 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-World Adversarial Attacks on RF-Based Drone Detectors
Dec 23, 2025Radio frequency (RF) based systems are increasingly used to detect drones by analyzing their RF signal patterns, converting them into spectrogram images which are processed by object detection models. Existing RF attacks against image based models alter digital features, making over-the-air (OTA) implementation difficult due to the challenge of converting digital perturbations to transmittable waveforms that may introduce synchronization errors and interference, and encounter hardware limitations. We present the first physical attack on RF image based drone detectors, optimizing class-specific universal complex baseband (I/Q) perturbation waveforms that are transmitted alongside legitimate communications. We evaluated the attack using RF recordings and OTA experiments with four types of drones. Our results show that modest, structured I/Q perturbations are compatible with standard RF chains and reliably reduce target drone detection while preserving detection of legitimate drones.
Addressing Key Challenges of Adversarial Attacks and Defenses in the Tabular Domain: A Methodological Framework for Coherence and Consistency
Dec 10, 2024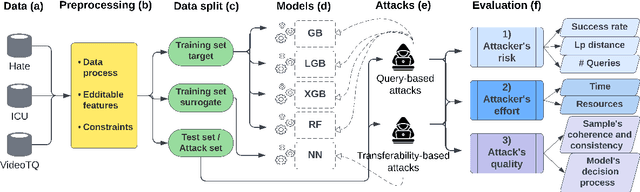



Machine learning models trained on tabular data are vulnerable to adversarial attacks, even in realistic scenarios where attackers have access only to the model's outputs. Researchers evaluate such attacks by considering metrics like success rate, perturbation magnitude, and query count. However, unlike other data domains, the tabular domain contains complex interdependencies among features, presenting a unique aspect that should be evaluated: the need for the attack to generate coherent samples and ensure feature consistency for indistinguishability. Currently, there is no established methodology for evaluating adversarial samples based on these criteria. In this paper, we address this gap by proposing new evaluation criteria tailored for tabular attacks' quality; we defined anomaly-based framework to assess the distinguishability of adversarial samples and utilize the SHAP explainability technique to identify inconsistencies in the model's decision-making process caused by adversarial samples. These criteria could form the basis for potential detection methods and be integrated into established evaluation metrics for assessing attack's quality Additionally, we introduce a novel technique for perturbing dependent features while maintaining coherence and feature consistency within the sample. We compare different attacks' strategies, examining black-box query-based attacks and transferability-based gradient attacks across four target models. Our experiments, conducted on benchmark tabular datasets, reveal significant differences between the examined attacks' strategies in terms of the attacker's risk and effort and the attacks' quality. The findings provide valuable insights on the strengths, limitations, and trade-offs of various adversarial attacks in the tabular domain, laying a foundation for future research on attacks and defense development.