 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Collaborate: An Orchestrated-Decentralized Framework for Peer-to-Peer LLM Federation
Jan 23, 2026Fine-tuning Large Language Models (LLMs) for specialized domains is constrained by a fundamental challenge: the need for diverse, cross-organizational data conflicts with the principles of data privacy and sovereignty. While Federated Learning (FL) provides a framework for collaboration without raw data exchange, its classic centralized form introduces a single point of failure and remains vulnerable to model inversion attacks. Decentralized FL (DFL) mitigates this risk by removing the central aggregator but typically relies on inefficient, random peer-to-peer (P2P) pairings, forming a collaboration graph that is blind to agent heterogeneity and risks negative transfer. This paper introduces KNEXA-FL, a novel framework for orchestrated decentralization that resolves this trade-off. KNEXA-FL employs a non-aggregating Central Profiler/Matchmaker (CPM) that formulates P2P collaboration as a contextual bandit problem, using a LinUCB algorithm on abstract agent profiles to learn an optimal matchmaking policy. It orchestrates direct knowledge exchange between heterogeneous, PEFT-based LLM agents via secure distillation, without ever accessing the models themselves. Our comprehensive experiments on a challenging code generation task show that KNEXA-FL yields substantial gains, improving Pass@1 by approx. 50% relative to random P2P collaboration. Critically, our orchestrated approach demonstrates stable convergence, in stark contrast to a powerful centralized distillation baseline which suffers from catastrophic performance collapse. Our work establishes adaptive, learning-based orchestration as a foundational principle for building robust and effective decentralized AI ecosystems.
DIESEL -- Dynamic Inference-Guidance via Evasion of Semantic Embeddings in LLMs
Nov 28, 2024In recent years, conversational large language models (LLMs) have shown tremendous success in tasks such as casual conversation, question answering, and personalized dialogue, making significant advancements in domains like virtual assistance, social interaction, and online customer engagement. However, they often generate responses that are not aligned with human values (e.g., ethical standards, safety, or social norms), leading to potentially unsafe or inappropriate outputs. While several techniques have been proposed to address this problem, they come with a cost, requiring computationally expensive training or dramatically increasing the inference time. In this paper, we present DIESEL, a lightweight inference guidance technique that can be seamlessly integrated into any autoregressive LLM to semantically filter undesired concepts from the response. DIESEL can function either as a standalone safeguard or as an additional layer of defense, enhancing response safety by reranking the LLM's proposed tokens based on their similarity to predefined negative concepts in the latent space. This approach provides an efficient and effective solution for maintaining alignment with human values. Our evaluation demonstrates DIESEL's effectiveness on state-of-the-art conversational models (e.g., Llama 3), even in challenging jailbreaking scenarios that test the limits of response safety. We further show that DIESEL can be generalized to use cases other than safety, providing a versatile solution for general-purpose response filtering with minimal computational overhead.
Insights and Current Gaps in Open-Source LLM Vulnerability Scanners: A Comparative Analysis
Oct 21, 2024



This report presents a comparative analysis of open-source vulnerability scanners for conversational large language models (LLMs). As LLMs become integral to various applications, they also present potential attack surfaces, exposed to security risks such as information leakage and jailbreak attacks. Our study evaluates prominent scanners - Garak, Giskard, PyRIT, and CyberSecEval - that adapt red-teaming practices to expose these vulnerabilities. We detail the distinctive features and practical use of these scanners, outline unifying principles of their design and perform quantitative evaluations to compare them. These evaluations uncover significant reliability issues in detecting successful attacks, highlighting a fundamental gap for future development. Additionally, we contribute a preliminary labelled dataset, which serves as an initial step to bridge this gap. Based on the above, we provide strategic recommendations to assist organizations choose the most suitable scanner for their red-teaming needs, accounting for customizability, test suite comprehensiveness, and industry-specific use cases.
