 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMEnt: A Suite for Analyzing Knowledge in Language Models from Pretraining Data to Representations
Sep 03, 2025Language models (LMs) increasingly drive real-world applications that require world knowledge. However, the internal processes through which models turn data into representations of knowledge and beliefs about the world, are poorly understood. Insights into these processes could pave the way for developing LMs with knowledge representations that are more consistent, robust, and complete. To facilitate studying these questions, we present LMEnt, a suite for analyzing knowledge acquisition in LMs during pretraining. LMEnt introduces: (1) a knowledge-rich pretraining corpus, fully annotated with entity mentions, based on Wikipedia, (2) an entity-based retrieval method over pretraining data that outperforms previous approaches by as much as 80.4%, and (3) 12 pretrained models with up to 1B parameters and 4K intermediate checkpoints, with comparable performance to popular open-sourced models on knowledge benchmarks. Together, these resources provide a controlled environment for analyzing connections between entity mentions in pretraining and downstream performance, and the effects of causal interventions in pretraining data. We show the utility of LMEnt by studying knowledge acquisition across checkpoints, finding that fact frequency is key, but does not fully explain learning trends. We release LMEnt to support studies of knowledge in LMs, including knowledge representations, plasticity, editing, attribution, and learning dynamics.
Measuring the Data
Apr 02, 2025
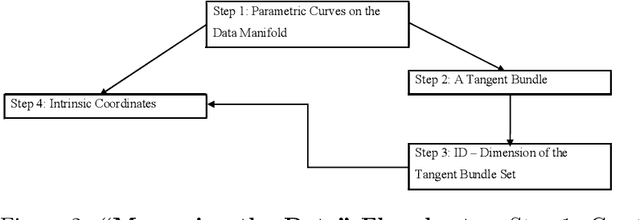


Measuring the Data analytically finds the intrinsic manifold in big data. First, Optimal Transport generates the tangent space at each data point from which the intrinsic dimension is revealed. Then, the Koopman Dimensionality Reduction procedure derives a nonlinear transformation from the data to the intrinsic manifold. Measuring the data procedure is presented here, backed up with encouraging results.
Performance Gap in Entity Knowledge Extraction Across Modalities in Vision Language Models
Dec 18, 2024



Vision-language models (VLMs) excel at extracting and reasoning about information from images. Yet, their capacity to leverage internal knowledge about specific entities remains underexplored. This work investigates the disparity in model performance when answering factual questions about an entity described in text versus depicted in an image. Our results reveal a significant accuracy drop --averaging 19%-- when the entity is presented visually instead of textually. We hypothesize that this decline arises from limitations in how information flows from image tokens to query tokens. We use mechanistic interpretability tools to reveal that, although image tokens are preprocessed by the vision encoder, meaningful information flow from these tokens occurs only in the much deeper layers. Furthermore, critical image processing happens in the language model's middle layers, allowing few layers for consecutive reasoning, highlighting a potential inefficiency in how the model utilizes its layers for reasoning. These insights shed light on the internal mechanics of VLMs and offer pathways for enhancing their reasoning capabilities.
MenakBERT -- Hebrew Diacriticizer
Oct 03, 2024



Diacritical marks in the Hebrew language give words their vocalized form. The task of adding diacritical marks to plain Hebrew text is still dominated by a system that relies heavily on human-curated resources. Recent models trained on diacritized Hebrew texts still present a gap in performance. We use a recently developed char-based PLM to narrowly bridge this gap. Presenting MenakBERT, a character level transformer pretrained on Hebrew text and fine-tuned to produce diacritical marks for Hebrew sentences. We continue to show how finetuning a model for diacritizing transfers to a task such as part of speech tagging.
Delay as Payoff in MAB
Aug 27, 2024

