 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopics in the Haystack: Extracting and Evaluating Topics beyond Coherence
Mar 30, 2023



Extracting and identifying latent topics in large text corpora has gained increasing importance in Natural Language Processing (NLP). Most models, whether probabilistic models similar to Latent Dirichlet Allocation (LDA) or neural topic models, follow the same underlying approach of topic interpretability and topic extraction. We propose a method that incorporates a deeper understanding of both sentence and document themes, and goes beyond simply analyzing word frequencies in the data. This allows our model to detect latent topics that may include uncommon words or neologisms, as well as words not present in the documents themselves. Additionally, we propose several new evaluation metrics based on intruder words and similarity measures in the semantic space. We present correlation coefficients with human identification of intruder words and achieve near-human level results at the word-intrusion task. We demonstrate the competitive performance of our method with a large benchmark study, and achieve superior results compared to state-of-the-art topic modeling and document clustering models.
Bayesian Boosting for Linear Mixed Models
Jun 09, 2021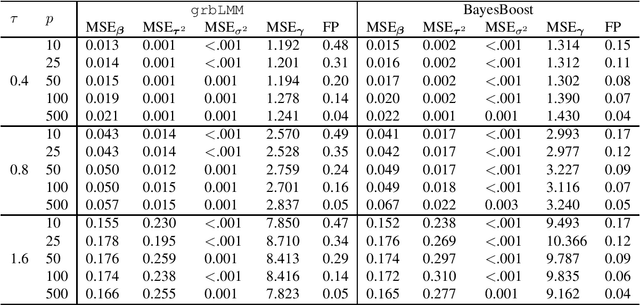
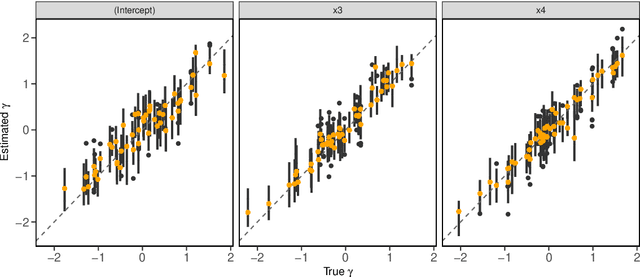
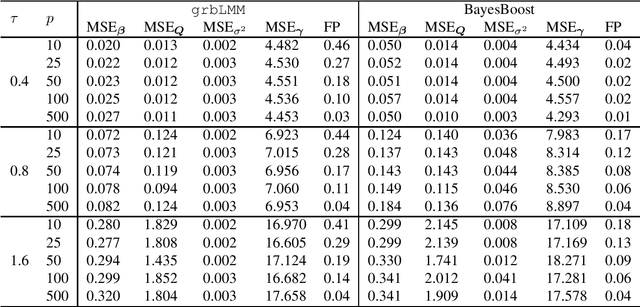
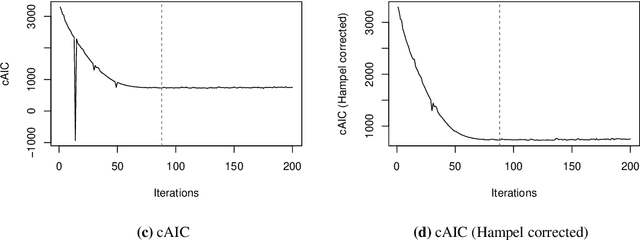
Boosting methods are widely used in statistical learning to deal with high-dimensional data due to their variable selection feature. However, those methods lack straightforward ways to construct estimators for the precision of the parameters such as variance or confidence interval, which can be achieved by conventional statistical methods like Bayesian inference. In this paper, we propose a new inference method "BayesBoost" that combines boosting and Bayesian for linear mixed models to make the uncertainty estimation for the random effects possible on the one hand. On the other hand, the new method overcomes the shortcomings of Bayesian inference in giving precise and unambiguous guidelines for the selection of covariates by benefiting from boosting techniques. The implementation of Bayesian inference leads to the randomness of model selection criteria like the conditional AIC (cAIC), so we also propose a cAIC-based model selection criteria that focus on the stabilized regions instead of the global minimum. The effectiveness of the new approach can be observed via simulation and in a data example from the field of neurophysiology focussing on the mechanisms in the brain while listening to unpleasant sounds.