 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Iterative RAG Beats Ideal Evidence: A Diagnostic Study in Scientific Multi-hop Question Answering
Jan 27, 2026Retrieval-Augmented Generation (RAG) extends large language models (LLMs) beyond parametric knowledge, yet it is unclear when iterative retrieval-reasoning loops meaningfully outperform static RAG, particularly in scientific domains with multi-hop reasoning, sparse domain knowledge, and heterogeneous evidence. We provide the first controlled, mechanism-level diagnostic study of whether synchronized iterative retrieval and reasoning can surpass an idealized static upper bound (Gold Context) RAG. We benchmark eleven state-of-the-art LLMs under three regimes: (i) No Context, measuring reliance on parametric memory; (ii) Gold Context, where all oracle evidence is supplied at once; and (iii) Iterative RAG, a training-free controller that alternates retrieval, hypothesis refinement, and evidence-aware stopping. Using the chemistry-focused ChemKGMultiHopQA dataset, we isolate questions requiring genuine retrieval and analyze behavior with diagnostics spanning retrieval coverage gaps, anchor-carry drop, query quality, composition fidelity, and control calibration. Across models, Iterative RAG consistently outperforms Gold Context, with gains up to 25.6 percentage points, especially for non-reasoning fine-tuned models. Staged retrieval reduces late-hop failures, mitigates context overload, and enables dynamic correction of early hypothesis drift, but remaining failure modes include incomplete hop coverage, distractor latch trajectories, early stopping miscalibration, and high composition failure rates even with perfect retrieval. Overall, staged retrieval is often more influential than the mere presence of ideal evidence; we provide practical guidance for deploying and diagnosing RAG systems in specialized scientific settings and a foundation for more reliable, controllable iterative retrieval-reasoning frameworks.
Evaluating Multi-Hop Reasoning in Large Language Models: A Chemistry-Centric Case Study
Apr 23, 2025In this study, we introduced a new benchmark consisting of a curated dataset and a defined evaluation process to assess the compositional reasoning capabilities of large language models within the chemistry domain. We designed and validated a fully automated pipeline, verified by subject matter experts, to facilitate this task. Our approach integrates OpenAI reasoning models with named entity recognition (NER) systems to extract chemical entities from recent literature, which are then augmented with external knowledge bases to form a comprehensive knowledge graph. By generating multi-hop questions across these graphs, we assess LLM performance in both context-augmented and non-context augmented settings. Our experiments reveal that even state-of-the-art models face significant challenges in multi-hop compositional reasoning. The results reflect the importance of augmenting LLMs with document retrieval, which can have a substantial impact on improving their performance. However, even perfect retrieval accuracy with full context does not eliminate reasoning errors, underscoring the complexity of compositional reasoning. This work not only benchmarks and highlights the limitations of current LLMs but also presents a novel data generation pipeline capable of producing challenging reasoning datasets across various domains. Overall, this research advances our understanding of reasoning in computational linguistics.
ChemTEB: Chemical Text Embedding Benchmark, an Overview of Embedding Models Performance & Efficiency on a Specific Domain
Nov 30, 2024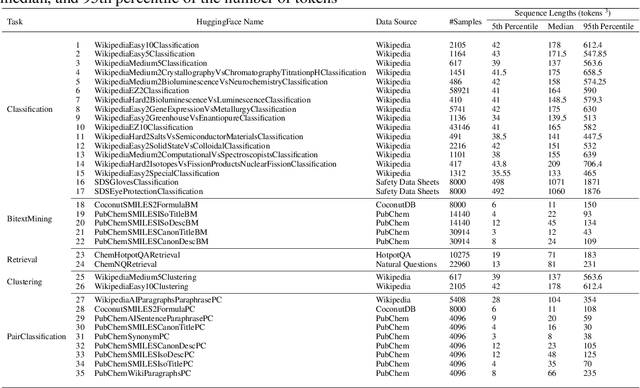
