 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Augmented Changepoint Detection: A Framework for Ensemble Detection and Automated Explanation
Jan 06, 2026This paper introduces a novel changepoint detection framework that combines ensemble statistical methods with Large Language Models (LLMs) to enhance both detection accuracy and the interpretability of regime changes in time series data. Two critical limitations in the field are addressed. First, individual detection methods exhibit complementary strengths and weaknesses depending on data characteristics, making method selection non-trivial and prone to suboptimal results. Second, automated, contextual explanations for detected changes are largely absent. The proposed ensemble method aggregates results from ten distinct changepoint detection algorithms, achieving superior performance and robustness compared to individual methods. Additionally, an LLM-powered explanation pipeline automatically generates contextual narratives, linking detected changepoints to potential real-world historical events. For private or domain-specific data, a Retrieval-Augmented Generation (RAG) solution enables explanations grounded in user-provided documents. The open source Python framework demonstrates practical utility in diverse domains, including finance, political science, and environmental science, transforming raw statistical output into actionable insights for analysts and decision-makers.
From XAI to Stories: A Factorial Study of LLM-Generated Explanation Quality
Jan 05, 2026Explainable AI (XAI) methods like SHAP and LIME produce numerical feature attributions that remain inaccessible to non expert users. Prior work has shown that Large Language Models (LLMs) can transform these outputs into natural language explanations (NLEs), but it remains unclear which factors contribute to high-quality explanations. We present a systematic factorial study investigating how Forecasting model choice, XAI method, LLM selection, and prompting strategy affect NLE quality. Our design spans four models (XGBoost (XGB), Random Forest (RF), Multilayer Perceptron (MLP), and SARIMAX - comparing black-box Machine-Learning (ML) against classical time-series approaches), three XAI conditions (SHAP, LIME, and a no-XAI baseline), three LLMs (GPT-4o, Llama-3-8B, DeepSeek-R1), and eight prompting strategies. Using G-Eval, an LLM-as-a-judge evaluation method, with dual LLM judges and four evaluation criteria, we evaluate 660 explanations for time-series forecasting. Our results suggest that: (1) XAI provides only small improvements over no-XAI baselines, and only for expert audiences; (2) LLM choice dominates all other factors, with DeepSeek-R1 outperforming GPT-4o and Llama-3; (3) we observe an interpretability paradox: in our setting, SARIMAX yielded lower NLE quality than ML models despite higher prediction accuracy; (4) zero-shot prompting is competitive with self-consistency at 7-times lower cost; and (5) chain-of-thought hurts rather than helps.
Benchmarking pig detection and tracking under diverse and challenging conditions
Jul 22, 2025To ensure animal welfare and effective management in pig farming, monitoring individual behavior is a crucial prerequisite. While monitoring tasks have traditionally been carried out manually, advances in machine learning have made it possible to collect individualized information in an increasingly automated way. Central to these methods is the localization of animals across space (object detection) and time (multi-object tracking). Despite extensive research of these two tasks in pig farming, a systematic benchmarking study has not yet been conducted. In this work, we address this gap by curating two datasets: PigDetect for object detection and PigTrack for multi-object tracking. The datasets are based on diverse image and video material from realistic barn conditions, and include challenging scenarios such as occlusions or bad visibility. For object detection, we show that challenging training images improve detection performance beyond what is achievable with randomly sampled images alone. Comparing different approaches, we found that state-of-the-art models offer substantial improvements in detection quality over real-time alternatives. For multi-object tracking, we observed that SORT-based methods achieve superior detection performance compared to end-to-end trainable models. However, end-to-end models show better association performance, suggesting they could become strong alternatives in the future. We also investigate characteristic failure cases of end-to-end models, providing guidance for future improvements. The detection and tracking models trained on our datasets perform well in unseen pens, suggesting good generalization capabilities. This highlights the importance of high-quality training data. The datasets and research code are made publicly available to facilitate reproducibility, re-use and further development.
Hybrid Bernstein Normalizing Flows for Flexible Multivariate Density Regression with Interpretable Marginals
May 20, 2025Density regression models allow a comprehensive understanding of data by modeling the complete conditional probability distribution. While flexible estimation approaches such as normalizing flows (NF) work particularly well in multiple dimensions, interpreting the input-output relationship of such models is often difficult, due to the black-box character of deep learning models. In contrast, existing statistical methods for multivariate outcomes such as multivariate conditional transformation models (MCTM) are restricted in flexibility and are often not expressive enough to represent complex multivariate probability distributions. In this paper, we combine MCTM with state-of-the-art and autoregressive NF to leverage the transparency of MCTM for modeling interpretable feature effects on the marginal distributions in the first step and the flexibility of neural-network-based NF techniques to account for complex and non-linear relationships in the joint data distribution. We demonstrate our method's versatility in various numerical experiments and compare it with MCTM and other NF models on both simulated and real-world data.