In this paper, we investigate a variant of the classical stochastic Multi-armed Bandit (MAB) problem, where the payoff received by an agent (either cost or reward) is both delayed, and directly corresponds to the magnitude of the delay. This setting models faithfully many real world scenarios such as the time it takes for a data packet to traverse a network given a choice of route (where delay serves as the agent's cost); or a user's time spent on a web page given a choice of content (where delay serves as the agent's reward). Our main contributions are tight upper and lower bounds for both the cost and reward settings. For the case that delays serve as costs, which we are the first to consider, we prove optimal regret that scales as $\sum_{i:\Delta_i > 0}\frac{\log T}{\Delta_i} + d^*$, where $T$ is the maximal number of steps, $\Delta_i$ are the sub-optimality gaps and $d^*$ is the minimal expected delay amongst arms. For the case that delays serves as rewards, we show optimal regret of $\sum_{i:\Delta_i > 0}\frac{\log T}{\Delta_i} + \bar{d}$, where $\bar d$ is the second maximal expected delay. These improve over the regret in the general delay-dependent payoff setting, which scales as $\sum_{i:\Delta_i > 0}\frac{\log T}{\Delta_i} + D$, where $D$ is the maximum possible delay. Our regret bounds highlight the difference between the cost and reward scenarios, showing that the improvement in the cost scenario is more significant than for the reward. Finally, we accompany our theoretical results with an empirical evaluation.
Enhancing Neural Training via a Correlated Dynamics Model
Dec 20, 2023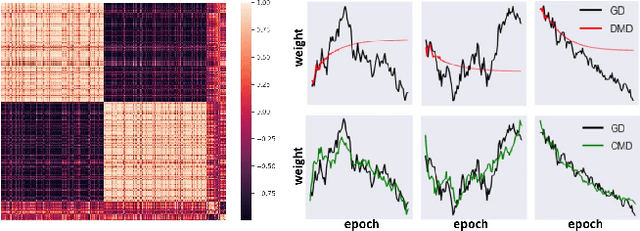
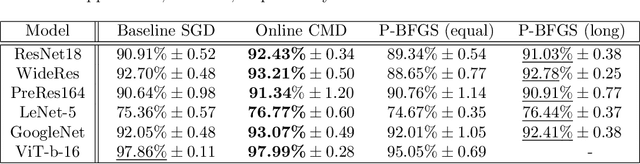


As neural networks grow in scale, their training becomes both computationally demanding and rich in dynamics. Amidst the flourishing interest in these training dynamics, we present a novel observation: Parameters during training exhibit intrinsic correlations over time. Capitalizing on this, we introduce Correlation Mode Decomposition (CMD). This algorithm clusters the parameter space into groups, termed modes, that display synchronized behavior across epochs. This enables CMD to efficiently represent the training dynamics of complex networks, like ResNets and Transformers, using only a few modes. Moreover, test set generalization is enhanced. We introduce an efficient CMD variant, designed to run concurrently with training. Our experiments indicate that CMD surpasses the state-of-the-art method for compactly modeled dynamics on image classification. Our modeling can improve training efficiency and lower communication overhead, as shown by our preliminary experiments in the context of federated learning.
The Underlying Correlated Dynamics in Neural Training
Dec 18, 2022
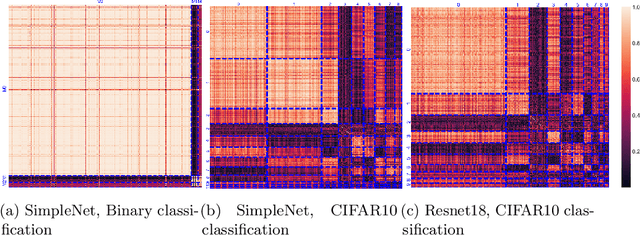
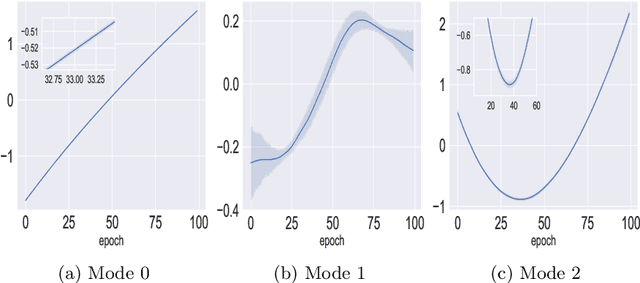

Training of neural networks is a computationally intensive task. The significance of understanding and modeling the training dynamics is growing as increasingly larger networks are being trained. We propose in this work a model based on the correlation of the parameters' dynamics, which dramatically reduces the dimensionality. We refer to our algorithm as \emph{correlation mode decomposition} (CMD). It splits the parameter space into groups of parameters (modes) which behave in a highly correlated manner through the epochs. We achieve a remarkable dimensionality reduction with this approach, where networks like ResNet-18, transformers and GANs, containing millions of parameters, can be modeled well using just a few modes. We observe each typical time profile of a mode is spread throughout the network in all layers. Moreover, our model induces regularization which yields better generalization capacity on the test set. This representation enhances the understanding of the underlying training dynamics and can pave the way for designing better acceleration techniques.
BASiS: Batch Aligned Spectral Embedding Space
Nov 30, 2022


