 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Uniform to Learned Knots: A Study of Spline-Based Numerical Encodings for Tabular Deep Learning
Apr 07, 2026Numerical preprocessing remains an important component of tabular deep learning, where the representation of continuous features can strongly affect downstream performance. Although its importance is well established for classical statistical and machine learning models, the role of explicit numerical preprocessing in tabular deep learning remains less well understood. In this work, we study this question with a focus on spline-based numerical encodings. We investigate three spline families for encoding numerical features, namely B-splines, M-splines, and integrated splines (I-splines), under uniform, quantile-based, target-aware, and learnable-knot placement. For the learnable-knot variants, we use a differentiable knot parameterization that enables stable end-to-end optimization of knot locations jointly with the backbone. We evaluate these encodings on a diverse collection of public regression and classification datasets using MLP, ResNet, and FT-Transformer backbones, and compare them against common numerical preprocessing baselines. Our results show that the effect of numerical encodings depends strongly on the task, output size, and backbone. For classification, piecewise-linear encoding (PLE) is the most robust choice overall, while spline-based encodings remain competitive. For regression, no single encoding dominates uniformly. Instead, performance depends on the spline family, knot-placement strategy, and output size, with larger gains typically observed for MLP and ResNet than for FT-Transformer. We further find that learnable-knot variants can be optimized stably under the proposed parameterization, but may substantially increase training cost, especially for M-spline and I-spline expansions. Overall, the results show that numerical encodings should be assessed not only in terms of predictive performance, but also in terms of computational overhead.
EviNAM: Intelligibility and Uncertainty via Evidential Neural Additive Models
Jan 13, 2026Intelligibility and accurate uncertainty estimation are crucial for reliable decision-making. In this paper, we propose EviNAM, an extension of evidential learning that integrates the interpretability of Neural Additive Models (NAMs) with principled uncertainty estimation. Unlike standard Bayesian neural networks and previous evidential methods, EviNAM enables, in a single pass, both the estimation of the aleatoric and epistemic uncertainty as well as explicit feature contributions. Experiments on synthetic and real data demonstrate that EviNAM matches state-of-the-art predictive performance. While we focus on regression, our method extends naturally to classification and generalized additive models, offering a path toward more intelligible and trustworthy predictions.
Mambular: A Sequential Model for Tabular Deep Learning
Aug 12, 2024The analysis of tabular data has traditionally been dominated by gradient-boosted decision trees (GBDTs), known for their proficiency with mixed categorical and numerical features. However, recent deep learning innovations are challenging this dominance. We introduce Mambular, an adaptation of the Mamba architecture optimized for tabular data. We extensively benchmark Mambular against state-of-the-art models, including neural networks and tree-based methods, and demonstrate its competitive performance across diverse datasets. Additionally, we explore various adaptations of Mambular to understand its effectiveness for tabular data. We investigate different pooling strategies, feature interaction mechanisms, and bi-directional processing. Our analysis shows that interpreting features as a sequence and passing them through Mamba layers results in surprisingly performant models. The results highlight Mambulars potential as a versatile and powerful architecture for tabular data analysis, expanding the scope of deep learning applications in this domain. The source code is available at https://github.com/basf/mamba-tabular.
GPTopic: Dynamic and Interactive Topic Representations
Mar 06, 2024

Topic modeling seems to be almost synonymous with generating lists of top words to represent topics within large text corpora. However, deducing a topic from such list of individual terms can require substantial expertise and experience, making topic modelling less accessible to people unfamiliar with the particularities and pitfalls of top-word interpretation. A topic representation limited to top-words might further fall short of offering a comprehensive and easily accessible characterization of the various aspects, facets and nuances a topic might have. To address these challenges, we introduce GPTopic, a software package that leverages Large Language Models (LLMs) to create dynamic, interactive topic representations. GPTopic provides an intuitive chat interface for users to explore, analyze, and refine topics interactively, making topic modeling more accessible and comprehensive. The corresponding code is available here: https://github. com/05ec6602be/GPTopic.
Probabilistic Topic Modelling with Transformer Representations
Mar 06, 2024



Topic modelling was mostly dominated by Bayesian graphical models during the last decade. With the rise of transformers in Natural Language Processing, however, several successful models that rely on straightforward clustering approaches in transformer-based embedding spaces have emerged and consolidated the notion of topics as clusters of embedding vectors. We propose the Transformer-Representation Neural Topic Model (TNTM), which combines the benefits of topic representations in transformer-based embedding spaces and probabilistic modelling. Therefore, this approach unifies the powerful and versatile notion of topics based on transformer embeddings with fully probabilistic modelling, as in models such as Latent Dirichlet Allocation (LDA). We utilize the variational autoencoder (VAE) framework for improved inference speed and modelling flexibility. Experimental results show that our proposed model achieves results on par with various state-of-the-art approaches in terms of embedding coherence while maintaining almost perfect topic diversity. The corresponding source code is available at https://github.com/ArikReuter/TNTM.
Topics in the Haystack: Extracting and Evaluating Topics beyond Coherence
Mar 30, 2023



Extracting and identifying latent topics in large text corpora has gained increasing importance in Natural Language Processing (NLP). Most models, whether probabilistic models similar to Latent Dirichlet Allocation (LDA) or neural topic models, follow the same underlying approach of topic interpretability and topic extraction. We propose a method that incorporates a deeper understanding of both sentence and document themes, and goes beyond simply analyzing word frequencies in the data. This allows our model to detect latent topics that may include uncommon words or neologisms, as well as words not present in the documents themselves. Additionally, we propose several new evaluation metrics based on intruder words and similarity measures in the semantic space. We present correlation coefficients with human identification of intruder words and achieve near-human level results at the word-intrusion task. We demonstrate the competitive performance of our method with a large benchmark study, and achieve superior results compared to state-of-the-art topic modeling and document clustering models.
Structural Neural Additive Models: Enhanced Interpretable Machine Learning
Feb 18, 2023