Probabilistic Topic Modelling with Transformer Representations
Mar 06, 2024Topic modelling was mostly dominated by Bayesian graphical models during the last decade. With the rise of transformers in Natural Language Processing, however, several successful models that rely on straightforward clustering approaches in transformer-based embedding spaces have emerged and consolidated the notion of topics as clusters of embedding vectors. We propose the Transformer-Representation Neural Topic Model (TNTM), which combines the benefits of topic representations in transformer-based embedding spaces and probabilistic modelling. Therefore, this approach unifies the powerful and versatile notion of topics based on transformer embeddings with fully probabilistic modelling, as in models such as Latent Dirichlet Allocation (LDA). We utilize the variational autoencoder (VAE) framework for improved inference speed and modelling flexibility. Experimental results show that our proposed model achieves results on par with various state-of-the-art approaches in terms of embedding coherence while maintaining almost perfect topic diversity. The corresponding source code is available at https://github.com/ArikReuter/TNTM.
TreeLearn: A Comprehensive Deep Learning Method for Segmenting Individual Trees from Forest Point Clouds
Sep 15, 2023

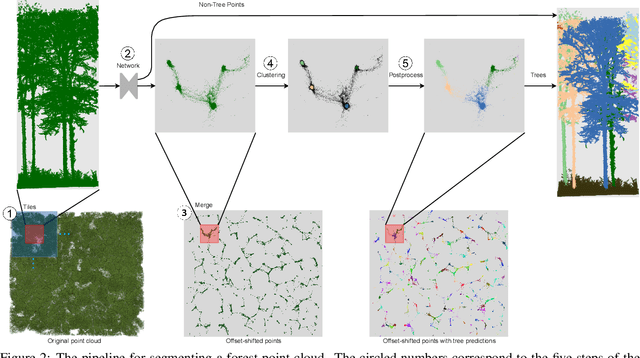

Laser-scanned point clouds of forests make it possible to extract valuable information for forest management. To consider single trees, a forest point cloud needs to be segmented into individual tree point clouds. Existing segmentation methods are usually based on hand-crafted algorithms, such as identifying trunks and growing trees from them, and face difficulties in dense forests with overlapping tree crowns. In this study, we propose \mbox{TreeLearn}, a deep learning-based approach for semantic and instance segmentation of forest point clouds. Unlike previous methods, TreeLearn is trained on already segmented point clouds in a data-driven manner, making it less reliant on predefined features and algorithms. Additionally, we introduce a new manually segmented benchmark forest dataset containing 156 full trees, and 79 partial trees, that have been cleanly segmented by hand. This enables the evaluation of instance segmentation performance going beyond just evaluating the detection of individual trees. We trained TreeLearn on forest point clouds of 6665 trees, labeled using the Lidar360 software. An evaluation on the benchmark dataset shows that TreeLearn performs equally well or better than the algorithm used to generate its training data. Furthermore, the method's performance can be vastly improved by fine-tuning on the cleanly labeled benchmark dataset. The TreeLearn code is availabe from https://github.com/ecker-lab/TreeLearn. The data as well as trained models can be found at https://doi.org/10.25625/VPMPID.
Neural Additive Models for Location Scale and Shape: A Framework for Interpretable Neural Regression Beyond the Mean
Jan 27, 2023



Deep neural networks (DNNs) have proven to be highly effective in a variety of tasks, making them the go-to method for problems requiring high-level predictive power. Despite this success, the inner workings of DNNs are often not transparent, making them difficult to interpret or understand. This lack of interpretability has led to increased research on inherently interpretable neural networks in recent years. Models such as Neural Additive Models (NAMs) achieve visual interpretability through the combination of classical statistical methods with DNNs. However, these approaches only concentrate on mean response predictions, leaving out other properties of the response distribution of the underlying data. We propose Neural Additive Models for Location Scale and Shape (NAMLSS), a modelling framework that combines the predictive power of classical deep learning models with the inherent advantages of distributional regression while maintaining the interpretability of additive models.
