 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunity-Detection via Hashtag-Graphs for Semi-Supervised NMF Topic Models
Paper and Code
Nov 17, 2021
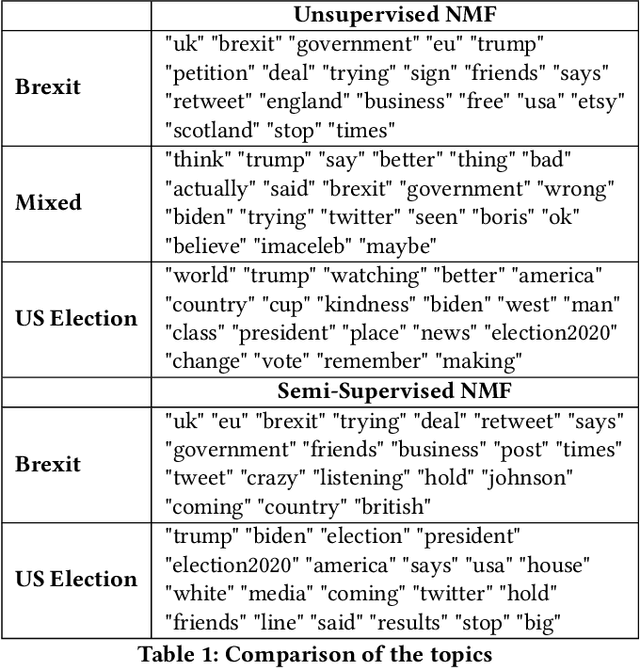

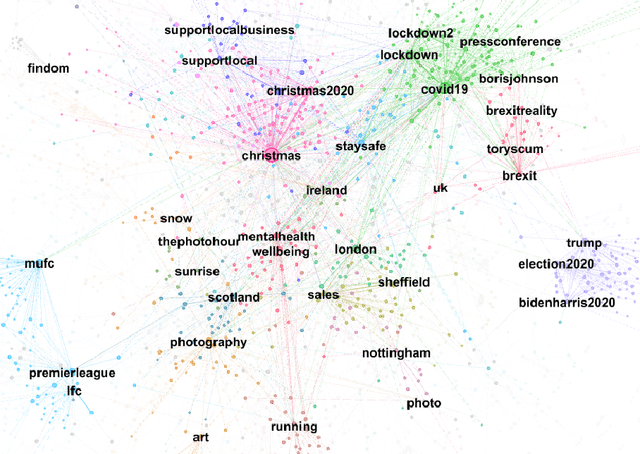
Extracting topics from large collections of unstructured text-documents has become a central task in current NLP applications and algorithms like NMF, LDA as well as their generalizations are the well-established current state of the art. However, especially when it comes to short text documents like Tweets, these approaches often lead to unsatisfying results due to the sparsity of the document-feature matrices. Even though, several approaches have been proposed to overcome this sparsity by taking additional information into account, these are merely focused on the aggregation of similar documents and the estimation of word-co-occurrences. This ultimately completely neglects the fact that a lot of topical-information can be actually retrieved from so-called hashtag-graphs by applying common community detection algorithms. Therefore, this paper outlines a novel approach on how to integrate topic structures of hashtag graphs into the estimation of topic models by connecting graph-based community detection and semi-supervised NMF. By applying this approach on recently streamed Twitter data it will be seen that this procedure actually leads to more intuitive and humanly interpretable topics.