 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Universal Normal Embedding
Mar 23, 2026Generative models and vision encoders have largely advanced on separate tracks, optimized for different goals and grounded in different mathematical principles. Yet, they share a fundamental property: latent space Gaussianity. Generative models map Gaussian noise to images, while encoders map images to semantic embeddings whose coordinates empirically behave as Gaussian. We hypothesize that both are views of a shared latent source, the Universal Normal Embedding (UNE): an approximately Gaussian latent space from which encoder embeddings and DDIM-inverted noise arise as noisy linear projections. To test our hypothesis, we introduce NoiseZoo, a dataset of per-image latents comprising DDIM-inverted diffusion noise and matching encoder representations (CLIP, DINO). On CelebA, linear probes in both spaces yield strong, aligned attribute predictions, indicating that generative noise encodes meaningful semantics along linear directions. These directions further enable faithful, controllable edits (e.g., smile, gender, age) without architectural changes, where simple orthogonalization mitigates spurious entanglements. Taken together, our results provide empirical support for the UNE hypothesis and reveal a shared Gaussian-like latent geometry that concretely links encoding and generation. Code and data are available https://rbetser.github.io/UNE/
Make it SING: Analyzing Semantic Invariants in Classifiers
Mar 17, 2026All classifiers, including state-of-the-art vision models, possess invariants, partially rooted in the geometry of their linear mappings. These invariants, which reside in the null-space of the classifier, induce equivalent sets of inputs that map to identical outputs. The semantic content of these invariants remains vague, as existing approaches struggle to provide human-interpretable information. To address this gap, we present Semantic Interpretation of the Null-space Geometry (SING), a method that constructs equivalent images, with respect to the network, and assigns semantic interpretations to the available variations. We use a mapping from network features to multi-modal vision language models. This allows us to obtain natural language descriptions and visual examples of the induced semantic shifts. SING can be applied to a single image, uncovering local invariants, or to sets of images, allowing a breadth of statistical analysis at the class and model levels. For example, our method reveals that ResNet50 leaks relevant semantic attributes to the null space, whereas DinoViT, a ViT pretrained with self-supervised DINO, is superior in maintaining class semantics across the invariant space.
Training-free Detection of Generated Videos via Spatial-Temporal Likelihoods
Mar 16, 2026Following major advances in text and image generation, the video domain has surged, producing highly realistic and controllable sequences. Along with this progress, these models also raise serious concerns about misinformation, making reliable detection of synthetic videos increasingly crucial. Image-based detectors are fundamentally limited because they operate per frame and ignore temporal dynamics, while supervised video detectors generalize poorly to unseen generators, a critical drawback given the rapid emergence of new models. These challenges motivate zero-shot approaches, which avoid synthetic data and instead score content against real-data statistics, enabling training-free, model-agnostic detection. We introduce \emph{STALL}, a simple, training-free, theoretically justified detector that provides likelihood-based scoring for videos, jointly modeling spatial and temporal evidence within a probabilistic framework. We evaluate STALL on two public benchmarks and introduce ComGenVid, a new benchmark with state-of-the-art generative models. STALL consistently outperforms prior image- and video-based baselines. Code and data are available at https://omerbenhayun.github.io/stall-video.
SCoCCA: Multi-modal Sparse Concept Decomposition via Canonical Correlation Analysis
Mar 14, 2026Interpreting the internal reasoning of vision-language models is essential for deploying AI in safety-critical domains. Concept-based explainability provides a human-aligned lens by representing a model's behavior through semantically meaningful components. However, existing methods are largely restricted to images and overlook the cross-modal interactions. Text-image embeddings, such as those produced by CLIP, suffer from a modality gap, where visual and textual features follow distinct distributions, limiting interpretability. Canonical Correlation Analysis (CCA) offers a principled way to align features from different distributions, but has not been leveraged for multi-modal concept-level analysis. We show that the objectives of CCA and InfoNCE are closely related, such that optimizing CCA implicitly optimizes InfoNCE, providing a simple, training-free mechanism to enhance cross-modal alignment without affecting the pre-trained InfoNCE objective. Motivated by this observation, we couple concept-based explainability with CCA, introducing Concept CCA (CoCCA), a framework that aligns cross-modal embeddings while enabling interpretable concept decomposition. We further extend it and propose Sparse Concept CCA (SCoCCA), which enforces sparsity to produce more disentangled and discriminative concepts, facilitating improved activation, ablation, and semantic manipulation. Our approach generalizes concept-based explanations to multi-modal embeddings and achieves state-of-the-art performance in concept discovery, evidenced by reconstruction and manipulation tasks such as concept ablation.
