 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgenTRIM: Tool Risk Mitigation for Agentic AI
Jan 18, 2026AI agents are autonomous systems that combine LLMs with external tools to solve complex tasks. While such tools extend capability, improper tool permissions introduce security risks such as indirect prompt injection and tool misuse. We characterize these failures as unbalanced tool-driven agency. Agents may retain unnecessary permissions (excessive agency) or fail to invoke required tools (insufficient agency), amplifying the attack surface and reducing performance. We introduce AgenTRIM, a framework for detecting and mitigating tool-driven agency risks without altering an agent's internal reasoning. AgenTRIM addresses these risks through complementary offline and online phases. Offline, AgenTRIM reconstructs and verifies the agent's tool interface from code and execution traces. At runtime, it enforces per-step least-privilege tool access through adaptive filtering and status-aware validation of tool calls. Evaluating on the AgentDojo benchmark, AgenTRIM substantially reduces attack success while maintaining high task performance. Additional experiments show robustness to description-based attacks and effective enforcement of explicit safety policies. Together, these results demonstrate that AgenTRIM provides a practical, capability-preserving approach to safer tool use in LLM-based agents.
LumiMAS: A Comprehensive Framework for Real-Time Monitoring and Enhanced Observability in Multi-Agent Systems
Aug 17, 2025The incorporation of large language models in multi-agent systems (MASs) has the potential to significantly improve our ability to autonomously solve complex problems. However, such systems introduce unique challenges in monitoring, interpreting, and detecting system failures. Most existing MAS observability frameworks focus on analyzing each individual agent separately, overlooking failures associated with the entire MAS. To bridge this gap, we propose LumiMAS, a novel MAS observability framework that incorporates advanced analytics and monitoring techniques. The proposed framework consists of three key components: a monitoring and logging layer, anomaly detection layer, and anomaly explanation layer. LumiMAS's first layer monitors MAS executions, creating detailed logs of the agents' activity. These logs serve as input to the anomaly detection layer, which detects anomalies across the MAS workflow in real time. Then, the anomaly explanation layer performs classification and root cause analysis (RCA) of the detected anomalies. LumiMAS was evaluated on seven different MAS applications, implemented using two popular MAS platforms, and a diverse set of possible failures. The applications include two novel failure-tailored applications that illustrate the effects of a hallucination or bias on the MAS. The evaluation results demonstrate LumiMAS's effectiveness in failure detection, classification, and RCA.
Identifying Memorization of Diffusion Models through p-Laplace Analysis
May 13, 2025Diffusion models, today's leading image generative models, estimate the score function, i.e. the gradient of the log probability of (perturbed) data samples, without direct access to the underlying probability distribution. This work investigates whether the estimated score function can be leveraged to compute higher-order differentials, namely p-Laplace operators. We show here these operators can be employed to identify memorized training data. We propose a numerical p-Laplace approximation based on the learned score functions, showing its effectiveness in identifying key features of the probability landscape. We analyze the structured case of Gaussian mixture models, and demonstrate the results carry-over to image generative models, where memorization identification based on the p-Laplace operator is performed for the first time.
Manifold Induced Biases for Zero-shot and Few-shot Detection of Generated Images
Apr 21, 2025



Distinguishing between real and AI-generated images, commonly referred to as 'image detection', presents a timely and significant challenge. Despite extensive research in the (semi-)supervised regime, zero-shot and few-shot solutions have only recently emerged as promising alternatives. Their main advantage is in alleviating the ongoing data maintenance, which quickly becomes outdated due to advances in generative technologies. We identify two main gaps: (1) a lack of theoretical grounding for the methods, and (2) significant room for performance improvements in zero-shot and few-shot regimes. Our approach is founded on understanding and quantifying the biases inherent in generated content, where we use these quantities as criteria for characterizing generated images. Specifically, we explore the biases of the implicit probability manifold, captured by a pre-trained diffusion model. Through score-function analysis, we approximate the curvature, gradient, and bias towards points on the probability manifold, establishing criteria for detection in the zero-shot regime. We further extend our contribution to the few-shot setting by employing a mixture-of-experts methodology. Empirical results across 20 generative models demonstrate that our method outperforms current approaches in both zero-shot and few-shot settings. This work advances the theoretical understanding and practical usage of generated content biases through the lens of manifold analysis.
Addressing Key Challenges of Adversarial Attacks and Defenses in the Tabular Domain: A Methodological Framework for Coherence and Consistency
Dec 10, 2024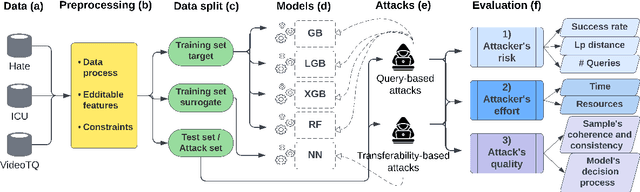



