 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMEnt: A Suite for Analyzing Knowledge in Language Models from Pretraining Data to Representations
Sep 03, 2025

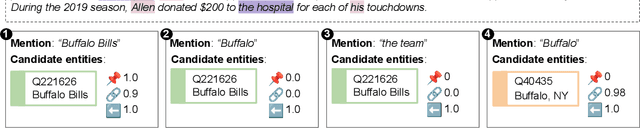
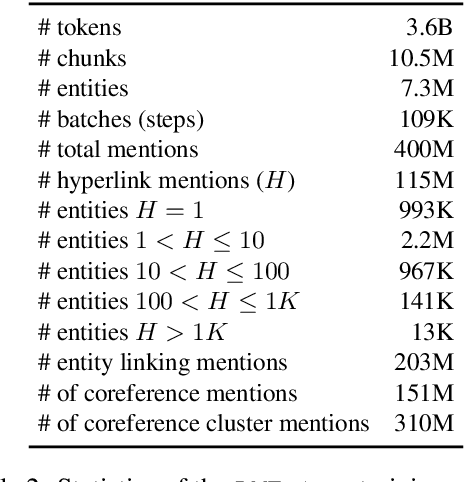
Language models (LMs) increasingly drive real-world applications that require world knowledge. However, the internal processes through which models turn data into representations of knowledge and beliefs about the world, are poorly understood. Insights into these processes could pave the way for developing LMs with knowledge representations that are more consistent, robust, and complete. To facilitate studying these questions, we present LMEnt, a suite for analyzing knowledge acquisition in LMs during pretraining. LMEnt introduces: (1) a knowledge-rich pretraining corpus, fully annotated with entity mentions, based on Wikipedia, (2) an entity-based retrieval method over pretraining data that outperforms previous approaches by as much as 80.4%, and (3) 12 pretrained models with up to 1B parameters and 4K intermediate checkpoints, with comparable performance to popular open-sourced models on knowledge benchmarks. Together, these resources provide a controlled environment for analyzing connections between entity mentions in pretraining and downstream performance, and the effects of causal interventions in pretraining data. We show the utility of LMEnt by studying knowledge acquisition across checkpoints, finding that fact frequency is key, but does not fully explain learning trends. We release LMEnt to support studies of knowledge in LMs, including knowledge representations, plasticity, editing, attribution, and learning dynamics.
How Well Can Reasoning Models Identify and Recover from Unhelpful Thoughts?
Jun 12, 2025Recent reasoning models show the ability to reflect, backtrack, and self-validate their reasoning, which is crucial in spotting mistakes and arriving at accurate solutions. A natural question that arises is how effectively models can perform such self-reevaluation. We tackle this question by investigating how well reasoning models identify and recover from four types of unhelpful thoughts: uninformative rambling thoughts, thoughts irrelevant to the question, thoughts misdirecting the question as a slightly different question, and thoughts that lead to incorrect answers. We show that models are effective at identifying most unhelpful thoughts but struggle to recover from the same thoughts when these are injected into their thinking process, causing significant performance drops. Models tend to naively continue the line of reasoning of the injected irrelevant thoughts, which showcases that their self-reevaluation abilities are far from a general "meta-cognitive" awareness. Moreover, we observe non/inverse-scaling trends, where larger models struggle more than smaller ones to recover from short irrelevant thoughts, even when instructed to reevaluate their reasoning. We demonstrate the implications of these findings with a jailbreak experiment using irrelevant thought injection, showing that the smallest models are the least distracted by harmful-response-triggering thoughts. Overall, our findings call for improvement in self-reevaluation of reasoning models to develop better reasoning and safer systems.
Performance Gap in Entity Knowledge Extraction Across Modalities in Vision Language Models
Dec 18, 2024



Vision-language models (VLMs) excel at extracting and reasoning about information from images. Yet, their capacity to leverage internal knowledge about specific entities remains underexplored. This work investigates the disparity in model performance when answering factual questions about an entity described in text versus depicted in an image. Our results reveal a significant accuracy drop --averaging 19%-- when the entity is presented visually instead of textually. We hypothesize that this decline arises from limitations in how information flows from image tokens to query tokens. We use mechanistic interpretability tools to reveal that, although image tokens are preprocessed by the vision encoder, meaningful information flow from these tokens occurs only in the much deeper layers. Furthermore, critical image processing happens in the language model's middle layers, allowing few layers for consecutive reasoning, highlighting a potential inefficiency in how the model utilizes its layers for reasoning. These insights shed light on the internal mechanics of VLMs and offer pathways for enhancing their reasoning capabilities.
Eliciting Textual Descriptions from Representations of Continuous Prompts
Oct 15, 2024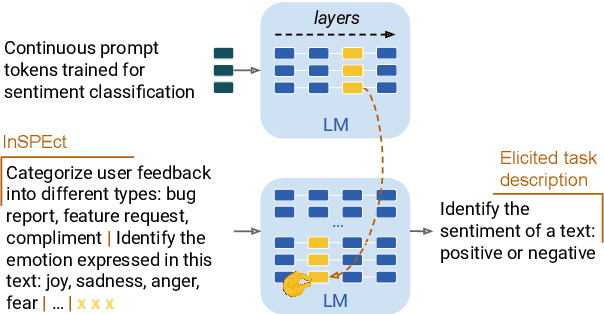