Deep neural networks (DNNs) have shown exceptional performances in a wide range of tasks and have become the go-to method for problems requiring high-level predictive power. There has been extensive research on how DNNs arrive at their decisions, however, the inherently uninterpretable networks remain up to this day mostly unobservable "black boxes". In recent years, the field has seen a push towards interpretable neural networks, such as the visually interpretable Neural Additive Models (NAMs). We propose a further step into the direction of intelligibility beyond the mere visualization of feature effects and propose Structural Neural Additive Models (SNAMs). A modeling framework that combines classical and clearly interpretable statistical methods with the predictive power of neural applications. Our experiments validate the predictive performances of SNAMs. The proposed framework performs comparable to state-of-the-art fully connected DNNs and we show that SNAMs can even outperform NAMs while remaining inherently more interpretable.
Neural Additive Models for Location Scale and Shape: A Framework for Interpretable Neural Regression Beyond the Mean
Jan 27, 2023



Deep neural networks (DNNs) have proven to be highly effective in a variety of tasks, making them the go-to method for problems requiring high-level predictive power. Despite this success, the inner workings of DNNs are often not transparent, making them difficult to interpret or understand. This lack of interpretability has led to increased research on inherently interpretable neural networks in recent years. Models such as Neural Additive Models (NAMs) achieve visual interpretability through the combination of classical statistical methods with DNNs. However, these approaches only concentrate on mean response predictions, leaving out other properties of the response distribution of the underlying data. We propose Neural Additive Models for Location Scale and Shape (NAMLSS), a modelling framework that combines the predictive power of classical deep learning models with the inherent advantages of distributional regression while maintaining the interpretability of additive models.
Human in the loop: How to effectively create coherent topics by manually labeling only a few documents per class
Dec 19, 2022



Few-shot methods for accurate modeling under sparse label-settings have improved significantly. However, the applications of few-shot modeling in natural language processing remain solely in the field of document classification. With recent performance improvements, supervised few-shot methods, combined with a simple topic extraction method pose a significant challenge to unsupervised topic modeling methods. Our research shows that supervised few-shot learning, combined with a simple topic extraction method, can outperform unsupervised topic modeling techniques in terms of generating coherent topics, even when only a few labeled documents per class are used.
Community-Detection via Hashtag-Graphs for Semi-Supervised NMF Topic Models
Nov 17, 2021
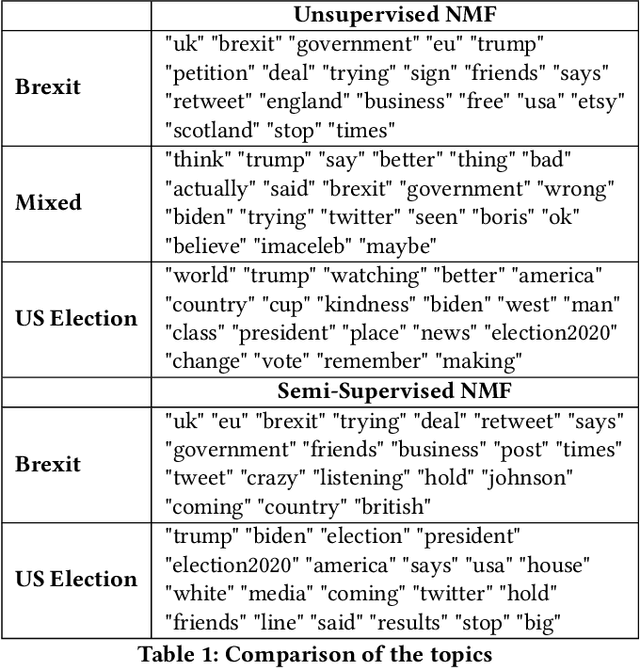

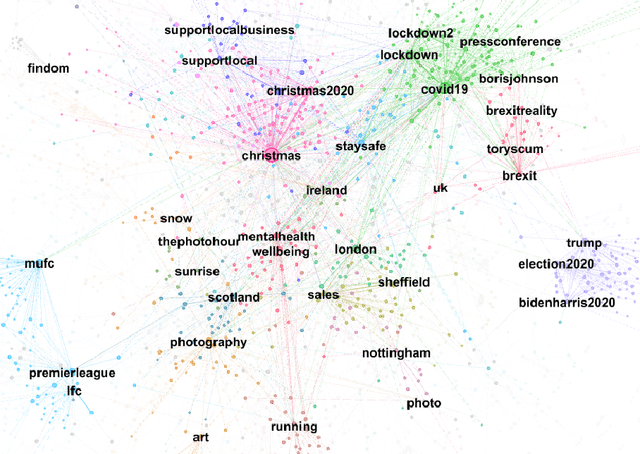
Extracting topics from large collections of unstructured text-documents has become a central task in current NLP applications and algorithms like NMF, LDA as well as their generalizations are the well-established current state of the art. However, especially when it comes to short text documents like Tweets, these approaches often lead to unsatisfying results due to the sparsity of the document-feature matrices. Even though, several approaches have been proposed to overcome this sparsity by taking additional information into account, these are merely focused on the aggregation of similar documents and the estimation of word-co-occurrences. This ultimately completely neglects the fact that a lot of topical-information can be actually retrieved from so-called hashtag-graphs by applying common community detection algorithms. Therefore, this paper outlines a novel approach on how to integrate topic structures of hashtag graphs into the estimation of topic models by connecting graph-based community detection and semi-supervised NMF. By applying this approach on recently streamed Twitter data it will be seen that this procedure actually leads to more intuitive and humanly interpretable topics.