Bayesian Discrete Conditional Transformation Models
May 17, 2022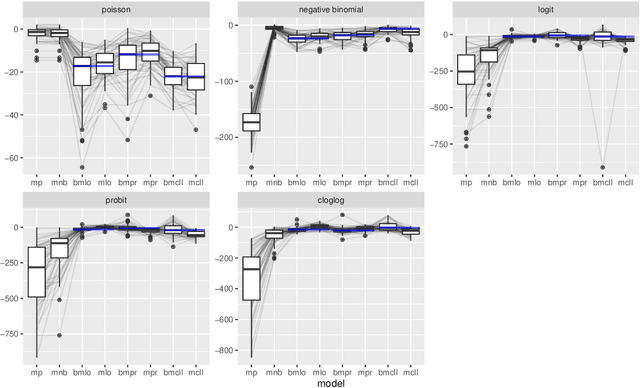
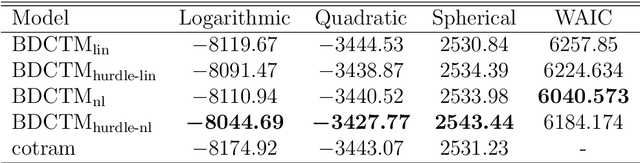
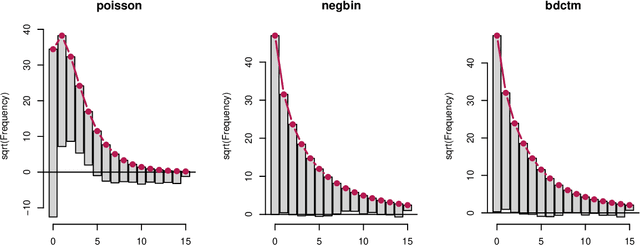
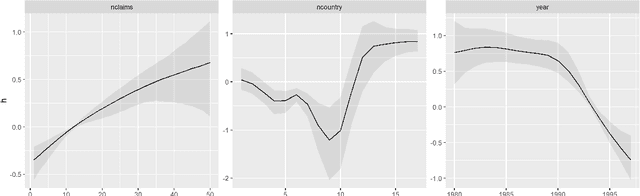
We propose a novel Bayesian model framework for discrete ordinal and count data based on conditional transformations of the responses. The conditional transformation function is estimated from the data in conjunction with an a priori chosen reference distribution. For count responses, the resulting transformation model is novel in the sense that it is a Bayesian fully parametric yet distribution-free approach that can additionally account for excess zeros with additive transformation function specifications. For ordinal categoric responses, our cumulative link transformation model allows the inclusion of linear and nonlinear covariate effects that can additionally be made category-specific, resulting in (non-)proportional odds or hazards models and more, depending on the choice of the reference distribution. Inference is conducted by a generic modular Markov chain Monte Carlo algorithm where multivariate Gaussian priors enforce specific properties such as smoothness on the functional effects. To illustrate the versatility of Bayesian discrete conditional transformation models, applications to counts of patent citations in the presence of excess zeros and on treating forest health categories in a discrete partial proportional odds model are presented.