Knowledge Distillation-Empowered Digital Twin for Anomaly Detection
Sep 12, 2023



Cyber-physical systems (CPSs), like train control and management systems (TCMS), are becoming ubiquitous in critical infrastructures. As safety-critical systems, ensuring their dependability during operation is crucial. Digital twins (DTs) have been increasingly studied for this purpose owing to their capability of runtime monitoring and warning, prediction and detection of anomalies, etc. However, constructing a DT for anomaly detection in TCMS necessitates sufficient training data and extracting both chronological and context features with high quality. Hence, in this paper, we propose a novel method named KDDT for TCMS anomaly detection. KDDT harnesses a language model (LM) and a long short-term memory (LSTM) network to extract contexts and chronological features, respectively. To enrich data volume, KDDT benefits from out-of-domain data with knowledge distillation (KD). We evaluated KDDT with two datasets from our industry partner Alstom and obtained the F1 scores of 0.931 and 0.915, respectively, demonstrating the effectiveness of KDDT. We also explored individual contributions of the DT model, LM, and KD to the overall performance of KDDT, via a comprehensive empirical study, and observed average F1 score improvements of 12.4%, 3%, and 6.05%, respectively.
Simultaneous Adversarial Attacks On Multiple Face Recognition System Components
Apr 11, 2023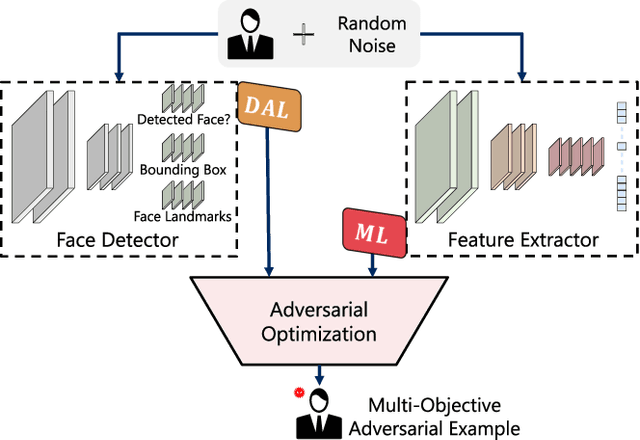

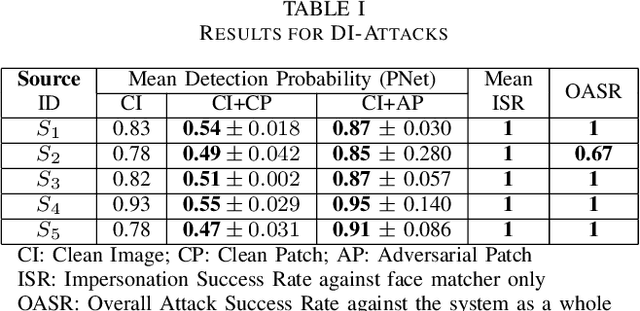
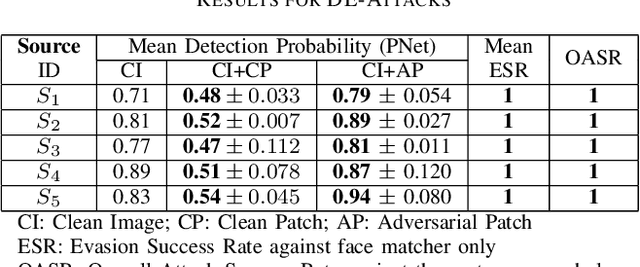
In this work, we investigate the potential threat of adversarial examples to the security of face recognition systems. Although previous research has explored the adversarial risk to individual components of FRSs, our study presents an initial exploration of an adversary simultaneously fooling multiple components: the face detector and feature extractor in an FRS pipeline. We propose three multi-objective attacks on FRSs and demonstrate their effectiveness through a preliminary experimental analysis on a target system. Our attacks achieved up to 100% Attack Success Rates against both the face detector and feature extractor and were able to manipulate the face detection probability by up to 50% depending on the adversarial objective. This research identifies and examines novel attack vectors against FRSs and suggests possible ways to augment the robustness by leveraging the attack vector's knowledge during training of an FRS's components.
Advancing Deep Metric Learning Through Multiple Batch Norms And Multi-Targeted Adversarial Examples
Dec 06, 2022Deep Metric Learning (DML) is a prominent field in machine learning with extensive practical applications that concentrate on learning visual similarities. It is known that inputs such as Adversarial Examples (AXs), which follow a distribution different from that of clean data, result in false predictions from DML systems. This paper proposes MDProp, a framework to simultaneously improve the performance of DML models on clean data and inputs following multiple distributions. MDProp utilizes multi-distribution data through an AX generation process while leveraging disentangled learning through multiple batch normalization layers during the training of a DML model. MDProp is the first to generate feature space multi-targeted AXs to perform targeted regularization on the training model's denser embedding space regions, resulting in improved embedding space densities contributing to the improved generalization in the trained models. From a comprehensive experimental analysis, we show that MDProp results in up to 2.95% increased clean data Recall@1 scores and up to 2.12 times increased robustness against different input distributions compared to the conventional methods.
