 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecasting with Hyper-Trees
May 17, 2024This paper introduces the concept of Hyper-Trees and offers a new direction in applying tree-based models to time series data. Unlike conventional applications of decision trees that forecast time series directly, Hyper-Trees are designed to learn the parameters of a target time series model. Our framework leverages the gradient-based nature of boosted trees, which allows us to extend the concept of Hyper-Networks to Hyper-Trees and to induce a time-series inductive bias to tree models. By relating the parameters of a target time series model to features, Hyper-Trees address the issue of parameter non-stationarity and enable tree-based forecasts to extend beyond their training range. With our research, we aim to explore the effectiveness of Hyper-Trees across various forecasting scenarios and to extend the application of gradient boosted decision trees outside their conventional use in time series modeling.
Multi-Target XGBoostLSS Regression
Oct 13, 2022


Current implementations of Gradient Boosting Machines are mostly designed for single-target regression tasks and commonly assume independence between responses when used in multivariate settings. As such, these models are not well suited if non-negligible dependencies exist between targets. To overcome this limitation, we present an extension of XGBoostLSS that models multiple targets and their dependencies in a probabilistic regression setting. Empirical results show that our approach outperforms existing GBMs with respect to runtime and compares well in terms of accuracy.
Distributional Gradient Boosting Machines
Apr 02, 2022
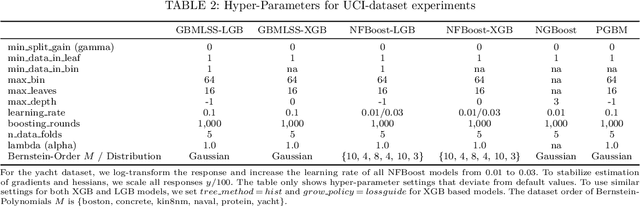
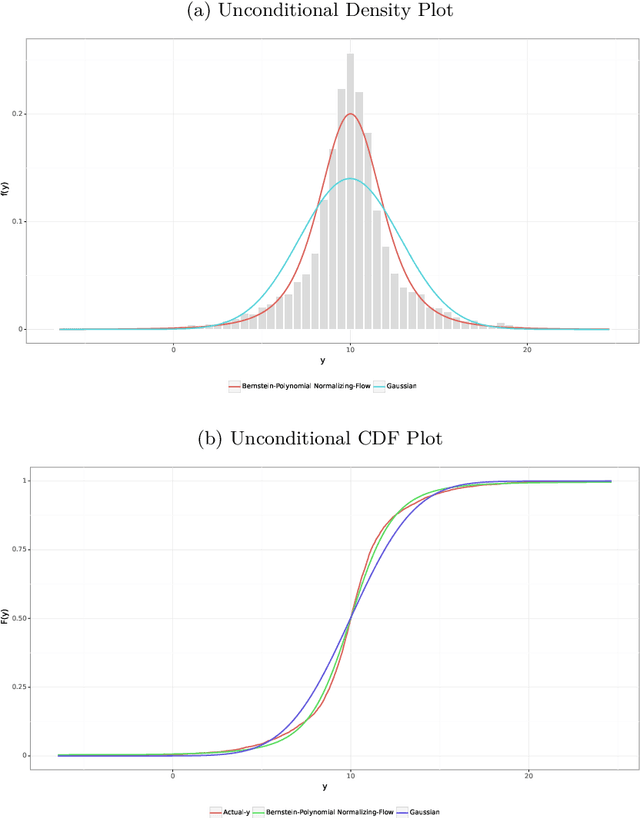
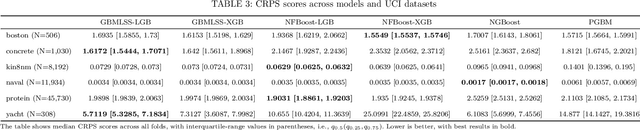
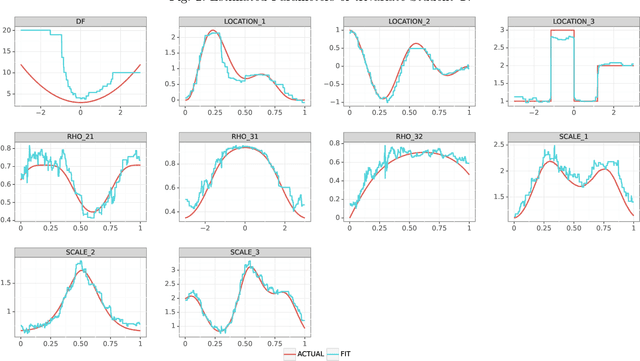
We present a unified probabilistic gradient boosting framework for regression tasks that models and predicts the entire conditional distribution of a univariate response variable as a function of covariates. Our likelihood-based approach allows us to either model all conditional moments of a parametric distribution, or to approximate the conditional cumulative distribution function via Normalizing Flows. As underlying computational backbones, our framework is based on XGBoost and LightGBM. Modelling and predicting the entire conditional distribution greatly enhances existing tree-based gradient boosting implementations, as it allows to create probabilistic forecasts from which prediction intervals and quantiles of interest can be derived. Empirical results show that our framework achieves state-of-the-art forecast accuracy.
CatBoostLSS -- An extension of CatBoost to probabilistic forecasting
Jan 04, 2020

