 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Augmented Changepoint Detection: A Framework for Ensemble Detection and Automated Explanation
Jan 06, 2026This paper introduces a novel changepoint detection framework that combines ensemble statistical methods with Large Language Models (LLMs) to enhance both detection accuracy and the interpretability of regime changes in time series data. Two critical limitations in the field are addressed. First, individual detection methods exhibit complementary strengths and weaknesses depending on data characteristics, making method selection non-trivial and prone to suboptimal results. Second, automated, contextual explanations for detected changes are largely absent. The proposed ensemble method aggregates results from ten distinct changepoint detection algorithms, achieving superior performance and robustness compared to individual methods. Additionally, an LLM-powered explanation pipeline automatically generates contextual narratives, linking detected changepoints to potential real-world historical events. For private or domain-specific data, a Retrieval-Augmented Generation (RAG) solution enables explanations grounded in user-provided documents. The open source Python framework demonstrates practical utility in diverse domains, including finance, political science, and environmental science, transforming raw statistical output into actionable insights for analysts and decision-makers.
From XAI to Stories: A Factorial Study of LLM-Generated Explanation Quality
Jan 05, 2026Explainable AI (XAI) methods like SHAP and LIME produce numerical feature attributions that remain inaccessible to non expert users. Prior work has shown that Large Language Models (LLMs) can transform these outputs into natural language explanations (NLEs), but it remains unclear which factors contribute to high-quality explanations. We present a systematic factorial study investigating how Forecasting model choice, XAI method, LLM selection, and prompting strategy affect NLE quality. Our design spans four models (XGBoost (XGB), Random Forest (RF), Multilayer Perceptron (MLP), and SARIMAX - comparing black-box Machine-Learning (ML) against classical time-series approaches), three XAI conditions (SHAP, LIME, and a no-XAI baseline), three LLMs (GPT-4o, Llama-3-8B, DeepSeek-R1), and eight prompting strategies. Using G-Eval, an LLM-as-a-judge evaluation method, with dual LLM judges and four evaluation criteria, we evaluate 660 explanations for time-series forecasting. Our results suggest that: (1) XAI provides only small improvements over no-XAI baselines, and only for expert audiences; (2) LLM choice dominates all other factors, with DeepSeek-R1 outperforming GPT-4o and Llama-3; (3) we observe an interpretability paradox: in our setting, SARIMAX yielded lower NLE quality than ML models despite higher prediction accuracy; (4) zero-shot prompting is competitive with self-consistency at 7-times lower cost; and (5) chain-of-thought hurts rather than helps.
LabelFusion: Learning to Fuse LLMs and Transformer Classifiers for Robust Text Classification
Dec 11, 2025LabelFusion is a fusion ensemble for text classification that learns to combine a traditional transformer-based classifier (e.g., RoBERTa) with one or more Large Language Models (LLMs such as OpenAI GPT, Google Gemini, or DeepSeek) to deliver accurate and cost-aware predictions across multi-class and multi-label tasks. The package provides a simple high-level interface (AutoFusionClassifier) that trains the full pipeline end-to-end with minimal configuration, and a flexible API for advanced users. Under the hood, LabelFusion integrates vector signals from both sources by concatenating the ML backbone's embeddings with the LLM-derived per-class scores -- obtained through structured prompt-engineering strategies -- and feeds this joint representation into a compact multi-layer perceptron (FusionMLP) that produces the final prediction. This learned fusion approach captures complementary strengths of LLM reasoning and traditional transformer-based classifiers, yielding robust performance across domains -- achieving 92.4% accuracy on AG News and 92.3% on 10-class Reuters 21578 topic classification -- while enabling practical trade-offs between accuracy, latency, and cost.
Mambular: A Sequential Model for Tabular Deep Learning
Aug 12, 2024The analysis of tabular data has traditionally been dominated by gradient-boosted decision trees (GBDTs), known for their proficiency with mixed categorical and numerical features. However, recent deep learning innovations are challenging this dominance. We introduce Mambular, an adaptation of the Mamba architecture optimized for tabular data. We extensively benchmark Mambular against state-of-the-art models, including neural networks and tree-based methods, and demonstrate its competitive performance across diverse datasets. Additionally, we explore various adaptations of Mambular to understand its effectiveness for tabular data. We investigate different pooling strategies, feature interaction mechanisms, and bi-directional processing. Our analysis shows that interpreting features as a sequence and passing them through Mamba layers results in surprisingly performant models. The results highlight Mambulars potential as a versatile and powerful architecture for tabular data analysis, expanding the scope of deep learning applications in this domain. The source code is available at https://github.com/basf/mamba-tabular.
Probabilistic Topic Modelling with Transformer Representations
Mar 06, 2024Topic modelling was mostly dominated by Bayesian graphical models during the last decade. With the rise of transformers in Natural Language Processing, however, several successful models that rely on straightforward clustering approaches in transformer-based embedding spaces have emerged and consolidated the notion of topics as clusters of embedding vectors. We propose the Transformer-Representation Neural Topic Model (TNTM), which combines the benefits of topic representations in transformer-based embedding spaces and probabilistic modelling. Therefore, this approach unifies the powerful and versatile notion of topics based on transformer embeddings with fully probabilistic modelling, as in models such as Latent Dirichlet Allocation (LDA). We utilize the variational autoencoder (VAE) framework for improved inference speed and modelling flexibility. Experimental results show that our proposed model achieves results on par with various state-of-the-art approaches in terms of embedding coherence while maintaining almost perfect topic diversity. The corresponding source code is available at https://github.com/ArikReuter/TNTM.
GPTopic: Dynamic and Interactive Topic Representations
Mar 06, 2024