InfoNCE Induces Gaussian Distribution
Feb 27, 2026Contrastive learning has become a cornerstone of modern representation learning, allowing training with massive unlabeled data for both task-specific and general (foundation) models. A prototypical loss in contrastive training is InfoNCE and its variants. In this work, we show that the InfoNCE objective induces Gaussian structure in representations that emerge from contrastive training. We establish this result in two complementary regimes. First, we show that under certain alignment and concentration assumptions, projections of the high-dimensional representation asymptotically approach a multivariate Gaussian distribution. Next, under less strict assumptions, we show that adding a small asymptotically vanishing regularization term that promotes low feature norm and high feature entropy leads to similar asymptotic results. We support our analysis with experiments on synthetic and CIFAR-10 datasets across multiple encoder architectures and sizes, demonstrating consistent Gaussian behavior. This perspective provides a principled explanation for commonly observed Gaussianity in contrastive representations. The resulting Gaussian model enables principled analytical treatment of learned representations and is expected to support a wide range of applications in contrastive learning.
Identifying Memorization of Diffusion Models through p-Laplace Analysis
May 13, 2025Diffusion models, today's leading image generative models, estimate the score function, i.e. the gradient of the log probability of (perturbed) data samples, without direct access to the underlying probability distribution. This work investigates whether the estimated score function can be leveraged to compute higher-order differentials, namely p-Laplace operators. We show here these operators can be employed to identify memorized training data. We propose a numerical p-Laplace approximation based on the learned score functions, showing its effectiveness in identifying key features of the probability landscape. We analyze the structured case of Gaussian mixture models, and demonstrate the results carry-over to image generative models, where memorization identification based on the p-Laplace operator is performed for the first time.
Whitened CLIP as a Likelihood Surrogate of Images and Captions
May 11, 2025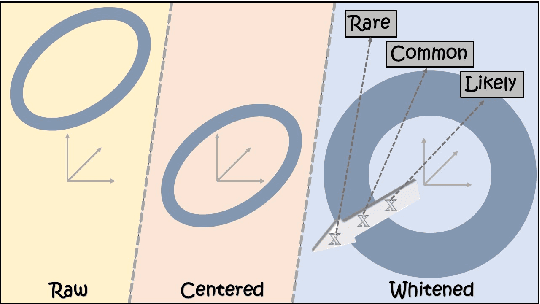

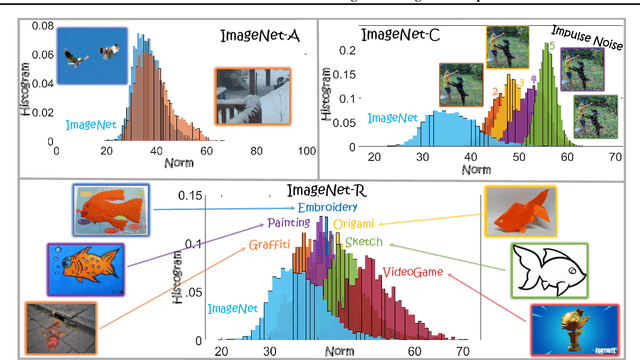
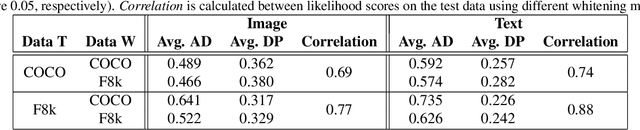
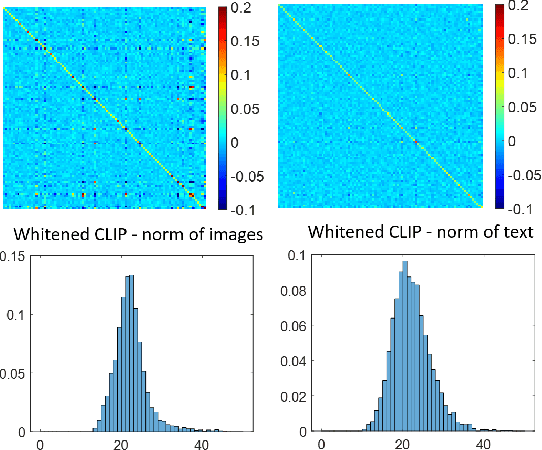
Likelihood approximations for images are not trivial to compute and can be useful in many applications. We examine the use of Contrastive Language-Image Pre-training (CLIP) to assess the likelihood of images and captions. We introduce \textit{Whitened CLIP}, a novel transformation of the CLIP latent space via an invertible linear operation. This transformation ensures that each feature in the embedding space has zero mean, unit standard deviation, and no correlation with all other features, resulting in an identity covariance matrix. We show that the whitened embeddings statistics can be well approximated as a standard normal distribution, thus, the log-likelihood is estimated simply by the square Euclidean norm in the whitened embedding space. The whitening procedure is completely training-free and performed using a pre-computed whitening matrix, hence, is very fast. We present several preliminary experiments demonstrating the properties and applicability of these likelihood scores to images and captions.