Powerful Physical Adversarial Examples Against Practical Face Recognition Systems
Mar 23, 2022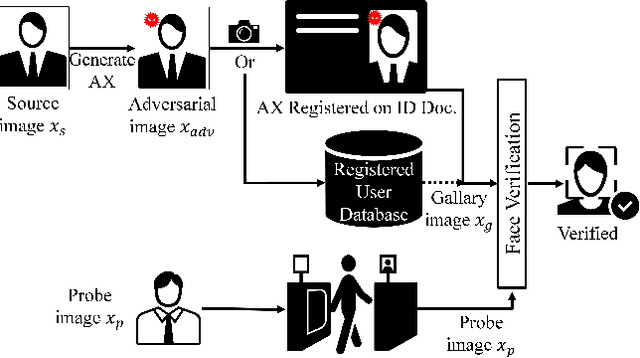
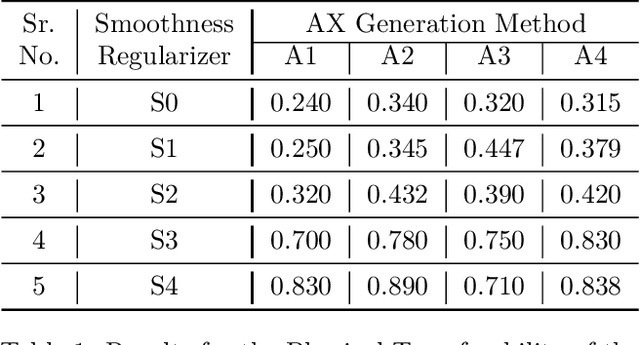
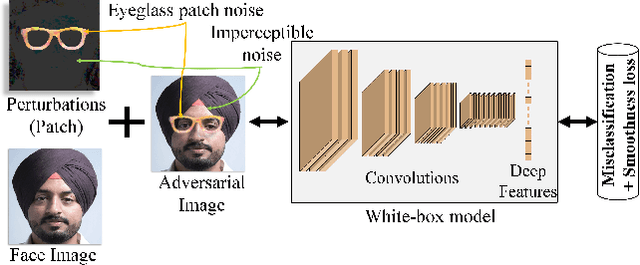
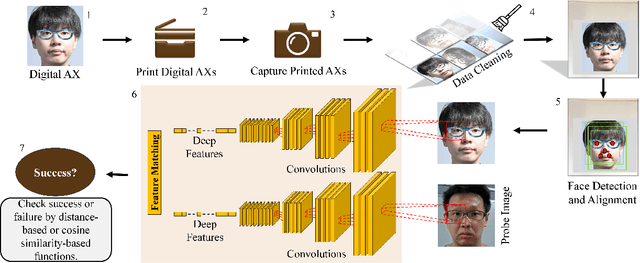
It is well-known that the most existing machine learning (ML)-based safety-critical applications are vulnerable to carefully crafted input instances called adversarial examples (AXs). An adversary can conveniently attack these target systems from digital as well as physical worlds. This paper aims to the generation of robust physical AXs against face recognition systems. We present a novel smoothness loss function and a patch-noise combo attack for realizing powerful physical AXs. The smoothness loss interjects the concept of delayed constraints during the attack generation process, thereby causing better handling of optimization complexity and smoother AXs for the physical domain. The patch-noise combo attack combines patch noise and imperceptibly small noises from different distributions to generate powerful registration-based physical AXs. An extensive experimental analysis found that our smoothness loss results in robust and more transferable digital and physical AXs than the conventional techniques. Notably, our smoothness loss results in a 1.17 and 1.97 times better mean attack success rate (ASR) in physical white-box and black-box attacks, respectively. Our patch-noise combo attack furthers the performance gains and results in 2.39 and 4.74 times higher mean ASR than conventional technique in physical world white-box and black-box attacks, respectively.
