 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan I Have Your Order? Monte-Carlo Tree Search for Slot Filling Ordering in Diffusion Language Models
Feb 13, 2026While plan-and-infill decoding in Masked Diffusion Models (MDMs) shows promise for mathematical and code reasoning, performance remains highly sensitive to slot infilling order, often yielding substantial output variance. We introduce McDiffuSE, a framework that formulates slot selection as decision making and optimises infilling orders through Monte Carlo Tree Search (MCTS). McDiffuSE uses look-ahead simulations to evaluate partial completions before commitment, systematically exploring the combinatorial space of generation orders. Experiments show an average improvement of 3.2% over autoregressive baselines and 8.0% over baseline plan-and-infill, with notable gains of 19.5% on MBPP and 4.9% on MATH500. Our analysis reveals that while McDiffuSE predominantly follows sequential ordering, incorporating non-sequential generation is essential for maximising performance. We observe that larger exploration constants, rather than increased simulations, are necessary to overcome model confidence biases and discover effective orderings. These findings establish MCTS-based planning as an effective approach for enhancing generation quality in MDMs.
Neural Theorem Proving for Verification Conditions: A Real-World Benchmark
Jan 26, 2026Theorem proving is fundamental to program verification, where the automated proof of Verification Conditions (VCs) remains a primary bottleneck. Real-world program verification frequently encounters hard VCs that existing Automated Theorem Provers (ATPs) cannot prove, leading to a critical need for extensive manual proofs that burden practical application. While Neural Theorem Proving (NTP) has achieved significant success in mathematical competitions, demonstrating the potential of machine learning approaches to formal reasoning, its application to program verification--particularly VC proving--remains largely unexplored. Despite existing work on annotation synthesis and verification-related theorem proving, no benchmark has specifically targeted this fundamental bottleneck: automated VC proving. This work introduces Neural Theorem Proving for Verification Conditions (NTP4VC), presenting the first real-world multi-language benchmark for this task. From real-world projects such as Linux and Contiki-OS kernel, our benchmark leverages industrial pipelines (Why3 and Frama-C) to generate semantically equivalent test cases across formal languages of Isabelle, Lean, and Rocq. We evaluate large language models (LLMs), both general-purpose and those fine-tuned for theorem proving, on NTP4VC. Results indicate that although LLMs show promise in VC proving, significant challenges remain for program verification, highlighting a large gap and opportunity for future research.
PiCSAR: Probabilistic Confidence Selection And Ranking
Aug 29, 2025Best-of-n sampling improves the accuracy of large language models (LLMs) and large reasoning models (LRMs) by generating multiple candidate solutions and selecting the one with the highest reward. The key challenge for reasoning tasks is designing a scoring function that can identify correct reasoning chains without access to ground-truth answers. We propose Probabilistic Confidence Selection And Ranking (PiCSAR): a simple, training-free method that scores each candidate generation using the joint log-likelihood of the reasoning and final answer. The joint log-likelihood of the reasoning and final answer naturally decomposes into reasoning confidence and answer confidence. PiCSAR achieves substantial gains across diverse benchmarks (+10.18 on MATH500, +9.81 on AIME2025), outperforming baselines with at least 2x fewer samples in 16 out of 20 comparisons. Our analysis reveals that correct reasoning chains exhibit significantly higher reasoning and answer confidence, justifying the effectiveness of PiCSAR.
Theorem Prover as a Judge for Synthetic Data Generation
Feb 18, 2025The demand for synthetic data in mathematical reasoning has increased due to its potential to enhance the mathematical capabilities of large language models (LLMs). However, ensuring the validity of intermediate reasoning steps remains a significant challenge, affecting data quality. While formal verification via theorem provers effectively validates LLM reasoning, the autoformalisation of mathematical proofs remains error-prone. In response, we introduce iterative autoformalisation, an approach that iteratively refines theorem prover formalisation to mitigate errors, thereby increasing the execution rate on the Lean prover from 60% to 87%. Building upon that, we introduce Theorem Prover as a Judge (TP-as-a-Judge), a method that employs theorem prover formalisation to rigorously assess LLM intermediate reasoning, effectively integrating autoformalisation with synthetic data generation. Finally, we present Reinforcement Learning from Theorem Prover Feedback (RLTPF), a framework that replaces human annotation with theorem prover feedback in Reinforcement Learning from Human Feedback (RLHF). Across multiple LLMs, applying TP-as-a-Judge and RLTPF improves benchmarks with only 3,508 samples, achieving 5.56% accuracy gain on Mistral-7B for MultiArith, 6.00% on Llama-2-7B for SVAMP, and 3.55% on Llama-3.1-8B for AQUA.