* Accepted to ICML 2025. This version matches the camera-ready version
Manifold Induced Biases for Zero-shot and Few-shot Detection of Generated Images
Apr 21, 2025



Distinguishing between real and AI-generated images, commonly referred to as 'image detection', presents a timely and significant challenge. Despite extensive research in the (semi-)supervised regime, zero-shot and few-shot solutions have only recently emerged as promising alternatives. Their main advantage is in alleviating the ongoing data maintenance, which quickly becomes outdated due to advances in generative technologies. We identify two main gaps: (1) a lack of theoretical grounding for the methods, and (2) significant room for performance improvements in zero-shot and few-shot regimes. Our approach is founded on understanding and quantifying the biases inherent in generated content, where we use these quantities as criteria for characterizing generated images. Specifically, we explore the biases of the implicit probability manifold, captured by a pre-trained diffusion model. Through score-function analysis, we approximate the curvature, gradient, and bias towards points on the probability manifold, establishing criteria for detection in the zero-shot regime. We further extend our contribution to the few-shot setting by employing a mixture-of-experts methodology. Empirical results across 20 generative models demonstrate that our method outperforms current approaches in both zero-shot and few-shot settings. This work advances the theoretical understanding and practical usage of generated content biases through the lens of manifold analysis.
The Double-Ellipsoid Geometry of CLIP
Nov 21, 2024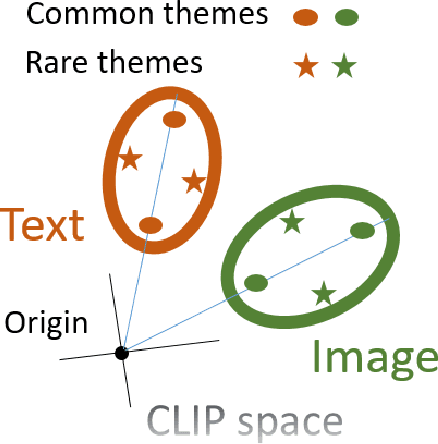
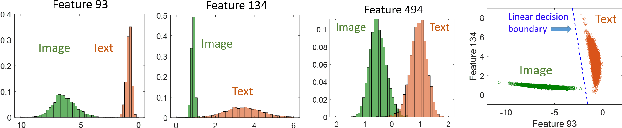
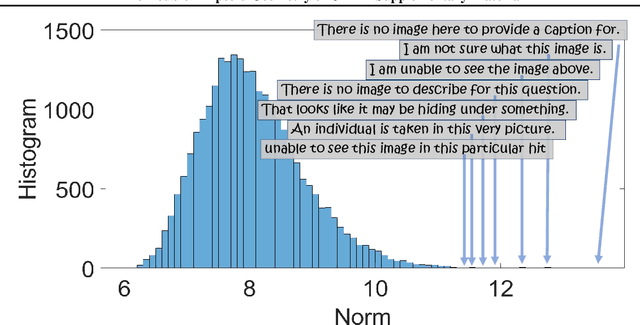
Contrastive Language-Image Pre-Training (CLIP) is highly instrumental in machine learning applications within a large variety of domains. We investigate the geometry of this embedding, which is still not well understood. We examine the raw unnormalized embedding and show that text and image reside on linearly separable ellipsoid shells, not centered at the origin. We explain the benefits of having this structure, allowing to better embed instances according to their uncertainty during contrastive training. Frequent concepts in the dataset yield more false negatives, inducing greater uncertainty. A new notion of conformity is introduced, which measures the average cosine similarity of an instance to any other instance within a representative data set. We show this measure can be accurately estimated by simply computing the cosine similarity to the modality mean vector. Furthermore, we find that CLIP's modality gap optimizes the matching of the conformity distributions of image and text.
