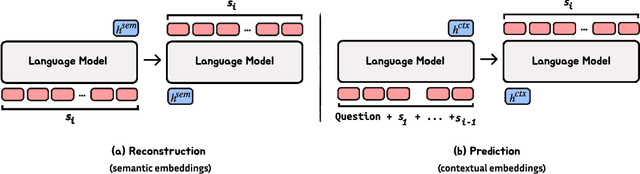
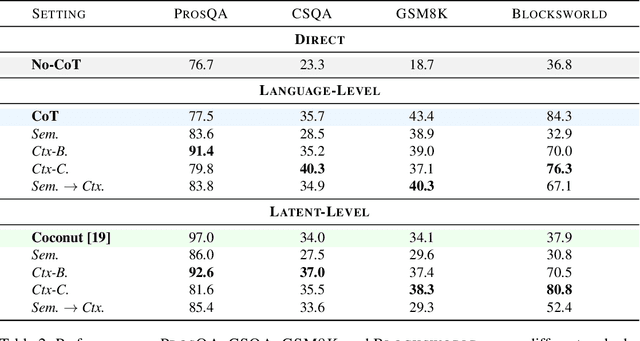
Autoregressive language models (LMs) generate one token at a time, yet human reasoning operates over higher-level abstractions - sentences, propositions, and concepts. This contrast raises a central question- Can LMs likewise learn to reason over structured semantic units rather than raw token sequences? In this work, we investigate whether pretrained LMs can be lifted into such abstract reasoning spaces by building on their learned representations. We present a framework that adapts a pretrained token-level LM to operate in sentence space by autoregressively predicting continuous embeddings of next sentences. We explore two embedding paradigms inspired by classical representation learning: 1) semantic embeddings, learned via autoencoding to preserve surface meaning; and 2) contextual embeddings, trained via next-sentence prediction to encode anticipatory structure. We evaluate both under two inference regimes: Discretized, which decodes each predicted embedding into text before re-encoding; and Continuous, which reasons entirely in embedding space for improved efficiency. Across four domains - mathematics, logic, commonsense, and planning - contextual embeddings under continuous inference show competitive performance with Chain-of-Thought (CoT) while reducing inference-time FLOPs on average by half. We also present early signs of scalability and modular adaptation. Finally, to visualize latent trajectories, we introduce SentenceLens, a diagnostic tool that decodes intermediate model states into interpretable sentences. Together, our results indicate that pretrained LMs can effectively transition to abstract, structured reasoning within latent embedding spaces.
The Coverage Principle: A Framework for Understanding Compositional Generalization
May 26, 2025Large language models excel at pattern matching, yet often fall short in systematic compositional generalization. We propose the coverage principle: a data-centric framework showing that models relying primarily on pattern matching for compositional tasks cannot reliably generalize beyond substituting fragments that yield identical results when used in the same contexts. We demonstrate that this framework has a strong predictive power for the generalization capabilities of Transformers. First, we derive and empirically confirm that the training data required for two-hop generalization grows at least quadratically with the token set size, and the training data efficiency does not improve with 20x parameter scaling. Second, for compositional tasks with path ambiguity where one variable affects the output through multiple computational paths, we show that Transformers learn context-dependent state representations that undermine both performance and interoperability. Third, Chain-of-Thought supervision improves training data efficiency for multi-hop tasks but still struggles with path ambiguity. Finally, we outline a \emph{mechanism-based} taxonomy that distinguishes three ways neural networks can generalize: structure-based (bounded by coverage), property-based (leveraging algebraic invariances), and shared-operator (through function reuse). This conceptual lens contextualizes our results and highlights where new architectural ideas are needed to achieve systematic compositionally. Overall, the coverage principle provides a unified lens for understanding compositional reasoning, and underscores the need for fundamental architectural or training innovations to achieve truly systematic compositionality.
Reasoning Models Better Express Their Confidence
May 20, 2025



