 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChemTEB: Chemical Text Embedding Benchmark, an Overview of Embedding Models Performance & Efficiency on a Specific Domain
Nov 30, 2024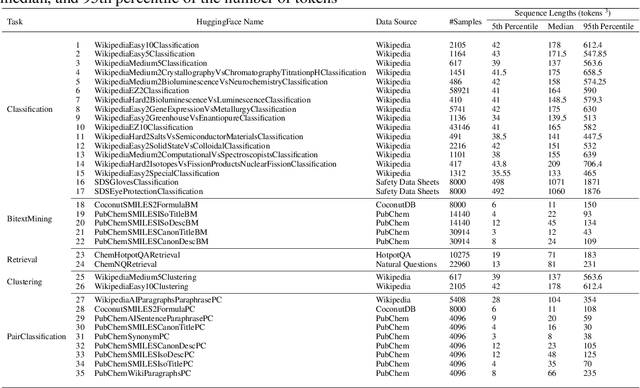
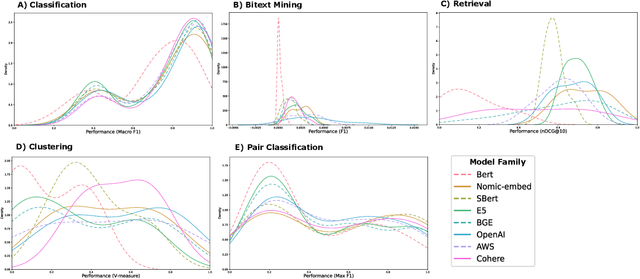
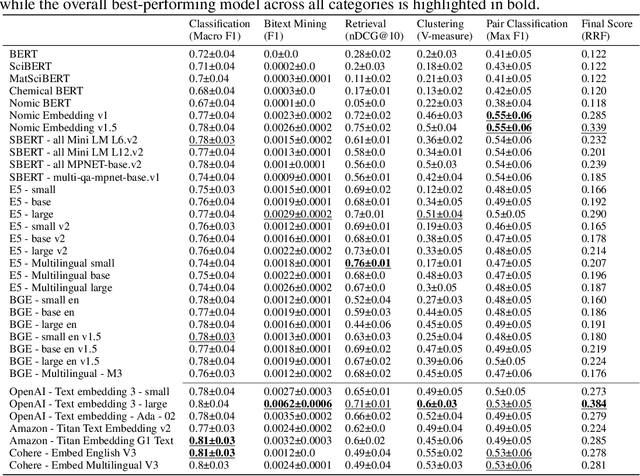
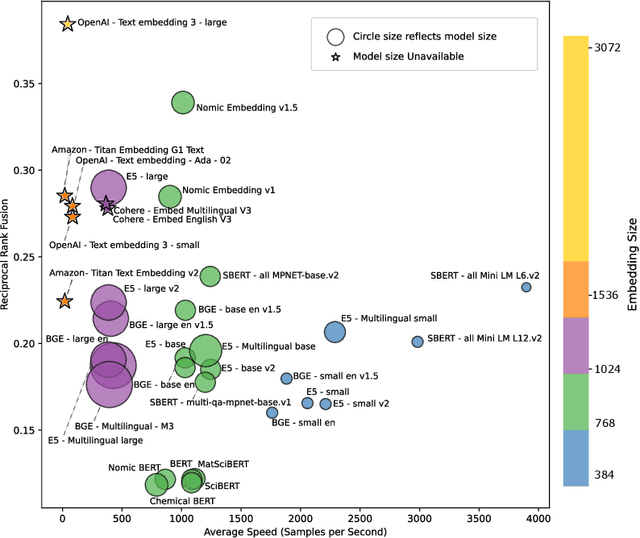
Recent advancements in language models have started a new era of superior information retrieval and content generation, with embedding models playing an important role in optimizing data representation efficiency and performance. While benchmarks like the Massive Text Embedding Benchmark (MTEB) have standardized the evaluation of general domain embedding models, a gap remains in specialized fields such as chemistry, which require tailored approaches due to domain-specific challenges. This paper introduces a novel benchmark, the Chemical Text Embedding Benchmark (ChemTEB), designed specifically for the chemical sciences. ChemTEB addresses the unique linguistic and semantic complexities of chemical literature and data, offering a comprehensive suite of tasks on chemical domain data. Through the evaluation of 34 open-source and proprietary models using this benchmark, we illuminate the strengths and weaknesses of current methodologies in processing and understanding chemical information. Our work aims to equip the research community with a standardized, domain-specific evaluation framework, promoting the development of more precise and efficient NLP models for chemistry-related applications. Furthermore, it provides insights into the performance of generic models in a domain-specific context. ChemTEB comes with open-source code and data, contributing further to its accessibility and utility.