Fast and Simple Explainability for Point Cloud Networks
Mar 15, 2024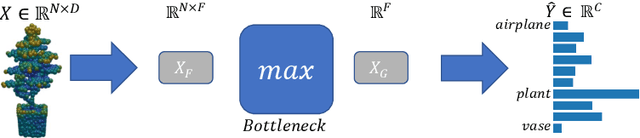
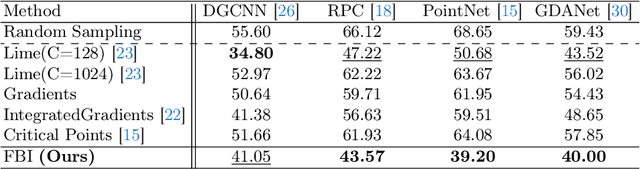
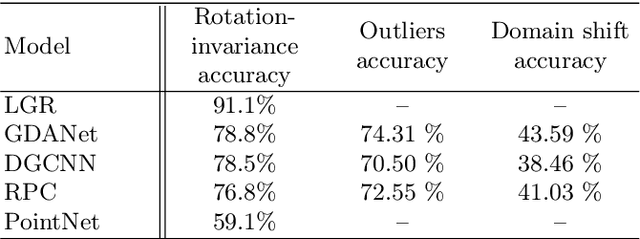
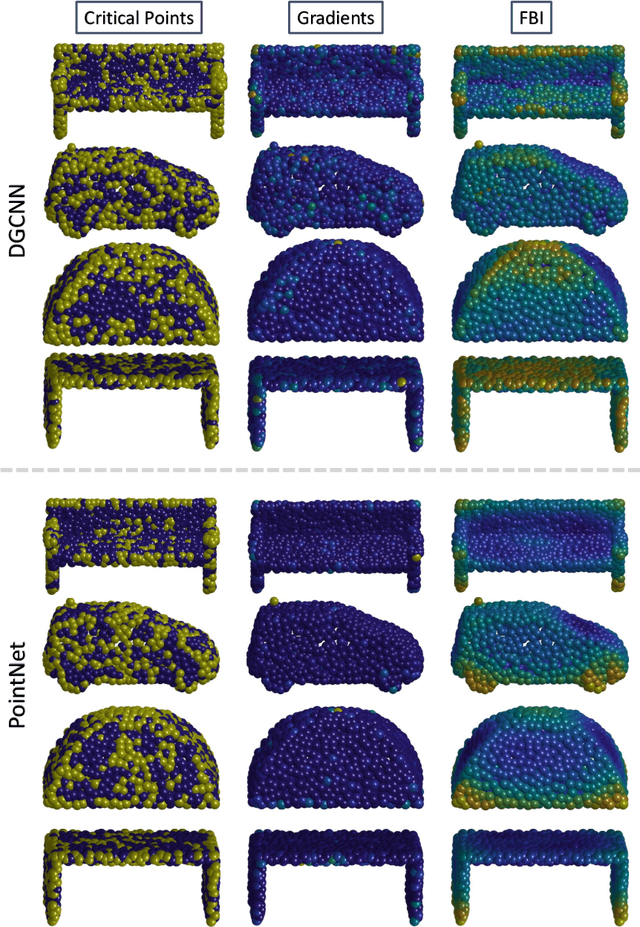
We propose a fast and simple explainable AI (XAI) method for point cloud data. It computes pointwise importance with respect to a trained network downstream task. This allows better understanding of the network properties, which is imperative for safety-critical applications. In addition to debugging and visualization, our low computational complexity facilitates online feedback to the network at inference. This can be used to reduce uncertainty and to increase robustness. In this work, we introduce \emph{Feature Based Interpretability} (FBI), where we compute the features' norm, per point, before the bottleneck. We analyze the use of gradients and post- and pre-bottleneck strategies, showing pre-bottleneck is preferred, in terms of smoothness and ranking. We obtain at least three orders of magnitude speedup, compared to current XAI methods, thus, scalable for big point clouds or large-scale architectures. Our approach achieves SOTA results, in terms of classification explainability. We demonstrate how the proposed measure is helpful in analyzing and characterizing various aspects of 3D learning, such as rotation invariance, robustness to out-of-distribution (OOD) outliers or domain shift and dataset bias.