Distributional Gradient Boosting Machines
Apr 02, 2022
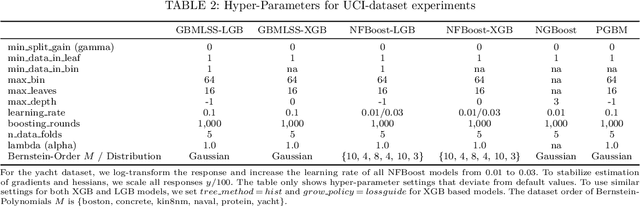
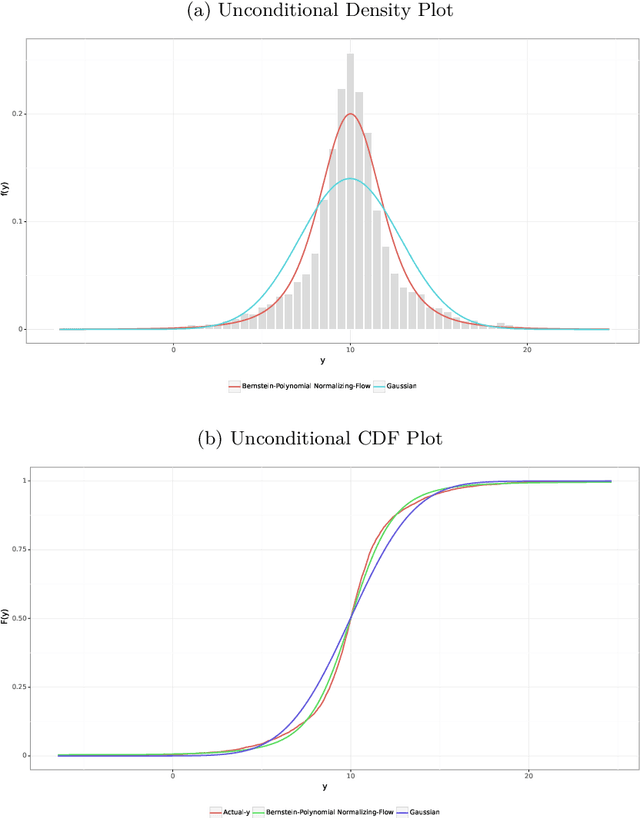
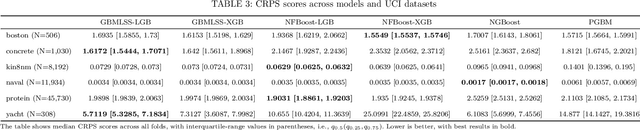
We present a unified probabilistic gradient boosting framework for regression tasks that models and predicts the entire conditional distribution of a univariate response variable as a function of covariates. Our likelihood-based approach allows us to either model all conditional moments of a parametric distribution, or to approximate the conditional cumulative distribution function via Normalizing Flows. As underlying computational backbones, our framework is based on XGBoost and LightGBM. Modelling and predicting the entire conditional distribution greatly enhances existing tree-based gradient boosting implementations, as it allows to create probabilistic forecasts from which prediction intervals and quantiles of interest can be derived. Empirical results show that our framework achieves state-of-the-art forecast accuracy.
Transforming Autoregression: Interpretable and Expressive Time Series Forecast
Oct 15, 2021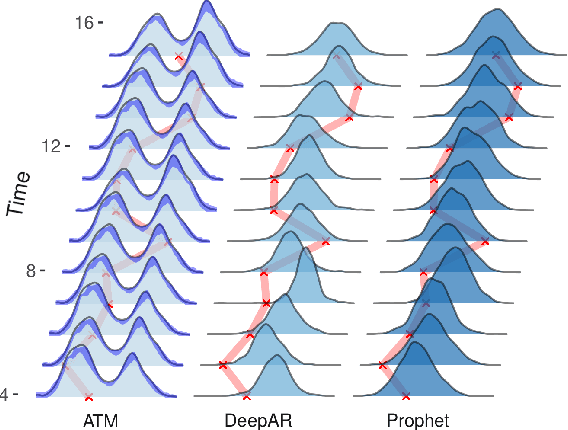

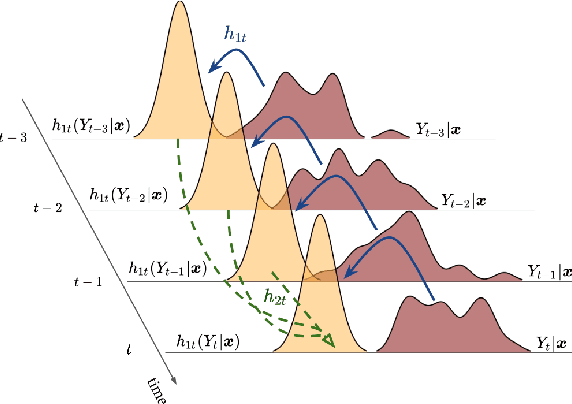

Probabilistic forecasting of time series is an important matter in many applications and research fields. In order to draw conclusions from a probabilistic forecast, we must ensure that the model class used to approximate the true forecasting distribution is expressive enough. Yet, characteristics of the model itself, such as its uncertainty or its general functioning are not of lesser importance. In this paper, we propose Autoregressive Transformation Models (ATMs), a model class inspired from various research directions such as normalizing flows and autoregressive models. ATMs unite expressive distributional forecasts using a semi-parametric distribution assumption with an interpretable model specification and allow for uncertainty quantification based on (asymptotic) Maximum Likelihood theory. We demonstrate the properties of ATMs both theoretically and through empirical evaluation on several simulated and real-world forecasting datasets.