Anomaly Detection using Capsule Networks for High-dimensional Datasets
Dec 28, 2021



Anomaly detection is an essential problem in machine learning. Application areas include network security, health care, fraud detection, etc., involving high-dimensional datasets. A typical anomaly detection system always faces the class-imbalance problem in the form of a vast difference in the sample sizes of different classes. They usually have class overlap problems. This study used a capsule network for the anomaly detection task. To the best of our knowledge, this is the first instance where a capsule network is analyzed for the anomaly detection task in a high-dimensional complex data setting. We also handle the related novelty and outlier detection problems. The architecture of the capsule network was suitably modified for a binary classification task. Capsule networks offer a good option for detecting anomalies due to the effect of viewpoint invariance captured in its predictions and viewpoint equivariance captured in internal capsule architecture. We used six-layered under-complete autoencoder architecture with second and third layers containing capsules. The capsules were trained using the dynamic routing algorithm. We created $10$-imbalanced datasets from the original MNIST dataset and compared the performance of the capsule network with $5$ baseline models. Our leading test set measures are F1-score for minority class and area under the ROC curve. We found that the capsule network outperformed every other baseline model on the anomaly detection task by using only ten epochs for training and without using any other data level and algorithm level approach. Thus, we conclude that capsule networks are excellent in modeling complex high-dimensional imbalanced datasets for the anomaly detection task.
On Brightness Agnostic Adversarial Examples Against Face Recognition Systems
Sep 29, 2021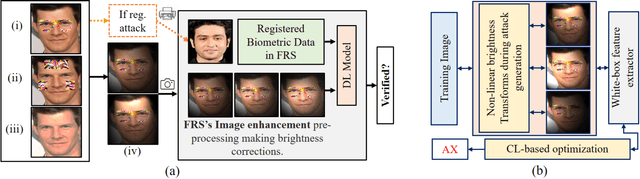
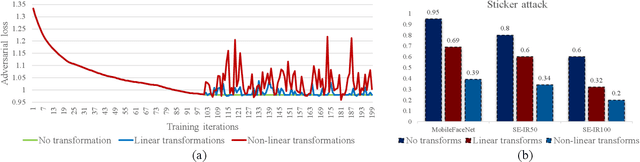
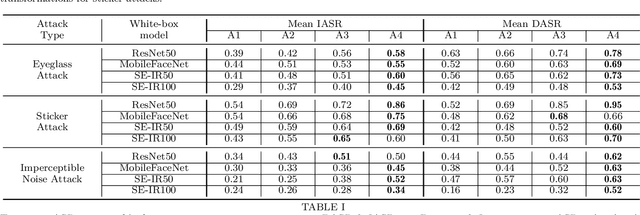
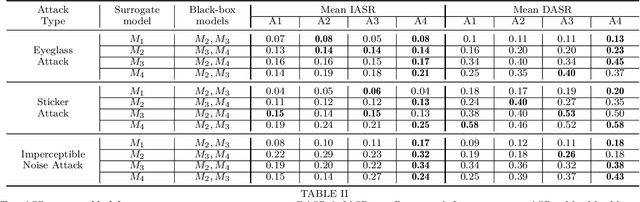
This paper introduces a novel adversarial example generation method against face recognition systems (FRSs). An adversarial example (AX) is an image with deliberately crafted noise to cause incorrect predictions by a target system. The AXs generated from our method remain robust under real-world brightness changes. Our method performs non-linear brightness transformations while leveraging the concept of curriculum learning during the attack generation procedure. We demonstrate that our method outperforms conventional techniques from comprehensive experimental investigations in the digital and physical world. Furthermore, this method enables practical risk assessment of FRSs against brightness agnostic AXs.