Machine learning models trained on tabular data are vulnerable to adversarial attacks, even in realistic scenarios where attackers have access only to the model's outputs. Researchers evaluate such attacks by considering metrics like success rate, perturbation magnitude, and query count. However, unlike other data domains, the tabular domain contains complex interdependencies among features, presenting a unique aspect that should be evaluated: the need for the attack to generate coherent samples and ensure feature consistency for indistinguishability. Currently, there is no established methodology for evaluating adversarial samples based on these criteria. In this paper, we address this gap by proposing new evaluation criteria tailored for tabular attacks' quality; we defined anomaly-based framework to assess the distinguishability of adversarial samples and utilize the SHAP explainability technique to identify inconsistencies in the model's decision-making process caused by adversarial samples. These criteria could form the basis for potential detection methods and be integrated into established evaluation metrics for assessing attack's quality Additionally, we introduce a novel technique for perturbing dependent features while maintaining coherence and feature consistency within the sample. We compare different attacks' strategies, examining black-box query-based attacks and transferability-based gradient attacks across four target models. Our experiments, conducted on benchmark tabular datasets, reveal significant differences between the examined attacks' strategies in terms of the attacker's risk and effort and the attacks' quality. The findings provide valuable insights on the strengths, limitations, and trade-offs of various adversarial attacks in the tabular domain, laying a foundation for future research on attacks and defense development.
Insights and Current Gaps in Open-Source LLM Vulnerability Scanners: A Comparative Analysis
Oct 21, 2024



This report presents a comparative analysis of open-source vulnerability scanners for conversational large language models (LLMs). As LLMs become integral to various applications, they also present potential attack surfaces, exposed to security risks such as information leakage and jailbreak attacks. Our study evaluates prominent scanners - Garak, Giskard, PyRIT, and CyberSecEval - that adapt red-teaming practices to expose these vulnerabilities. We detail the distinctive features and practical use of these scanners, outline unifying principles of their design and perform quantitative evaluations to compare them. These evaluations uncover significant reliability issues in detecting successful attacks, highlighting a fundamental gap for future development. Additionally, we contribute a preliminary labelled dataset, which serves as an initial step to bridge this gap. Based on the above, we provide strategic recommendations to assist organizations choose the most suitable scanner for their red-teaming needs, accounting for customizability, test suite comprehensiveness, and industry-specific use cases.
X-Detect: Explainable Adversarial Patch Detection for Object Detectors in Retail
Jul 02, 2023
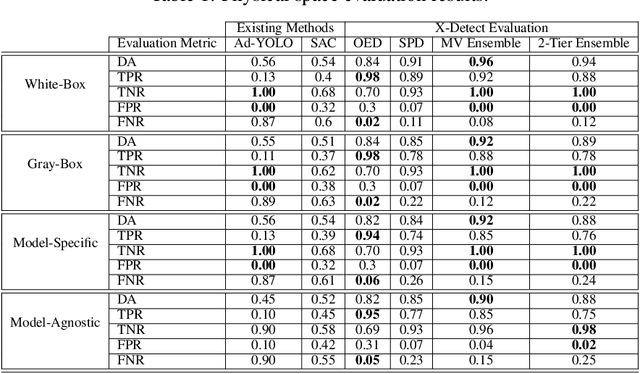