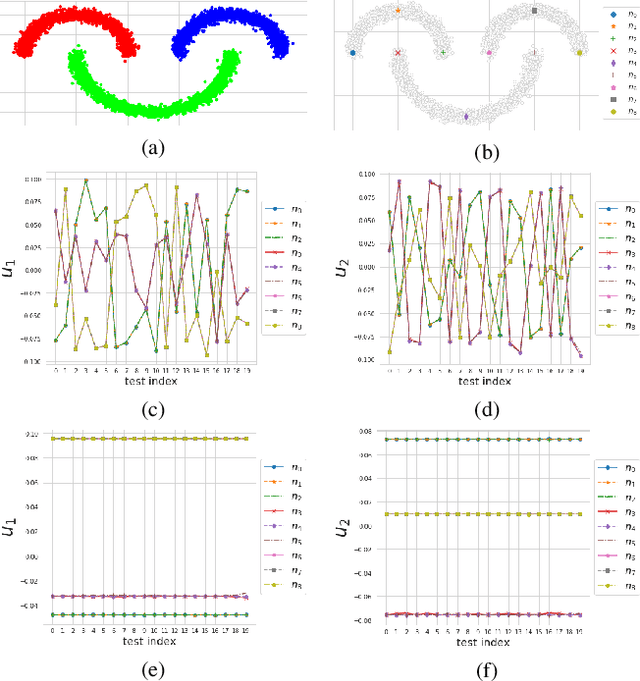
Graph is a highly generic and diverse representation, suitable for almost any data processing problem. Spectral graph theory has been shown to provide powerful algorithms, backed by solid linear algebra theory. It thus can be extremely instrumental to design deep network building blocks with spectral graph characteristics. For instance, such a network allows the design of optimal graphs for certain tasks or obtaining a canonical orthogonal low-dimensional embedding of the data. Recent attempts to solve this problem were based on minimizing Rayleigh-quotient type losses. We propose a different approach of directly learning the eigensapce. A severe problem of the direct approach, applied in batch-learning, is the inconsistent mapping of features to eigenspace coordinates in different batches. We analyze the degrees of freedom of learning this task using batches and propose a stable alignment mechanism that can work both with batch changes and with graph-metric changes. We show that our learnt spectral embedding is better in terms of NMI, ACC, Grassman distance, orthogonality and classification accuracy, compared to SOTA. In addition, the learning is more stable.
Understanding Transformer Memorization Recall Through Idioms
Oct 11, 2022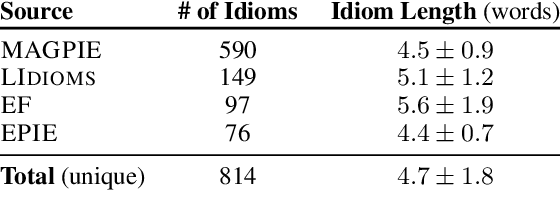
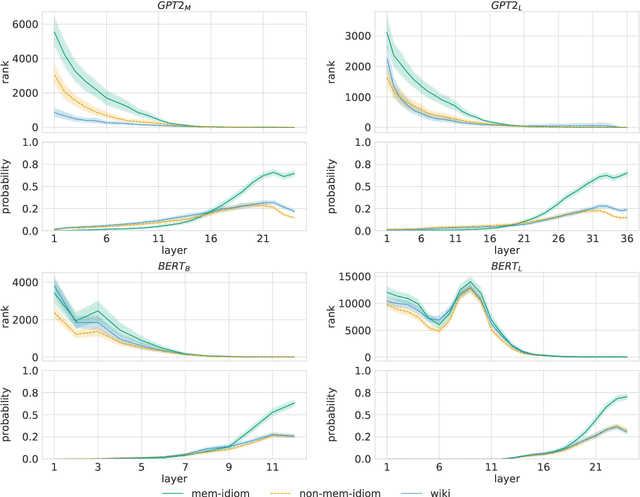
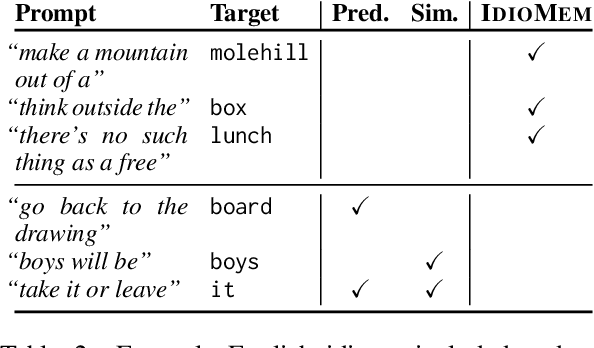
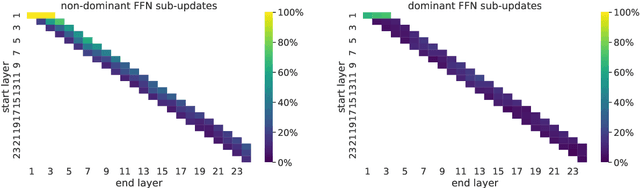
To produce accurate predictions, language models (LMs) must balance between generalization and memorization. Yet, little is known about the mechanism by which transformer LMs employ their memorization capacity. When does a model decide to output a memorized phrase, and how is this phrase then retrieved from memory? In this work, we offer the first methodological framework for probing and characterizing recall of memorized sequences in transformer LMs. First, we lay out criteria for detecting model inputs that trigger memory recall, and propose idioms as inputs that fulfill these criteria. Next, we construct a dataset of English idioms and use it to compare model behavior on memorized vs. non-memorized inputs. Specifically, we analyze the internal prediction construction process by interpreting the model's hidden representations as a gradual refinement of the output probability distribution. We find that across different model sizes and architectures, memorized predictions are a two-step process: early layers promote the predicted token to the top of the output distribution, and upper layers increase model confidence. This suggests that memorized information is stored and retrieved in the early layers of the network. Last, we demonstrate the utility of our methodology beyond idioms in memorized factual statements. Overall, our work makes a first step towards understanding memory recall, and provides a methodological basis for future studies of transformer memorization.
Unsupervised Detection of Sub-Territories of the Subthalamic Nucleus During DBS Surgery with Manifold Learning
Aug 23, 2022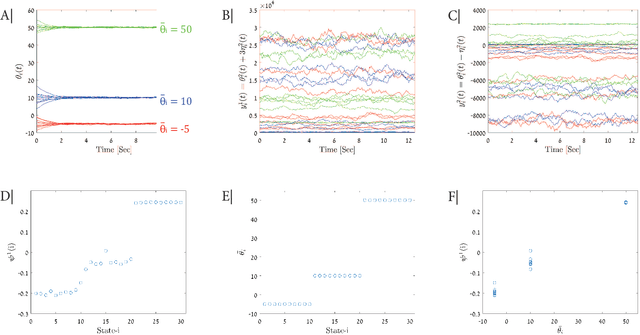
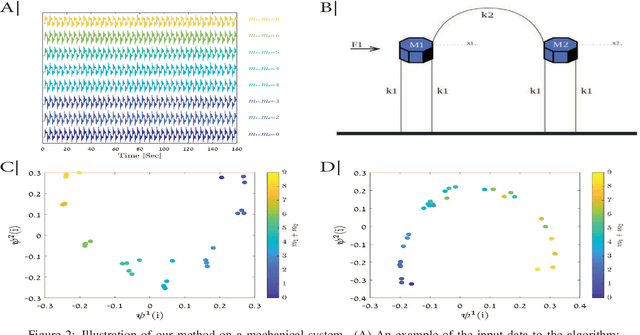

