 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgemlr3torch: A Deep Learning Framework in R based on mlr3 and torch
Apr 20, 2026Deep learning (DL) has become a cornerstone of modern machine learning (ML) praxis. We introduce the R package mlr3torch, which is an extensible DL framework for the mlr3 ecosystem. It is built upon the torch package, and simplifies the definition, training, and evaluation of neural networks for both tabular data and generic tensors (e.g., images) for classification and regression. The package implements predefined architectures, and torch models can easily be converted to mlr3 learners. It also allows users to define neural networks as graphs. This representation is based on the graph language defined in mlr3pipelines and allows users to define the entire modeling workflow, including preprocessing, data augmentation, and network architecture, in a single graph. Through its integration into the mlr3 ecosystem, the package allows for convenient resampling, benchmarking, preprocessing, and more. We explain the package's design and features and show how to customize and extend it to new problems. Furthermore, we demonstrate the package's capabilities using three use cases, namely hyperparameter tuning, fine-tuning, and defining architectures for multimodal data. Finally, we present some runtime benchmarks.
Constructing Confidence Intervals for 'the' Generalization Error -- a Comprehensive Benchmark Study
Sep 27, 2024When assessing the quality of prediction models in machine learning, confidence intervals (CIs) for the generalization error, which measures predictive performance, are a crucial tool. Luckily, there exist many methods for computing such CIs and new promising approaches are continuously being proposed. Typically, these methods combine various resampling procedures, most popular among them cross-validation and bootstrapping, with different variance estimation techniques. Unfortunately, however, there is currently no consensus on when any of these combinations may be most reliably employed and how they generally compare. In this work, we conduct the first large-scale study comparing CIs for the generalization error - empirically evaluating 13 different methods on a total of 18 tabular regression and classification problems, using four different inducers and a total of eight loss functions. We give an overview of the methodological foundations and inherent challenges of constructing CIs for the generalization error and provide a concise review of all 13 methods in a unified framework. Finally, the CI methods are evaluated in terms of their relative coverage frequency, width, and runtime. Based on these findings, we are able to identify a subset of methods that we would recommend. We also publish the datasets as a benchmarking suite on OpenML and our code on GitHub to serve as a basis for further studies.
GPTopic: Dynamic and Interactive Topic Representations
Mar 06, 2024

Topic modeling seems to be almost synonymous with generating lists of top words to represent topics within large text corpora. However, deducing a topic from such list of individual terms can require substantial expertise and experience, making topic modelling less accessible to people unfamiliar with the particularities and pitfalls of top-word interpretation. A topic representation limited to top-words might further fall short of offering a comprehensive and easily accessible characterization of the various aspects, facets and nuances a topic might have. To address these challenges, we introduce GPTopic, a software package that leverages Large Language Models (LLMs) to create dynamic, interactive topic representations. GPTopic provides an intuitive chat interface for users to explore, analyze, and refine topics interactively, making topic modeling more accessible and comprehensive. The corresponding code is available here: https://github. com/05ec6602be/GPTopic.
BENN: Bias Estimation Using Deep Neural Network
Dec 23, 2020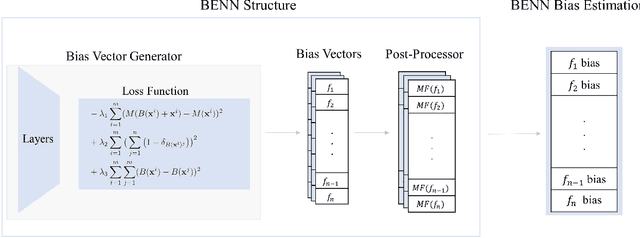