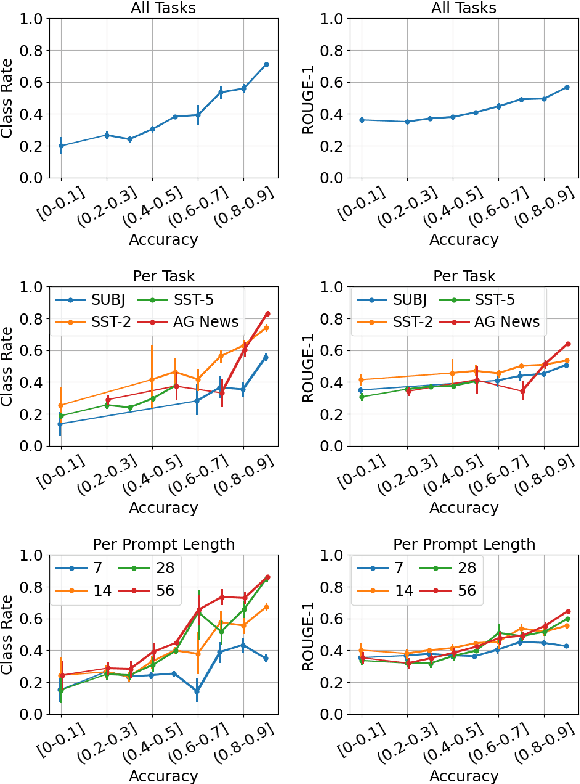
Continuous prompts, or "soft prompts", are a widely-adopted parameter-efficient tuning strategy for large language models, but are often less favorable due to their opaque nature. Prior attempts to interpret continuous prompts relied on projecting individual prompt tokens onto the vocabulary space. However, this approach is problematic as performant prompts can yield arbitrary or contradictory text, and it interprets prompt tokens individually. In this work, we propose a new approach to interpret continuous prompts that elicits textual descriptions from their representations during model inference. Using a Patchscopes variant (Ghandeharioun et al., 2024) called InSPEcT over various tasks, we show our method often yields accurate task descriptions which become more faithful as task performance increases. Moreover, an elaborated version of InSPEcT reveals biased features in continuous prompts, whose presence correlates with biased model predictions. Providing an effective interpretability solution, InSPEcT can be leveraged to debug unwanted properties in continuous prompts and inform developers on ways to mitigate them.
Hopping Too Late: Exploring the Limitations of Large Language Models on Multi-Hop Queries
Jun 18, 2024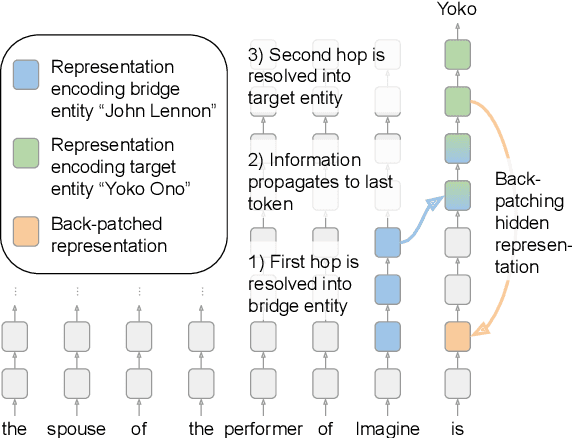



Large language models (LLMs) can solve complex multi-step problems, but little is known about how these computations are implemented internally. Motivated by this, we study how LLMs answer multi-hop queries such as "The spouse of the performer of Imagine is". These queries require two information extraction steps: a latent one for resolving the first hop ("the performer of Imagine") into the bridge entity (John Lennon), and one for resolving the second hop ("the spouse of John Lennon") into the target entity (Yoko Ono). Understanding how the latent step is computed internally is key to understanding the overall computation. By carefully analyzing the internal computations of transformer-based LLMs, we discover that the bridge entity is resolved in the early layers of the model. Then, only after this resolution, the two-hop query is solved in the later layers. Because the second hop commences in later layers, there could be cases where these layers no longer encode the necessary knowledge for correctly predicting the answer. Motivated by this, we propose a novel "back-patching" analysis method whereby a hidden representation from a later layer is patched back to an earlier layer. We find that in up to 57% of previously incorrect cases there exists a back-patch that results in the correct generation of the answer, showing that the later layers indeed sometimes lack the needed functionality. Overall our methods and findings open further opportunities for understanding and improving latent reasoning in transformer-based LLMs.
Estimating Knowledge in Large Language Models Without Generating a Single Token
Jun 18, 2024



To evaluate knowledge in large language models (LLMs), current methods query the model and then evaluate its generated responses. In this work, we ask whether evaluation can be done $\textit{before}$ the model has generated any text. Concretely, is it possible to estimate how knowledgeable a model is about a certain entity, only from its internal computation? We study this question with two tasks: given a subject entity, the goal is to predict (a) the ability of the model to answer common questions about the entity, and (b) the factuality of responses generated by the model about the entity. Experiments with a variety of LLMs show that KEEN, a simple probe trained over internal subject representations, succeeds at both tasks - strongly correlating with both the QA accuracy of the model per-subject and FActScore, a recent factuality metric in open-ended generation. Moreover, KEEN naturally aligns with the model's hedging behavior and faithfully reflects changes in the model's knowledge after fine-tuning. Lastly, we show a more interpretable yet equally performant variant of KEEN, which highlights a small set of tokens that correlates with the model's lack of knowledge. Being simple and lightweight, KEEN can be leveraged to identify gaps and clusters of entity knowledge in LLMs, and guide decisions such as augmenting queries with retrieval.