Object detection models, which are widely used in various domains (such as retail), have been shown to be vulnerable to adversarial attacks. Existing methods for detecting adversarial attacks on object detectors have had difficulty detecting new real-life attacks. We present X-Detect, a novel adversarial patch detector that can: i) detect adversarial samples in real time, allowing the defender to take preventive action; ii) provide explanations for the alerts raised to support the defender's decision-making process, and iii) handle unfamiliar threats in the form of new attacks. Given a new scene, X-Detect uses an ensemble of explainable-by-design detectors that utilize object extraction, scene manipulation, and feature transformation techniques to determine whether an alert needs to be raised. X-Detect was evaluated in both the physical and digital space using five different attack scenarios (including adaptive attacks) and the COCO dataset and our new Superstore dataset. The physical evaluation was performed using a smart shopping cart setup in real-world settings and included 17 adversarial patch attacks recorded in 1,700 adversarial videos. The results showed that X-Detect outperforms the state-of-the-art methods in distinguishing between benign and adversarial scenes for all attack scenarios while maintaining a 0% FPR (no false alarms) and providing actionable explanations for the alerts raised. A demo is available.
BENN: Bias Estimation Using Deep Neural Network
Dec 23, 2020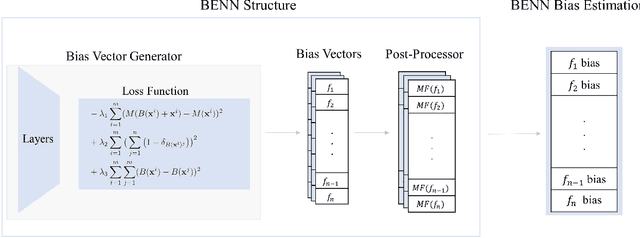

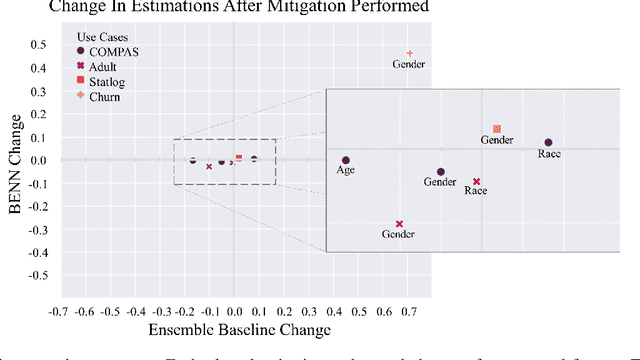
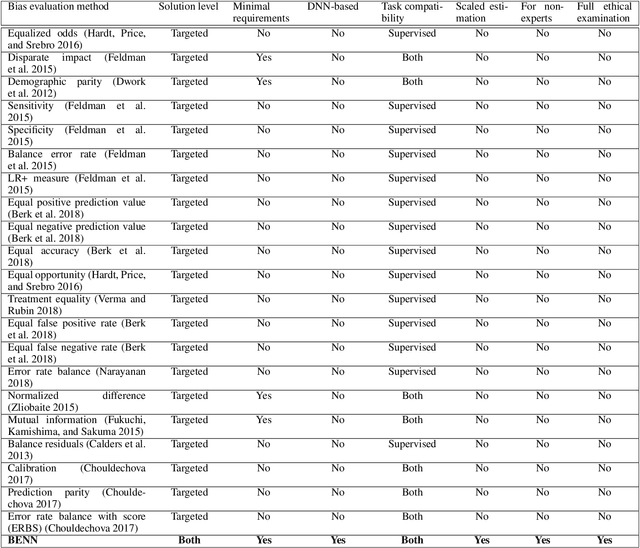
The need to detect bias in machine learning (ML) models has led to the development of multiple bias detection methods, yet utilizing them is challenging since each method: i) explores a different ethical aspect of bias, which may result in contradictory output among the different methods, ii) provides an output of a different range/scale and therefore, can't be compared with other methods, and iii) requires different input, and therefore a human expert needs to be involved to adjust each method according to the examined model. In this paper, we present BENN -- a novel bias estimation method that uses a pretrained unsupervised deep neural network. Given a ML model and data samples, BENN provides a bias estimation for every feature based on the model's predictions. We evaluated BENN using three benchmark datasets and one proprietary churn prediction model used by a European Telco and compared it with an ensemble of 21 existing bias estimation methods. Evaluation results highlight the significant advantages of BENN over the ensemble, as it is generic (i.e., can be applied to any ML model) and there is no need for a domain expert, yet it provides bias estimations that are aligned with those of the ensemble.