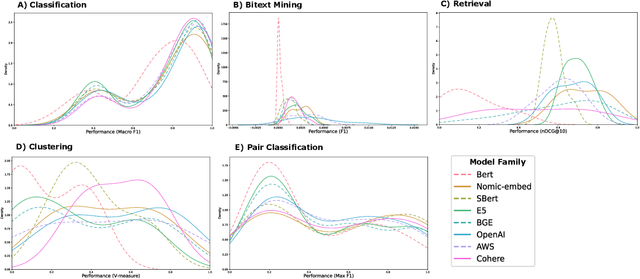
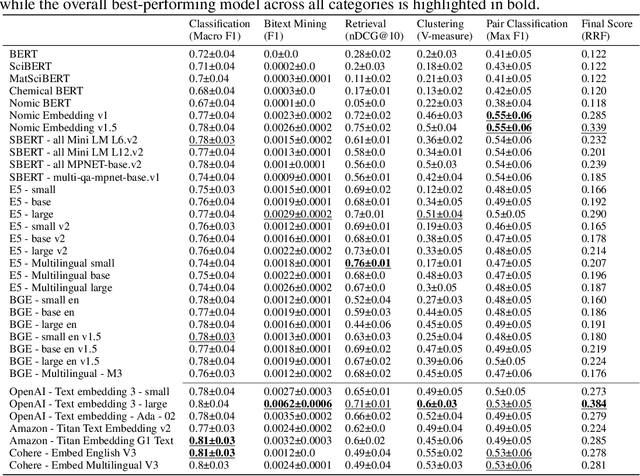
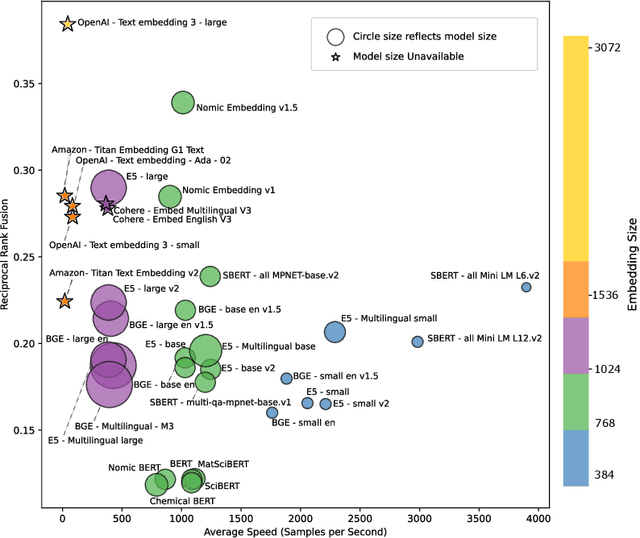
Recent advancements in language models have started a new era of superior information retrieval and content generation, with embedding models playing an important role in optimizing data representation efficiency and performance. While benchmarks like the Massive Text Embedding Benchmark (MTEB) have standardized the evaluation of general domain embedding models, a gap remains in specialized fields such as chemistry, which require tailored approaches due to domain-specific challenges. This paper introduces a novel benchmark, the Chemical Text Embedding Benchmark (ChemTEB), designed specifically for the chemical sciences. ChemTEB addresses the unique linguistic and semantic complexities of chemical literature and data, offering a comprehensive suite of tasks on chemical domain data. Through the evaluation of 34 open-source and proprietary models using this benchmark, we illuminate the strengths and weaknesses of current methodologies in processing and understanding chemical information. Our work aims to equip the research community with a standardized, domain-specific evaluation framework, promoting the development of more precise and efficient NLP models for chemistry-related applications. Furthermore, it provides insights into the performance of generic models in a domain-specific context. ChemTEB comes with open-source code and data, contributing further to its accessibility and utility.
On the Efficiency of NLP-Inspired Methods for Tabular Deep Learning
Nov 26, 2024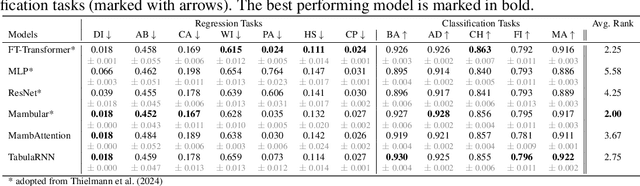
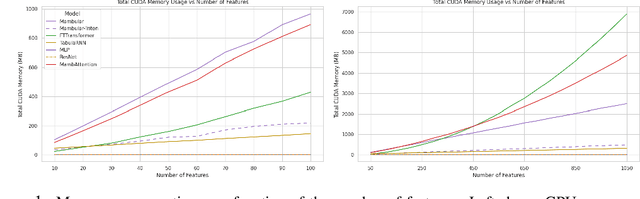
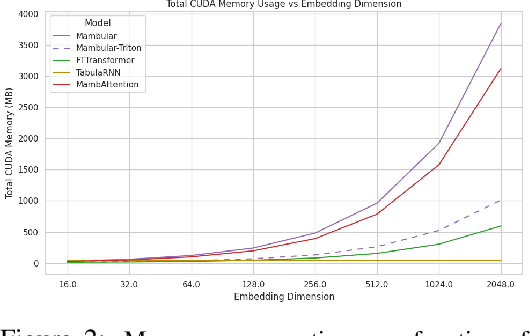
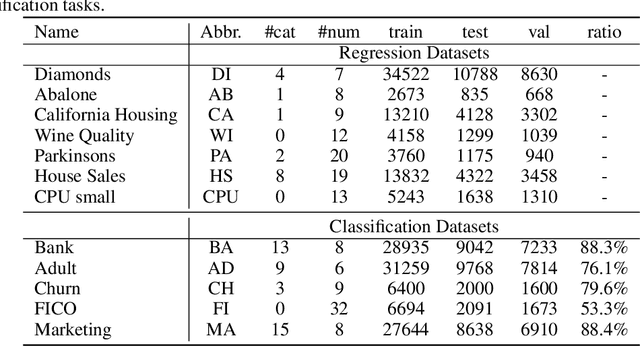
Recent advancements in tabular deep learning (DL) have led to substantial performance improvements, surpassing the capabilities of traditional models. With the adoption of techniques from natural language processing (NLP), such as language model-based approaches, DL models for tabular data have also grown in complexity and size. Although tabular datasets do not typically pose scalability issues, the escalating size of these models has raised efficiency concerns. Despite its importance, efficiency has been relatively underexplored in tabular DL research. This paper critically examines the latest innovations in tabular DL, with a dual focus on performance and computational efficiency. The source code is available at https://github.com/basf/mamba-tabular.
Mambular: A Sequential Model for Tabular Deep Learning
Aug 12, 2024The analysis of tabular data has traditionally been dominated by gradient-boosted decision trees (GBDTs), known for their proficiency with mixed categorical and numerical features. However, recent deep learning innovations are challenging this dominance. We introduce Mambular, an adaptation of the Mamba architecture optimized for tabular data. We extensively benchmark Mambular against state-of-the-art models, including neural networks and tree-based methods, and demonstrate its competitive performance across diverse datasets. Additionally, we explore various adaptations of Mambular to understand its effectiveness for tabular data. We investigate different pooling strategies, feature interaction mechanisms, and bi-directional processing. Our analysis shows that interpreting features as a sequence and passing them through Mamba layers results in surprisingly performant models. The results highlight Mambulars potential as a versatile and powerful architecture for tabular data analysis, expanding the scope of deep learning applications in this domain. The source code is available at https://github.com/basf/mamba-tabular.