CoMAT: Chain of Mathematically Annotated Thought Improves Mathematical Reasoning
Oct 14, 2024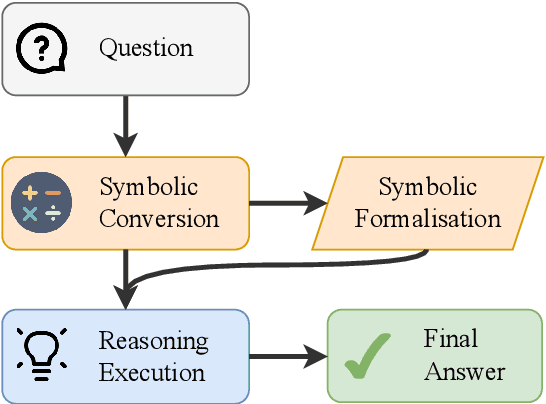
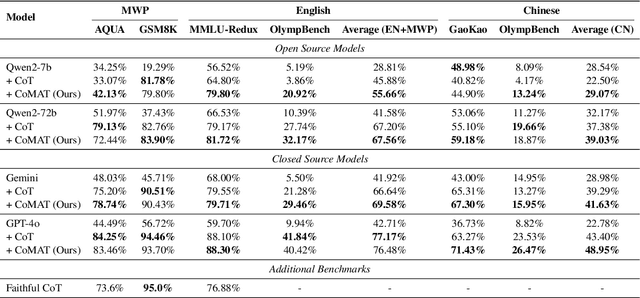
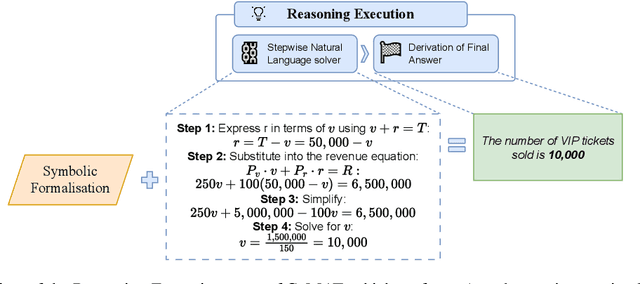
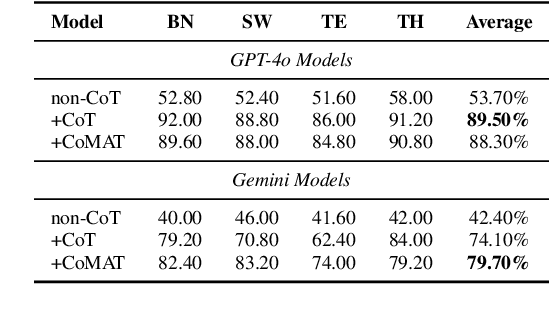
Mathematical reasoning remains a significant challenge for large language models (LLMs), despite progress in prompting techniques such as Chain-of-Thought (CoT). We present Chain of Mathematically Annotated Thought (CoMAT), which enhances reasoning through two stages: Symbolic Conversion (converting natural language queries into symbolic form) and Reasoning Execution (deriving answers from symbolic representations). CoMAT operates entirely with a single LLM and without external solvers. Across four LLMs, CoMAT outperforms traditional CoT on six out of seven benchmarks, achieving gains of 4.48% on MMLU-Redux (MATH) and 4.58% on GaoKao MCQ. In addition to improved performance, CoMAT ensures faithfulness and verifiability, offering a transparent reasoning process for complex mathematical tasks
Are We Done with MMLU?
Jun 07, 2024



Maybe not. We identify and analyse errors in the popular Massive Multitask Language Understanding (MMLU) benchmark. Even though MMLU is widely adopted, our analysis demonstrates numerous ground truth errors that obscure the true capabilities of LLMs. For example, we find that 57% of the analysed questions in the Virology subset contain errors. To address this issue, we introduce a comprehensive framework for identifying dataset errors using a novel error taxonomy. Then, we create MMLU-Redux, which is a subset of 3,000 manually re-annotated questions across 30 MMLU subjects. Using MMLU-Redux, we demonstrate significant discrepancies with the model performance metrics that were originally reported. Our results strongly advocate for revising MMLU's error-ridden questions to enhance its future utility and reliability as a benchmark. Therefore, we open up MMLU-Redux for additional annotation https://huggingface.co/datasets/edinburgh-dawg/mmlu-redux.