 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoTool: Self-Evolving Tool-Use Policy Optimization in LLM Agents via Blame-Aware Mutation and Diversity-Aware Selection
Mar 05, 2026LLM-based agents depend on effective tool-use policies to solve complex tasks, yet optimizing these policies remains challenging due to delayed supervision and the difficulty of credit assignment in long-horizon trajectories. Existing optimization approaches tend to be either monolithic, which are prone to entangling behaviors, or single-aspect, which ignore cross-module error propagation. To address these limitations, we propose EvoTool, a self-evolving framework that optimizes a modular tool-use policy via a gradient-free evolutionary paradigm. EvoTool decomposes agent's tool-use policy into four modules, including Planner, Selector, Caller, and Synthesizer, and iteratively improves them in a self-improving loop through three novel mechanisms. Trajectory-Grounded Blame Attribution uses diagnostic traces to localize failures to a specific module. Feedback-Guided Targeted Mutation then edits only that module via natural-language critique. Diversity-Aware Population Selection preserves complementary candidates to ensure solution diversity. Across four benchmarks, EvoTool outperforms strong baselines by over 5 points on both GPT-4.1 and Qwen3-8B, while achieving superior efficiency and transferability. The code will be released once paper is accepted.
Are We Done with MMLU?
Jun 07, 2024



Maybe not. We identify and analyse errors in the popular Massive Multitask Language Understanding (MMLU) benchmark. Even though MMLU is widely adopted, our analysis demonstrates numerous ground truth errors that obscure the true capabilities of LLMs. For example, we find that 57% of the analysed questions in the Virology subset contain errors. To address this issue, we introduce a comprehensive framework for identifying dataset errors using a novel error taxonomy. Then, we create MMLU-Redux, which is a subset of 3,000 manually re-annotated questions across 30 MMLU subjects. Using MMLU-Redux, we demonstrate significant discrepancies with the model performance metrics that were originally reported. Our results strongly advocate for revising MMLU's error-ridden questions to enhance its future utility and reliability as a benchmark. Therefore, we open up MMLU-Redux for additional annotation https://huggingface.co/datasets/edinburgh-dawg/mmlu-redux.
REFER: An End-to-end Rationale Extraction Framework for Explanation Regularization
Oct 22, 2023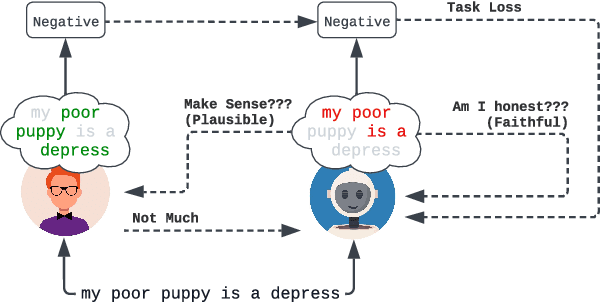
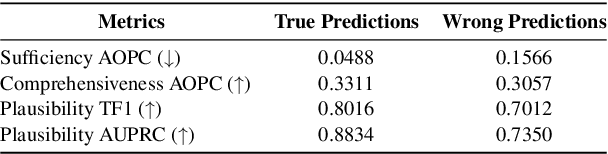
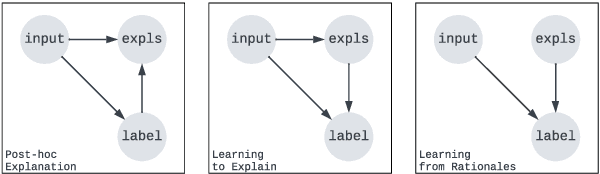
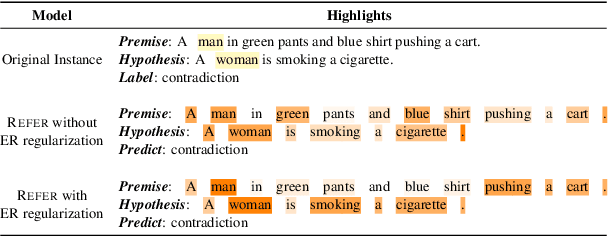
Human-annotated textual explanations are becoming increasingly important in Explainable Natural Language Processing. Rationale extraction aims to provide faithful (i.e., reflective of the behavior of the model) and plausible (i.e., convincing to humans) explanations by highlighting the inputs that had the largest impact on the prediction without compromising the performance of the task model. In recent works, the focus of training rationale extractors was primarily on optimizing for plausibility using human highlights, while the task model was trained on jointly optimizing for task predictive accuracy and faithfulness. We propose REFER, a framework that employs a differentiable rationale extractor that allows to back-propagate through the rationale extraction process. We analyze the impact of using human highlights during training by jointly training the task model and the rationale extractor. In our experiments, REFER yields significantly better results in terms of faithfulness, plausibility, and downstream task accuracy on both in-distribution and out-of-distribution data. On both e-SNLI and CoS-E, our best setting produces better results in terms of composite normalized relative gain than the previous baselines by 11% and 3%, respectively.