* Accepted at BIOSIG 2021 conference
Dodging Attack Using Carefully Crafted Natural Makeup
Sep 14, 2021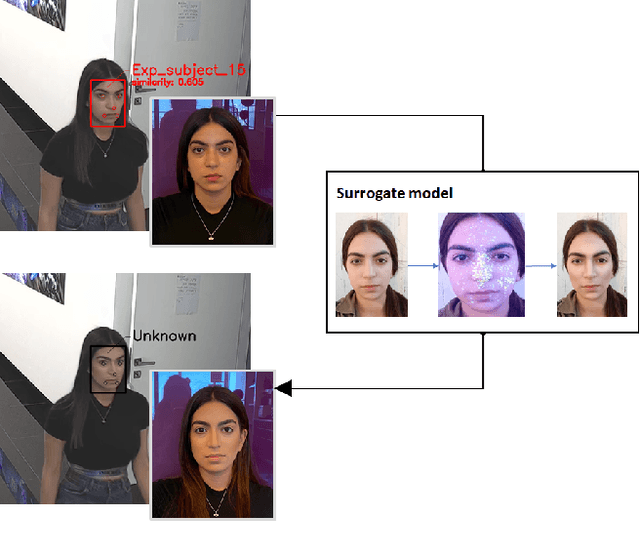

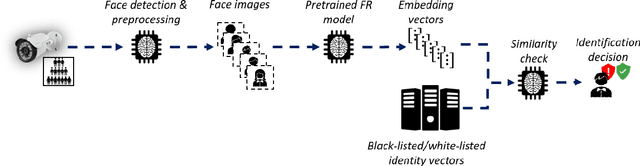
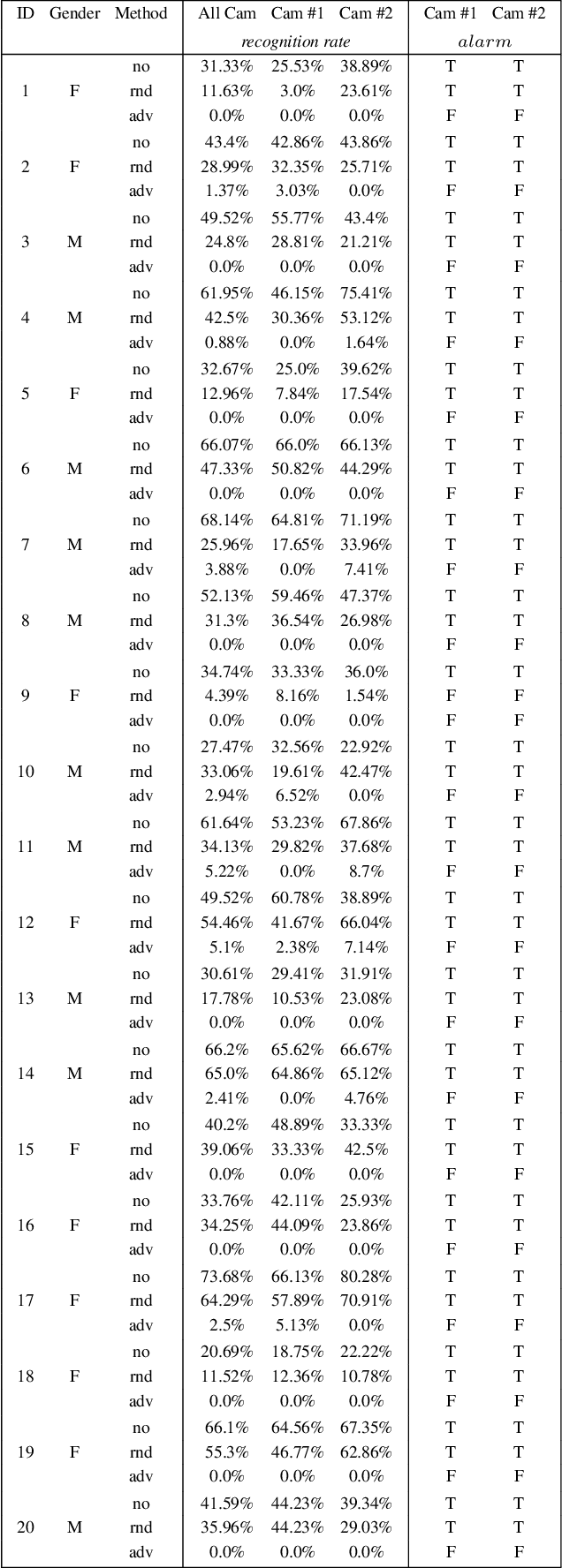
Deep learning face recognition models are used by state-of-the-art surveillance systems to identify individuals passing through public areas (e.g., airports). Previous studies have demonstrated the use of adversarial machine learning (AML) attacks to successfully evade identification by such systems, both in the digital and physical domains. Attacks in the physical domain, however, require significant manipulation to the human participant's face, which can raise suspicion by human observers (e.g. airport security officers). In this study, we present a novel black-box AML attack which carefully crafts natural makeup, which, when applied on a human participant, prevents the participant from being identified by facial recognition models. We evaluated our proposed attack against the ArcFace face recognition model, with 20 participants in a real-world setup that includes two cameras, different shooting angles, and different lighting conditions. The evaluation results show that in the digital domain, the face recognition system was unable to identify all of the participants, while in the physical domain, the face recognition system was able to identify the participants in only 1.22% of the frames (compared to 47.57% without makeup and 33.73% with random natural makeup), which is below a reasonable threshold of a realistic operational environment.