Despite their strengths, large language models (LLMs) often fail to communicate their confidence accurately, making it difficult to assess when they might be wrong and limiting their reliability. In this work, we demonstrate that reasoning models-LLMs that engage in extended chain-of-thought (CoT) reasoning-exhibit superior performance not only in problem-solving but also in accurately expressing their confidence. Specifically, we benchmark six reasoning models across six datasets and find that they achieve strictly better confidence calibration than their non-reasoning counterparts in 33 out of the 36 settings. Our detailed analysis reveals that these gains in calibration stem from the slow thinking behaviors of reasoning models-such as exploring alternative approaches and backtracking-which enable them to adjust their confidence dynamically throughout their CoT, making it progressively more accurate. In particular, we find that reasoning models become increasingly better calibrated as their CoT unfolds, a trend not observed in non-reasoning models. Moreover, removing slow thinking behaviors from the CoT leads to a significant drop in calibration. Lastly, we show that these gains are not exclusive to reasoning models-non-reasoning models also benefit when guided to perform slow thinking via in-context learning.
Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?
Nov 25, 2024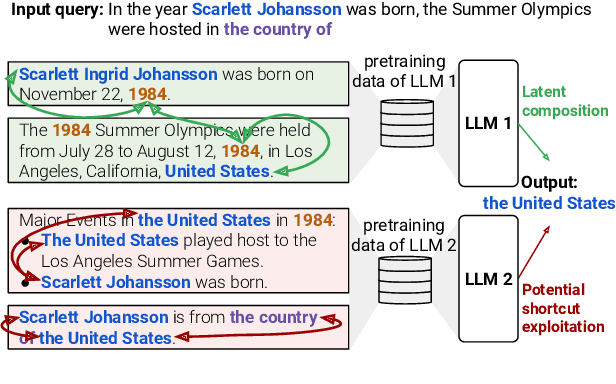
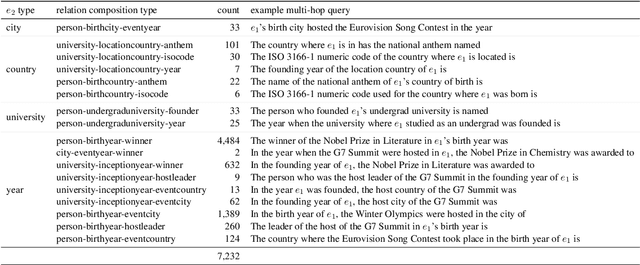
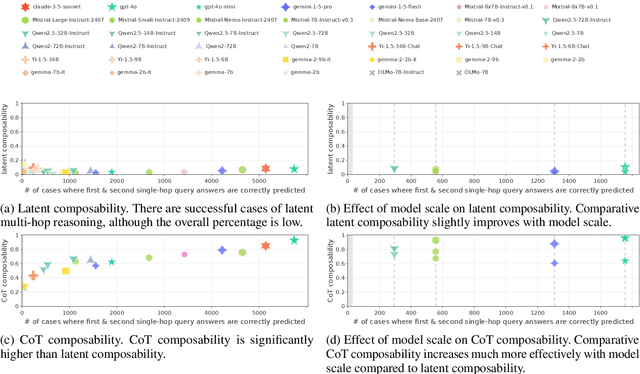

We evaluate how well Large Language Models (LLMs) latently recall and compose facts to answer multi-hop queries like "In the year Scarlett Johansson was born, the Summer Olympics were hosted in the country of". One major challenge in evaluating this ability is that LLMs may have developed shortcuts by encounters of the head entity "Scarlett Johansson" and the answer entity "United States" in the same training sequences or merely guess the answer based on frequency-based priors. To prevent shortcuts, we exclude test queries where the head and answer entities co-appear in pretraining corpora. Through careful selection of relations and facts and systematic removal of cases where models might guess answers or exploit partial matches, we construct an evaluation dataset SOCRATES (ShOrtCut-fRee lATent rEaSoning). We observe that LLMs demonstrate promising latent multi-hop reasoning abilities without exploiting shortcuts, but only for certain types of queries. For queries requiring latent recall of countries as the intermediate answer, the best models achieve 80% latent composability, but this drops to just 5% for the recall of years. Comparisons with Chain-of-Thought composability highlight a significant gap between the ability of models to reason latently versus explicitly. Analysis reveals that latent representations of the intermediate answer are constructed more often in queries with higher latent composability, and shows the emergence of latent multi-hop reasoning during pretraining.
Hopping Too Late: Exploring the Limitations of Large Language Models on Multi-Hop Queries
Jun 18, 2024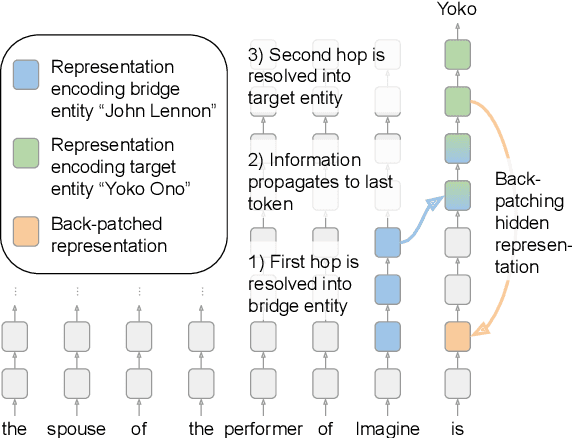



