 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Uniform to Learned Knots: A Study of Spline-Based Numerical Encodings for Tabular Deep Learning
Apr 07, 2026Numerical preprocessing remains an important component of tabular deep learning, where the representation of continuous features can strongly affect downstream performance. Although its importance is well established for classical statistical and machine learning models, the role of explicit numerical preprocessing in tabular deep learning remains less well understood. In this work, we study this question with a focus on spline-based numerical encodings. We investigate three spline families for encoding numerical features, namely B-splines, M-splines, and integrated splines (I-splines), under uniform, quantile-based, target-aware, and learnable-knot placement. For the learnable-knot variants, we use a differentiable knot parameterization that enables stable end-to-end optimization of knot locations jointly with the backbone. We evaluate these encodings on a diverse collection of public regression and classification datasets using MLP, ResNet, and FT-Transformer backbones, and compare them against common numerical preprocessing baselines. Our results show that the effect of numerical encodings depends strongly on the task, output size, and backbone. For classification, piecewise-linear encoding (PLE) is the most robust choice overall, while spline-based encodings remain competitive. For regression, no single encoding dominates uniformly. Instead, performance depends on the spline family, knot-placement strategy, and output size, with larger gains typically observed for MLP and ResNet than for FT-Transformer. We further find that learnable-knot variants can be optimized stably under the proposed parameterization, but may substantially increase training cost, especially for M-spline and I-spline expansions. Overall, the results show that numerical encodings should be assessed not only in terms of predictive performance, but also in terms of computational overhead.
EviNAM: Intelligibility and Uncertainty via Evidential Neural Additive Models
Jan 13, 2026Intelligibility and accurate uncertainty estimation are crucial for reliable decision-making. In this paper, we propose EviNAM, an extension of evidential learning that integrates the interpretability of Neural Additive Models (NAMs) with principled uncertainty estimation. Unlike standard Bayesian neural networks and previous evidential methods, EviNAM enables, in a single pass, both the estimation of the aleatoric and epistemic uncertainty as well as explicit feature contributions. Experiments on synthetic and real data demonstrate that EviNAM matches state-of-the-art predictive performance. While we focus on regression, our method extends naturally to classification and generalized additive models, offering a path toward more intelligible and trustworthy predictions.
On the Efficiency of NLP-Inspired Methods for Tabular Deep Learning
Nov 26, 2024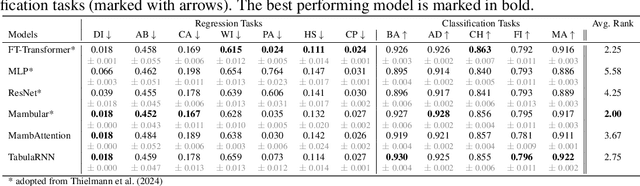
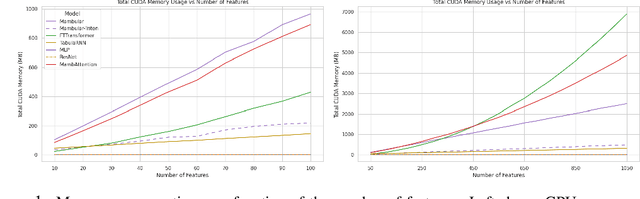
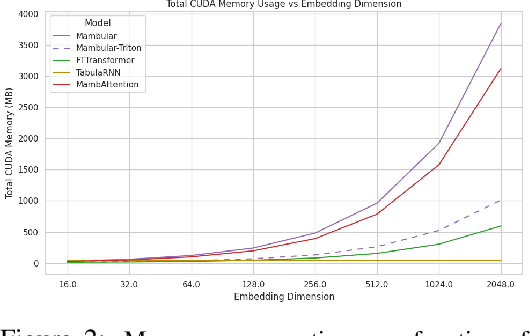
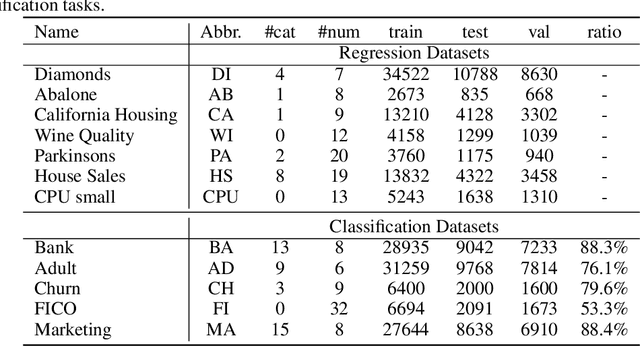
Recent advancements in tabular deep learning (DL) have led to substantial performance improvements, surpassing the capabilities of traditional models. With the adoption of techniques from natural language processing (NLP), such as language model-based approaches, DL models for tabular data have also grown in complexity and size. Although tabular datasets do not typically pose scalability issues, the escalating size of these models has raised efficiency concerns. Despite its importance, efficiency has been relatively underexplored in tabular DL research. This paper critically examines the latest innovations in tabular DL, with a dual focus on performance and computational efficiency. The source code is available at https://github.com/basf/mamba-tabular.
Mambular: A Sequential Model for Tabular Deep Learning
Aug 12, 2024The analysis of tabular data has traditionally been dominated by gradient-boosted decision trees (GBDTs), known for their proficiency with mixed categorical and numerical features. However, recent deep learning innovations are challenging this dominance. We introduce Mambular, an adaptation of the Mamba architecture optimized for tabular data. We extensively benchmark Mambular against state-of-the-art models, including neural networks and tree-based methods, and demonstrate its competitive performance across diverse datasets. Additionally, we explore various adaptations of Mambular to understand its effectiveness for tabular data. We investigate different pooling strategies, feature interaction mechanisms, and bi-directional processing. Our analysis shows that interpreting features as a sequence and passing them through Mamba layers results in surprisingly performant models. The results highlight Mambulars potential as a versatile and powerful architecture for tabular data analysis, expanding the scope of deep learning applications in this domain. The source code is available at https://github.com/basf/mamba-tabular.