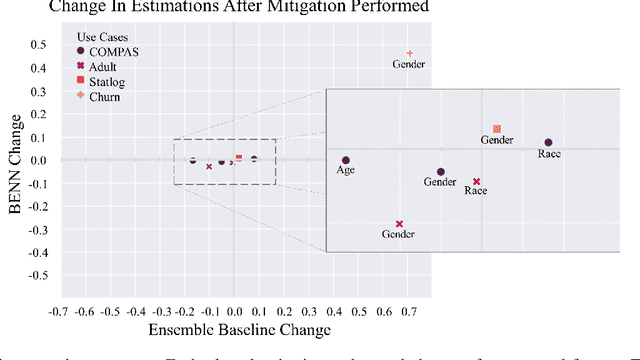
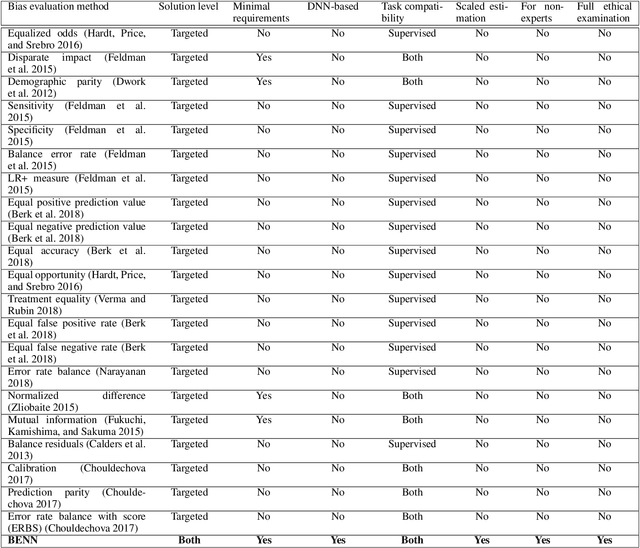
The need to detect bias in machine learning (ML) models has led to the development of multiple bias detection methods, yet utilizing them is challenging since each method: i) explores a different ethical aspect of bias, which may result in contradictory output among the different methods, ii) provides an output of a different range/scale and therefore, can't be compared with other methods, and iii) requires different input, and therefore a human expert needs to be involved to adjust each method according to the examined model. In this paper, we present BENN -- a novel bias estimation method that uses a pretrained unsupervised deep neural network. Given a ML model and data samples, BENN provides a bias estimation for every feature based on the model's predictions. We evaluated BENN using three benchmark datasets and one proprietary churn prediction model used by a European Telco and compared it with an ensemble of 21 existing bias estimation methods. Evaluation results highlight the significant advantages of BENN over the ensemble, as it is generic (i.e., can be applied to any ML model) and there is no need for a domain expert, yet it provides bias estimations that are aligned with those of the ensemble.
Pay More Attention - Neural Architectures for Question-Answering
Mar 25, 2018


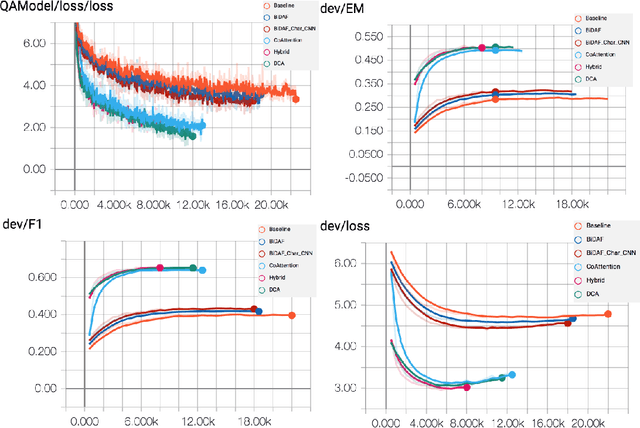
Machine comprehension is a representative task of natural language understanding. Typically, we are given context paragraph and the objective is to answer a question that depends on the context. Such a problem requires to model the complex interactions between the context paragraph and the question. Lately, attention mechanisms have been found to be quite successful at these tasks and in particular, attention mechanisms with attention flow from both context-to-question and question-to-context have been proven to be quite useful. In this paper, we study two state-of-the-art attention mechanisms called Bi-Directional Attention Flow (BiDAF) and Dynamic Co-Attention Network (DCN) and propose a hybrid scheme combining these two architectures that gives better overall performance. Moreover, we also suggest a new simpler attention mechanism that we call Double Cross Attention (DCA) that provides better results compared to both BiDAF and Co-Attention mechanisms while providing similar performance as the hybrid scheme. The objective of our paper is to focus particularly on the attention layer and to suggest improvements on that. Our experimental evaluations show that both our proposed models achieve superior results on the Stanford Question Answering Dataset (SQuAD) compared to BiDAF and DCN attention mechanisms.