Large language models (LLMs) can solve complex multi-step problems, but little is known about how these computations are implemented internally. Motivated by this, we study how LLMs answer multi-hop queries such as "The spouse of the performer of Imagine is". These queries require two information extraction steps: a latent one for resolving the first hop ("the performer of Imagine") into the bridge entity (John Lennon), and one for resolving the second hop ("the spouse of John Lennon") into the target entity (Yoko Ono). Understanding how the latent step is computed internally is key to understanding the overall computation. By carefully analyzing the internal computations of transformer-based LLMs, we discover that the bridge entity is resolved in the early layers of the model. Then, only after this resolution, the two-hop query is solved in the later layers. Because the second hop commences in later layers, there could be cases where these layers no longer encode the necessary knowledge for correctly predicting the answer. Motivated by this, we propose a novel "back-patching" analysis method whereby a hidden representation from a later layer is patched back to an earlier layer. We find that in up to 57% of previously incorrect cases there exists a back-patch that results in the correct generation of the answer, showing that the later layers indeed sometimes lack the needed functionality. Overall our methods and findings open further opportunities for understanding and improving latent reasoning in transformer-based LLMs.
How Do Large Language Models Acquire Factual Knowledge During Pretraining?
Jun 17, 2024



Despite the recent observation that large language models (LLMs) can store substantial factual knowledge, there is a limited understanding of the mechanisms of how they acquire factual knowledge through pretraining. This work addresses this gap by studying how LLMs acquire factual knowledge during pretraining. The findings reveal several important insights into the dynamics of factual knowledge acquisition during pretraining. First, counterintuitively, we observe that pretraining on more data shows no significant improvement in the model's capability to acquire and maintain factual knowledge. Next, there is a power-law relationship between training steps and forgetting of memorization and generalization of factual knowledge, and LLMs trained with duplicated training data exhibit faster forgetting. Third, training LLMs with larger batch sizes can enhance the models' robustness to forgetting. Overall, our observations suggest that factual knowledge acquisition in LLM pretraining occurs by progressively increasing the probability of factual knowledge presented in the pretraining data at each step. However, this increase is diluted by subsequent forgetting. Based on this interpretation, we demonstrate that we can provide plausible explanations for recently observed behaviors of LLMs, such as the poor performance of LLMs on long-tail knowledge and the benefits of deduplicating the pretraining corpus.
Do Large Language Models Latently Perform Multi-Hop Reasoning?
Feb 26, 2024



We study whether Large Language Models (LLMs) latently perform multi-hop reasoning with complex prompts such as "The mother of the singer of 'Superstition' is". We look for evidence of a latent reasoning pathway where an LLM (1) latently identifies "the singer of 'Superstition'" as Stevie Wonder, the bridge entity, and (2) uses its knowledge of Stevie Wonder's mother to complete the prompt. We analyze these two hops individually and consider their co-occurrence as indicative of latent multi-hop reasoning. For the first hop, we test if changing the prompt to indirectly mention the bridge entity instead of any other entity increases the LLM's internal recall of the bridge entity. For the second hop, we test if increasing this recall causes the LLM to better utilize what it knows about the bridge entity. We find strong evidence of latent multi-hop reasoning for the prompts of certain relation types, with the reasoning pathway used in more than 80% of the prompts. However, the utilization is highly contextual, varying across different types of prompts. Also, on average, the evidence for the second hop and the full multi-hop traversal is rather moderate and only substantial for the first hop. Moreover, we find a clear scaling trend with increasing model size for the first hop of reasoning but not for the second hop. Our experimental findings suggest potential challenges and opportunities for future development and applications of LLMs.
Improving Probability-based Prompt Selection Through Unified Evaluation and Analysis
May 24, 2023Large Language Models (LLMs) have demonstrated great capabilities in solving a wide range of tasks in a resource-efficient manner through prompting, which does not require task-specific training, but suffers from performance fluctuation when there are multiple prompt candidates. Previous works have introduced gradient-free probability-based prompt selection methods that aim to choose the optimal prompt among the candidates for a given task but fail to provide a comprehensive and fair comparison between each other. In this paper, we propose a unified framework to interpret and evaluate the existing probability-based prompt selection methods by performing extensive experiments on 13 common NLP tasks. We find that all existing methods can be unified into some variant of the method that maximizes the mutual information between the input and the corresponding model output (denoted as MI). Using the finding, we develop several variants of MI and increases the effectiveness of the best prompt selection method from 87.79% to 94.98%, measured as the ratio of the performance of the selected prompt to that of the optimal oracle prompt. Furthermore, we propose a novel calibration method called Calibration by Marginalization (CBM) that is orthogonal to existing methods and helps increase the prompt selection effectiveness of the best method by 99.44%. The code and datasets used in our work will be released at https://github.com/soheeyang/unified-prompt-selection.