Topic modeling seems to be almost synonymous with generating lists of top words to represent topics within large text corpora. However, deducing a topic from such list of individual terms can require substantial expertise and experience, making topic modelling less accessible to people unfamiliar with the particularities and pitfalls of top-word interpretation. A topic representation limited to top-words might further fall short of offering a comprehensive and easily accessible characterization of the various aspects, facets and nuances a topic might have. To address these challenges, we introduce GPTopic, a software package that leverages Large Language Models (LLMs) to create dynamic, interactive topic representations. GPTopic provides an intuitive chat interface for users to explore, analyze, and refine topics interactively, making topic modeling more accessible and comprehensive. The corresponding code is available here: https://github. com/05ec6602be/GPTopic.
Human in the loop: How to effectively create coherent topics by manually labeling only a few documents per class
Dec 19, 2022



Few-shot methods for accurate modeling under sparse label-settings have improved significantly. However, the applications of few-shot modeling in natural language processing remain solely in the field of document classification. With recent performance improvements, supervised few-shot methods, combined with a simple topic extraction method pose a significant challenge to unsupervised topic modeling methods. Our research shows that supervised few-shot learning, combined with a simple topic extraction method, can outperform unsupervised topic modeling techniques in terms of generating coherent topics, even when only a few labeled documents per class are used.
Community-Detection via Hashtag-Graphs for Semi-Supervised NMF Topic Models
Nov 17, 2021
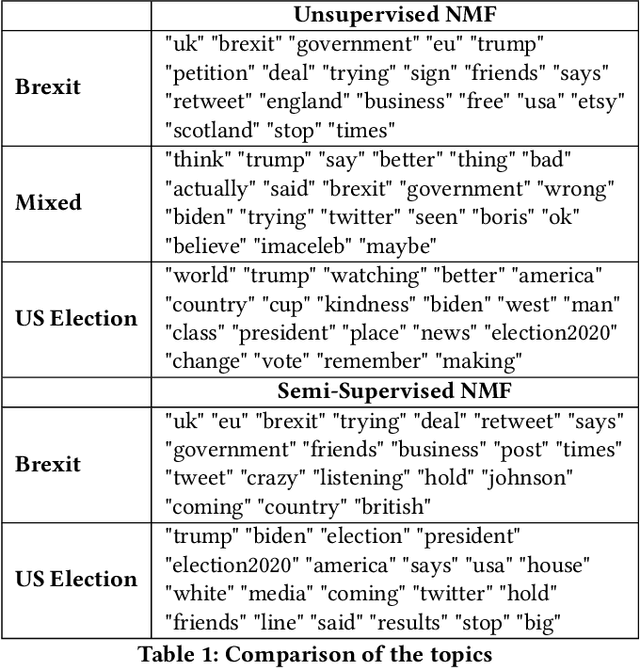

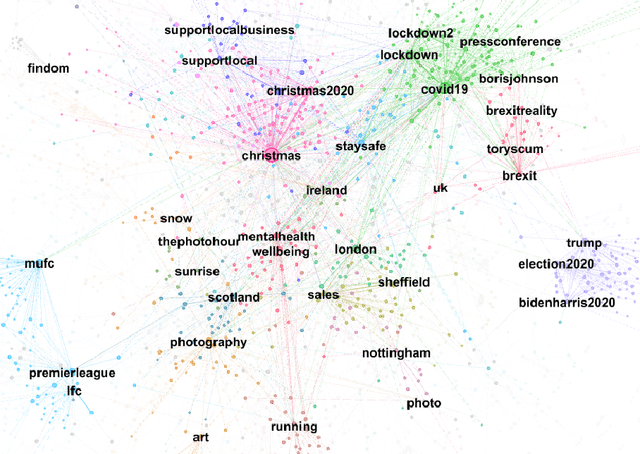
Extracting topics from large collections of unstructured text-documents has become a central task in current NLP applications and algorithms like NMF, LDA as well as their generalizations are the well-established current state of the art. However, especially when it comes to short text documents like Tweets, these approaches often lead to unsatisfying results due to the sparsity of the document-feature matrices. Even though, several approaches have been proposed to overcome this sparsity by taking additional information into account, these are merely focused on the aggregation of similar documents and the estimation of word-co-occurrences. This ultimately completely neglects the fact that a lot of topical-information can be actually retrieved from so-called hashtag-graphs by applying common community detection algorithms. Therefore, this paper outlines a novel approach on how to integrate topic structures of hashtag graphs into the estimation of topic models by connecting graph-based community detection and semi-supervised NMF. By applying this approach on recently streamed Twitter data it will be seen that this procedure actually leads to more intuitive and humanly interpretable topics.