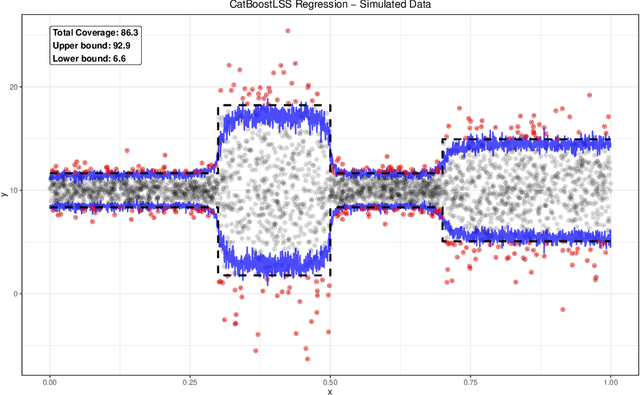

We propose a new framework of CatBoost that predicts the entire conditional distribution of a univariate response variable. In particular, CatBoostLSS models all moments of a parametric distribution (i.e., mean, location, scale and shape [LSS]) instead of the conditional mean only. Choosing from a wide range of continuous, discrete and mixed discrete-continuous distributions, modelling and predicting the entire conditional distribution greatly enhances the flexibility of CatBoost, as it allows to gain insight into the data generating process, as well as to create probabilistic forecasts from which prediction intervals and quantiles of interest can be derived. We present both a simulation study and real-world examples that demonstrate the benefits of our approach.
XGBoostLSS -- An extension of XGBoost to probabilistic forecasting
Aug 11, 2019

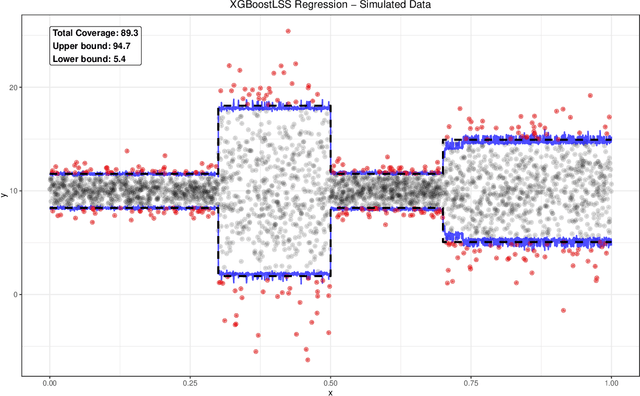

We propose a new framework of XGBoost that predicts the entire conditional distribution of a univariate response variable. In particular, XGBoostLSS models all moments of a parametric distribution (i.e., mean, location, scale and shape [LSS]) instead of the conditional mean only. Choosing from a wide range of continuous, discrete and mixed discrete-continuous distribution, modelling and predicting the entire conditional distribution greatly enhances the flexibility of XGBoost, as it allows to gain additional insight into the data generating process, as well as to create probabilistic forecasts from which prediction intervals and quantiles of interest can be derived. We present both a simulation study and real world examples that demonstrate the virtues of our approach.