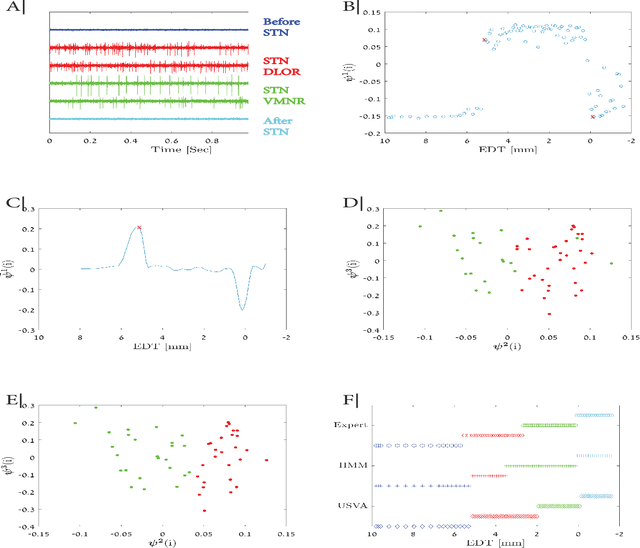
During Deep Brain Stimulation(DBS) surgery for treating Parkinson's disease, one vital task is to detect a specific brain area called the Subthalamic Nucleus(STN) and a sub-territory within the STN called the Dorsolateral Oscillatory Region(DLOR). Accurate detection of the STN borders is crucial for adequate clinical outcomes. Currently, the detection is based on human experts, guided by supervised machine learning detection algorithms. Consequently, this procedure depends on the knowledge and experience of particular experts and on the amount and quality of the labeled data used for training the machine learning algorithms. In this paper, to circumvent the dependence and bias caused by the training data, we present a data-driven unsupervised method for detecting the STN and the DLOR during DBS surgery. Our method is based on an agnostic modeling approach for general target detection tasks. Given a set of measurements, we extract features and propose a variant of the Mahalanobis distance between these features. We show theoretically that this distance enhances the differences between measurements with different intrinsic characteristics. Then, we incorporate the new features and distances into a manifold learning method, called Diffusion Maps. We show that this method gives rise to a representation that is consistent with the underlying factors that govern the measurements. Since the construction of this representation is carried out without rigid modeling assumptions, it can facilitate a wide range of detection tasks; here, we propose a specification for the STN and DLOR detection tasks. We present detection results on 25 sets of measurements recorded from 16 patients during surgery. Compared to a competing supervised algorithm based on a Hidden Markov Model, our unsupervised method demonstrates similar results in the STN detection task and superior results in the DLOR detection task.